オープンソースのデータ収集基盤ソフトウエアの活用を推進し、Hadoopソリューションを拡充
~NTTデータとトレジャーデータ社が連携し、「Fluentd/Embulkサポートサービス」の提供を開始~
株式会社NTTデータ(以下、NTTデータ)は、Fluentd(フルエントディ)、Embulk(エンバルク)の開発元であるトレジャーデータ株式会社(以下、トレジャーデータ)と連携することで、2016年6月21日からHadoopサポートサービスを拡充し、オープンソースのデータ収集基盤ソフトウエアである「Fluentd/Embulkサポートサービス」を開始します。
本サービスを利用することで、大量データや、複数のシステムに存在するデータの収集が容易となります。
NTTデータとトレジャーデータは、FluentdおよびEmbulkの活用を推進し、開発コミュニティと連携して品質向上と高度化を進めることで、データ活用を進めるお客さまに対し、より安心して便利に使えるシステムを提供できるよう貢献していきます。
本サービスを利用することで、大量データや、複数のシステムに存在するデータの収集が容易となります。
NTTデータとトレジャーデータは、FluentdおよびEmbulkの活用を推進し、開発コミュニティと連携して品質向上と高度化を進めることで、データ活用を進めるお客さまに対し、より安心して便利に使えるシステムを提供できるよう貢献していきます。
【これまでの取り組み】
NTTデータでは、2010年より大量データの蓄積や処理を、オープンソースの並列分散処理基盤であるHadoopを活用する導入コンサルから、構築・運用、サポートまでトータルに手がける「Hadoop構築・運用ソリューション」をお客さまに提供してきました。2015年からは、これまで提供してきたHadoopに加えて、機械学習処理・グラフ処理・ストリーム処理を同一のプラットフォームで実現できる新たなオープンソースの並列分散処理基盤であるSparkを活用する「Hadoop/Spark構築・運用ソリューション」を提供してきました。また、オープンソースコミュニティ主導の下で開発されるHadoop/Sparkプロジェクトにおいて、2014年度から2015年度にかけて鯵坂明がHadoop、岩崎正剛がHadoopおよびHTrace(注1)、猿田浩輔がSpark、関堅吾がYetus(注2)のコミッター(注3)に選出され、コミュニティと協力しながら継続的なソフトウエアの改善を行っています。
一方トレジャーデータは、ビッグデータを一定の月額課金で収集・保管・分析するクラウド型データマネジメントサービス「トレジャーデータサービス」を提供しており、その中でさまざまなデータを柔軟に収集する基盤ソフトウエアとしてFluentdとEmbulkを開発しました。Fluentdはデータをストリーム転送するソフトウエア、Embulkはバッチ転送するソフトウエアであり、ともにトレジャーデータの創業者の一人である古橋貞之が開発し、オープンソースソフトウエアとして公開しました。これらのソフトウエアは現在、オープンソースコミュニティの下で機能追加や維持管理が行われています。
【背景】
昨今、データ活用の取り組みが広まるにつれ、収集するデータ量の増大への対応や、複数のシステムやデータソースに存在する多種多様なデータを、柔軟かつ確実に収集する機能の実現が重要な課題となっています。
Fluentd、Embulkは、このようなデータ収集時の課題を解決するオープンソースソフトウエアであり、Webのアクセスログやシステムログ、SNS等のデータを活用する企業で導入が進んでいます。
【概要(特長)】
NTTデータはデータ収集時の課題を解決するために、トレジャーデータと連携して、「Fluentd/Embulkサポートサービス」を提供します。本サービスは、データ収集基盤ミドルウエアであるFluentd、Embulkを活用するシステムの設計・開発フェーズ、ならびに運用・保守フェーズにおいて、インストールや設定方法、ソフトウエア仕様の確認だけでなく、不具合の解析や回避策の提示まで行うサポートサービスです。両社が連携することにより、ソースコードレベルの迅速な解析や、Hadoopと組み合わせて使用する際の運用やチューニング等、お客さまのニーズを反映した高度かつ高品質なサポートを提供します。また、お客さまは本サービスを利用することにより、データ収集基盤ミドルウエアとしてFluentdおよびEmbulkを安心して導入できるようになります。
(NTTデータ)
NTTデータは、「Fluentd/Embulkサポートサービス」を、「Hadoop/Spark構築・運用ソリューション」の一部である「Hadoop/Sparkサポートサービス」のオプションとして提供します。また、FluentdおよびEmbulkをシステムに導入し、導入後のソフトウエアに関してお客さまからの問い合わせを受け付け、調査と回答を行います。
(トレジャーデータ)
トレジャーデータは調査に際し、ソースコードレベルでの解析に基づく不具合の回避策の提示を行い、必要に応じてパッチの作成を行うなど、NTTデータが提示する解決策の支援を行います。
【今後について】
NTTデータは、数あるオープンソースソフトウエアの導入実績を踏まえた機能面・非機能面の改善要望や、本取り組みを通じて得られた知見を、FluentdおよびEmbulkのオープンソースコミュニティにフィードバックします。また、トレジャーデータはコミュニティでの開発を通じてFluentdおよびEmbulkの機能拡充に努めます。
NTTデータとトレジャーデータは、FluentdおよびEmbulkの活用を推進し、開発コミュテニティと連携して品質向上と高度化を進めることで、データ活用を進めるお客さまに対し、より安心して便利に使えるシステムを提供できるよう貢献していきます。
【参考】
トレジャーデータについて
2011年12月、米国シリコンバレーに設立された米国トレジャーデータ社は、ビッグデータを一定の月額課金で収集・保管・分析するクラウド型データマネジメントサービス(DMS)「トレジャーデータサービス」を提供しています。同社のサービスは、大容量の購買取引データ、Web閲覧データ、各種のアプリケーションやモバイル端末のログデータ、センサーデータやマシンデータ等、さまざまな非構造化データに対応しています。顧客は、フォーチュン誌が選ぶ世界企業番付「フォーチュン・グローバル500」の企業も含まれています。日本では、2012年11月にトレジャーデータ株式会社を設立し、日本国内の事業開発および技術開発の拠点となっています。
*文中の商品名、会社名、団体名は、各社の商標または登録商標です。
(注1)並列分散処理のトレーシング機能を開発するプロジェクト。(http://htrace.incubator.apache.org/)
(注2)Hadoopのテストフレームワークを開発するプロジェクト。(https://yetus.apache.org/)
(注3)オープンソースソフトウエアの開発やメンテナンスにおいて、プログラムを書き換える権限(コミット権)を持つ主要開発者。
NTTデータでは、2010年より大量データの蓄積や処理を、オープンソースの並列分散処理基盤であるHadoopを活用する導入コンサルから、構築・運用、サポートまでトータルに手がける「Hadoop構築・運用ソリューション」をお客さまに提供してきました。2015年からは、これまで提供してきたHadoopに加えて、機械学習処理・グラフ処理・ストリーム処理を同一のプラットフォームで実現できる新たなオープンソースの並列分散処理基盤であるSparkを活用する「Hadoop/Spark構築・運用ソリューション」を提供してきました。また、オープンソースコミュニティ主導の下で開発されるHadoop/Sparkプロジェクトにおいて、2014年度から2015年度にかけて鯵坂明がHadoop、岩崎正剛がHadoopおよびHTrace(注1)、猿田浩輔がSpark、関堅吾がYetus(注2)のコミッター(注3)に選出され、コミュニティと協力しながら継続的なソフトウエアの改善を行っています。
一方トレジャーデータは、ビッグデータを一定の月額課金で収集・保管・分析するクラウド型データマネジメントサービス「トレジャーデータサービス」を提供しており、その中でさまざまなデータを柔軟に収集する基盤ソフトウエアとしてFluentdとEmbulkを開発しました。Fluentdはデータをストリーム転送するソフトウエア、Embulkはバッチ転送するソフトウエアであり、ともにトレジャーデータの創業者の一人である古橋貞之が開発し、オープンソースソフトウエアとして公開しました。これらのソフトウエアは現在、オープンソースコミュニティの下で機能追加や維持管理が行われています。
【背景】
昨今、データ活用の取り組みが広まるにつれ、収集するデータ量の増大への対応や、複数のシステムやデータソースに存在する多種多様なデータを、柔軟かつ確実に収集する機能の実現が重要な課題となっています。
Fluentd、Embulkは、このようなデータ収集時の課題を解決するオープンソースソフトウエアであり、Webのアクセスログやシステムログ、SNS等のデータを活用する企業で導入が進んでいます。
【概要(特長)】
NTTデータはデータ収集時の課題を解決するために、トレジャーデータと連携して、「Fluentd/Embulkサポートサービス」を提供します。本サービスは、データ収集基盤ミドルウエアであるFluentd、Embulkを活用するシステムの設計・開発フェーズ、ならびに運用・保守フェーズにおいて、インストールや設定方法、ソフトウエア仕様の確認だけでなく、不具合の解析や回避策の提示まで行うサポートサービスです。両社が連携することにより、ソースコードレベルの迅速な解析や、Hadoopと組み合わせて使用する際の運用やチューニング等、お客さまのニーズを反映した高度かつ高品質なサポートを提供します。また、お客さまは本サービスを利用することにより、データ収集基盤ミドルウエアとしてFluentdおよびEmbulkを安心して導入できるようになります。
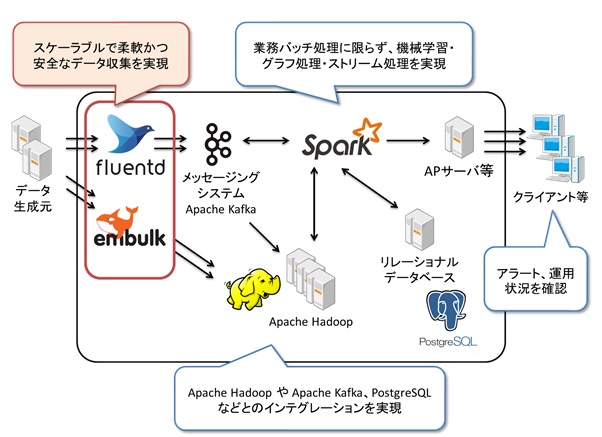 図:Fluentd、Embulkを利用したデータ活用基盤の実現
図:Fluentd、Embulkを利用したデータ活用基盤の実現
【役割分担】
(NTTデータ)
NTTデータは、「Fluentd/Embulkサポートサービス」を、「Hadoop/Spark構築・運用ソリューション」の一部である「Hadoop/Sparkサポートサービス」のオプションとして提供します。また、FluentdおよびEmbulkをシステムに導入し、導入後のソフトウエアに関してお客さまからの問い合わせを受け付け、調査と回答を行います。
(トレジャーデータ)
トレジャーデータは調査に際し、ソースコードレベルでの解析に基づく不具合の回避策の提示を行い、必要に応じてパッチの作成を行うなど、NTTデータが提示する解決策の支援を行います。
【今後について】
NTTデータは、数あるオープンソースソフトウエアの導入実績を踏まえた機能面・非機能面の改善要望や、本取り組みを通じて得られた知見を、FluentdおよびEmbulkのオープンソースコミュニティにフィードバックします。また、トレジャーデータはコミュニティでの開発を通じてFluentdおよびEmbulkの機能拡充に努めます。
NTTデータとトレジャーデータは、FluentdおよびEmbulkの活用を推進し、開発コミュテニティと連携して品質向上と高度化を進めることで、データ活用を進めるお客さまに対し、より安心して便利に使えるシステムを提供できるよう貢献していきます。
【参考】
トレジャーデータについて
2011年12月、米国シリコンバレーに設立された米国トレジャーデータ社は、ビッグデータを一定の月額課金で収集・保管・分析するクラウド型データマネジメントサービス(DMS)「トレジャーデータサービス」を提供しています。同社のサービスは、大容量の購買取引データ、Web閲覧データ、各種のアプリケーションやモバイル端末のログデータ、センサーデータやマシンデータ等、さまざまな非構造化データに対応しています。顧客は、フォーチュン誌が選ぶ世界企業番付「フォーチュン・グローバル500」の企業も含まれています。日本では、2012年11月にトレジャーデータ株式会社を設立し、日本国内の事業開発および技術開発の拠点となっています。
*文中の商品名、会社名、団体名は、各社の商標または登録商標です。
(注1)並列分散処理のトレーシング機能を開発するプロジェクト。(http://htrace.incubator.apache.org/)
(注2)Hadoopのテストフレームワークを開発するプロジェクト。(https://yetus.apache.org/)
(注3)オープンソースソフトウエアの開発やメンテナンスにおいて、プログラムを書き換える権限(コミット権)を持つ主要開発者。
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザーログイン既に登録済みの方はこちら
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像