chatGPTベースのchatbotの専用品質検証ツール「GPT・BOTチェッカー(https://aiberry.xyz/gptbotchecker/」をアイベリー株式会社がリリース。
GTP・BOTチェッカーはchatGPTベースのchatbot専用の検証ツール。chatGPTが品質を分析します。大量のテストと統計的分析で検証・改善を行いchatbotの開発工程を改善します。
ChatGPTベースのチャットボットは、一つの質問に対して様々な回答を生成します。そのため、その品質を確認するためには大量の質問と回答を試行する必要があり、それが大きな課題となっていました。「GPT・BOTチェッカー」は、この問題を解決します。大量の質問と回答をchatGPTが自動で実行し、その結果を統計的に分析します。
この工程は、工業製品の不良品発生率を分析する方法と同じ考え方に基づいています。統計学的な手法、特に標準偏差を使用することで、チャットボットの回答改善方向性を明示し、その改善を迅速に進めることを目指しています。

<chatGPTベースのchatbot検証時の課題と解決策について>
chatGPTをベースにしたchatbotは様々な用途で活用されており、その品質チェックは手作業で行われることが一般的です。しかし、chatGPTの回答は揺らぎを含むため、同一の質問でも異なる回答が生成され、それら全てのバリエーションを想定しての改善は困難です。
重要なことは、chatGPTが「明らかに間違った回答」をしないようにすることです。それを達成するには、「誤った回答」を出現させるための大量の試行と、それに基づくプロンプトの改善が必要となります。しかし、この大規模な試行を手作業で行うのは難しく、時間もコストも膨大になります。
GPT・BOTチェッカーは、chatGPTに質問・回答の大量試行を行わせます。
試行の過程でchatGPT自身が回答内容の品質を評価し、その品質を事前に設定した評価表を基に点数化します。これにより、chatGPTが生成した各回答の品質を具体的な数値で評価し、「明らかに間違った回答」を特定できます。これらの「間違った回答」はプロンプトの改善に活かされ、この方法によるテストは品質チェックの労力を大幅に削減し、全体の開発工程を短縮することが可能になります。
<「GPT・BOTチェッカー」の内容>
ChatGPTがchatbotの品質を解析するチェックツールです。
多くの回答テストを試行し、回答を分析し、統計的な考え方から不良回答を無くします。
特徴-1: chatGPTによる大規模な回答チェック
chatGPTを基にしたchatbotは、「揺らぎ」の特性を持っています。これは、同一の質問に対しても異なる回答を生成する性質を指します。そのため、チャットボットの品質を綿密に検証するには大量のテスト試行が必要となります。
この大量の試行を通じて、一定の確率で発生する低品質な回答を見つけ出し、それに基づいてプロンプトの改善を行います。
具体的な試行回数については以下の通り推奨します: ●一つの質問に対する試行回数:最低100回 ●試行するべき異なる質問の種類:最低100種(1ページの対話内容に対して最低10種類の質問)
これらを組み合わせると、概ね「100種類の質問×100回の試行=合計10,000回のテスト」となります。これほどの試行回数を推奨する理由は、品質の低い回答を十分に捉え、適切に改善するためです。
※GPT・BOTチェッカーの質問回答の集計表のサンプル
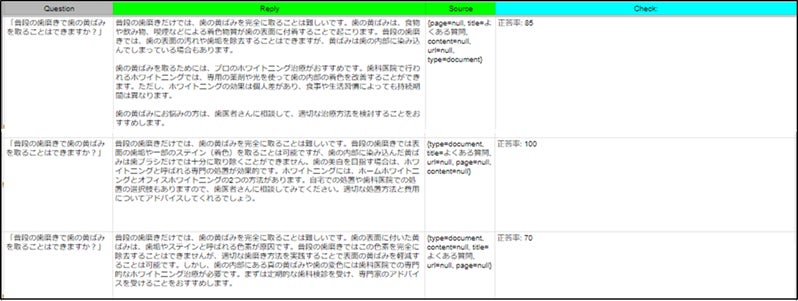
2-回答の品質を数値化
一般的な回答のチェックはテーマに合わせた質問集を作成し、その回答を担当者がチェックし、誤った回答でないかを検討することが多いと思います。
これはいわば、回答を検証するのに「担当者の主観や知識」をたよりに無作為抽出的に質問・回答をチェックしていることだと思います。
そもそも人力では大量の回答の品質チェックは困難です。
そこで私たちが開発したGPT・BOTチェッカーでは、異なるアプローチを取っています。それは、回答の品質を数値化することです。我々はそのための評価ガイドラインを設け、このガイドラインをchatGPTに学習させて、回答の評価を行います。これにより、人間の介入を最小限にし、より正確かつ効率的に回答の品質を判断することが可能になります。
※正答度の数値化のガイドライン
目指すべき目標=スコア70以下の回答ゼロ(=確率的に無視できる状態)

3-統計的に処理
私たちは工業生産品の不良品発生率のように、「ChatGPTを基盤としたchatbot」の不良回答率も統計的に扱います。
結論としては、我々は先述の「正答度合いの数値化ガイドライン」に基づき、次の数値を目指します:
目標とする回答品質 平均90・標準偏差σ4.0程度
これにより、全ての回答の99.7%が78点以上、95%以上が82点以上の品質となることを目指します。
以下の標準偏差のグラフ説明図を参考に理解いただければ幸いです。
※標準偏差の分布図

※σ(シグマ)は標準偏差を表します。
標準偏差は統計学の考え方です。
標準偏差は試行結果のスコアのバラツキを表し、正規分布に準じるものはこのバラツキに収まります。
平均から標準偏差の上下1倍のスコアの中に全体の68%が収まる。
平均から標準偏差の上下2倍のスコアの中に全体の95%が収まる。
平均から標準偏差の上下2倍のスコアの中に全体の99.7%が収まる。
※「GPT・BOTチェッカー」で分析した事例サンプル
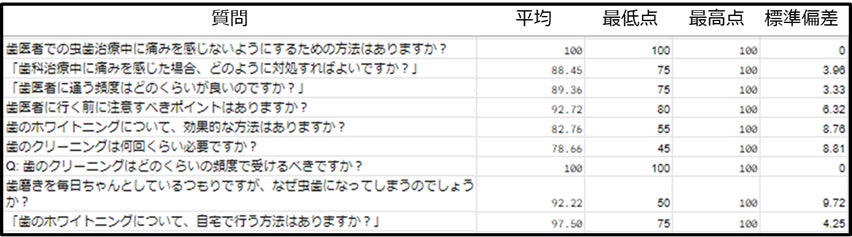
※参考
米国の医療機関でGoogle社が開発したchatbotの品質評価に関する記事に基づく情報(出典: ZDNet Japan)(https://japan.zdnet.com/article/35206858/)
以下は、記事の要約の一部です。医師の質問への回答に対する平均スコアが92.9%で、一方でGoogleが開発したAI「Med-PaLM」は92.6%のスコアを記録しています。このスコアがどのような基準で算出されたのかは明らかではありませんが、参考として価値があると考えられます。
記事の要点: GoogleのAI部門であるDeepMindの論文が、権威ある学術誌「Nature」に掲載されました。その内容によれば:
人間の臨床医による質問への回答の平均スコア:92.9%
Googleが開発したAI「Med-PaLM」のスコア:92.6%
Googleの別のAIモデル「PaLM」の派生版のスコア:61.9%
以上の情報を考慮に入れると、「回答品質 平均90・標準偏差σ4.0程度」であれば医師と同等レベルの回答ができていると考えていもいいのではないでしょうか。
価格設定
■初回テスト料金
100質問の生成×100回の質問試行=1万回試行テスト=60,000円(税別)
■追加テスト料金
1問×100回の質問試行=100回試行テスト=10,000円(税別)
■最終テスト料金
100質問の生成×100回の質問試行=1万回試行テスト=30,000円(税別)
※追加テスト、最終テストの料金はchatGPTの添付資料に変更がないことが前提です。
※価格設定はリリースキャンペーン時のもので、予告なく変更する場合があります。
本件のwebサイト・お問合せ
webサイト(https://aiberry.xyz/gptbotchecker/)
お問合せページ(https://bit.ly/3KhuP04)
■本件に関するお問合せ先
開発・提供)
アイベリー株式会社 担当 村田
電話 050-3204-1420
メールアドレス info@aiberry.xyz
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像