renue、生成AIが定期実行ジョブを自律監視する統合モニタリングシステムを開発
障害検知から原因分析・自動復旧までをAIエージェントが支援
開発背景
ジョブ増加と運用負荷の深刻化
企業のDX推進に伴い、業務を支えるバックグラウンドジョブの数と種類は急速に増加しています。renueにおいても、Azure,AWS,GC上で数十種類のバッチジョブが日々稼働しています。
-
財務データの自動同期
-
採用プラットフォームからの候補者情報取得
-
プレスリリース収集、議事録の自動生成処理
-
マーケティングデータの集計・キャンペーン自動実行
-
ECプラットフォームの在庫・注文データ同期、広告レポート自動取得
これらのジョブはそれぞれ固有のスケジュール・依存関係・エラー特性を持ち、一つでも停止すればデータ欠損や業務遅延に直結します。
従来の監視手法の限界
従来はSlackへのエラー通知に依存していましたが、ジョブ増加に伴い以下の課題が深刻化していました。
-
通知の洪水:1ジョブのエラー連続で数十件の通知がSlackに投稿され、他の重要通知が埋没
-
サイレント・フェイラー:プロセスが予期しない形で終了すると通知が発火せず、数日間気づかないケースも発生
-
原因特定の属人化:ログ確認・スタックトレース追跡・外部API切り分けに30分〜数時間を要し、ジュニアにはさらに困難
-
復旧対応の遅延:深夜・休日の障害は手動対応のため翌営業日まで放置されるリスク
社内エンジニアからも「ジョブを増やしすぎて死活監視がかなり辛い」「新しいジョブを追加するたびに監視設定を手動で追加するのは非効率的」という声が上がっており、根本的な監視体制の刷新が急務となっていました。
設計の基本方針
こうした背景から、以下の3つを基本方針として本システムを設計しました。
-
監視のための監視に時間を取られないこと
-
ジョブ追加時に監視設定を個別に行う必要がないこと(ゼロコンフィグ)
-
障害の検知から復旧までの一連のプロセスを可能な限り自動化すること
システム全体像
本システムは4つの機能で構成されます。統合ダッシュボードでジョブ状態を一元管理し、障害検知で異常を漏れなく捕捉、AI障害分析で原因を特定し、自動復旧で修正コードの生成までをAIが支援します。
統合ジョブ監視ダッシュボード
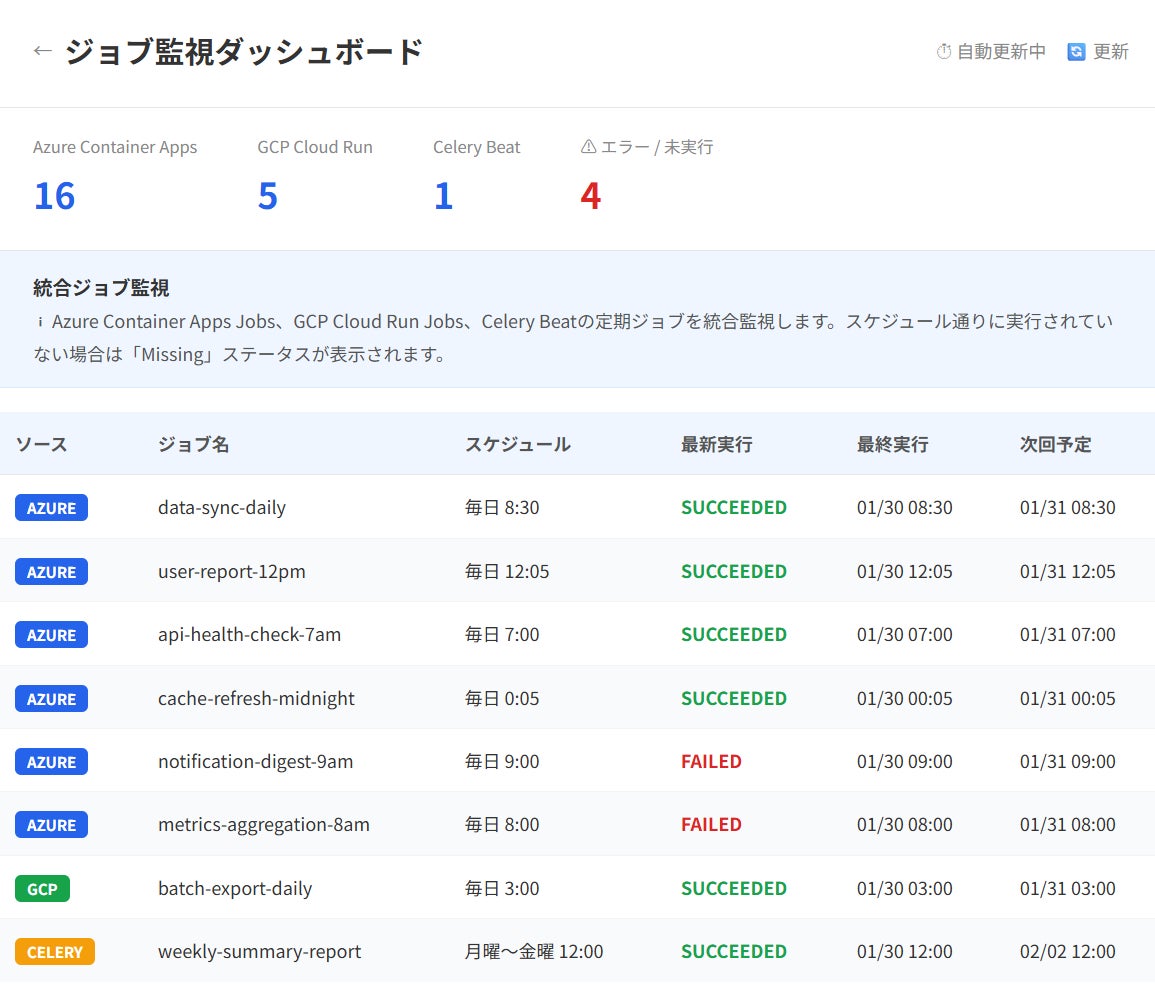
全定期実行ジョブの状態をリアルタイムに一元管理するダッシュボードです。従来Slackの複数チャンネルに散在していたジョブの状態情報を、データドリブンかつ体系的なモニタリングへと転換しました。
自動ログ記録ライブラリ(celery_task_logger)
Celeryの4種類のタスクシグナルをフックし、全ジョブの実行イベントを自動的にDBへ記録します。
-
task_prerun:ジョブの実行開始
-
task_postrun:正常完了
-
task_failure:失敗
-
task_retry:リトライ
既存のジョブコードに一切の変更不要(ゼロコンフィグ設計)で、ライブラリを導入するだけで全ジョブの実行イベントが自動蓄積されます。新規ジョブ追加時も個別の監視設定は不要です。
記録される情報
タスクID、タスク名、実行ステータス(pending / started / success / failure / retry)、開始・終了時刻、実行時間(秒単位)、処理結果サマリー、エラー内容(スタックトレース含む)、リトライ回数、実行環境(ホスト名、ワーカーID)
ダッシュボードのビュー
-
リアルタイムステータスビュー:全ジョブの現在の状態(正常稼働 / エラー発生中 / 未実行)を一覧表示
-
実行履歴ビュー:個別ジョブの過去の実行結果を時系列で表示し、エラー頻度や実行時間の推移を可視化
-
統計サマリービュー:成功率・平均実行時間・エラー発生頻度などの集約指標を提供
対象環境
-
Azure、AWS、GC
対象処理
-
Dockerコンテナ上で実行される各ジョブ(PMO日次処理、財務・採用・ECデータ同期など)
-
Celery Beatにより定期発火されるジョブ群(Webクローリング、バックグラウンド処理など)
障害検知

従来の「エラーが発生したら通知する」方式では捕捉できなかった障害パターンに対応するため、三層構造の障害検知を導入しました。
第一層:fatal error判定ヘルパー
各ジョブの実行結果を統一的な基準で評価し、致命的なエラーを確実に検知します。
-
リトライ可能な一時エラー(ネットワークタイムアウトなど)と致命的エラー(認証エラー、スキーマ変更、リソース枯渇など)を明確に区別
-
共通ライブラリとして実装されており、新規ジョブ開発時に数行のコード追加で適用可能
第二層:未実行検知
各ジョブに期待される実行間隔を定義し、その間隔を超えても実行ログが記録されない場合に異常として検知します。
-
スケジューラ自体の障害、コンテナの起動失敗、リソース不足によるジョブのスキップなど、エラー通知が発火しない類の障害を確実に捕捉
-
従来方式では検出不可能だった「そもそもジョブが起動していない」問題に対応
第三層:メタ監視(ジョブ監視を監視するジョブ)
監視システム自体の正常稼働を定期的に検証します。
-
ダッシュボードAPIのヘルスチェック、ログ記録ライブラリの動作確認、fatal error判定ヘルパーの応答確認を定期実行
-
異常検知時は、通常の監視経路とは別の独立したアラートチャネルで即座に通知
-
メタ監視ジョブ自体も独立したコンテナで実行し、本体との障害の連鎖を防止
導入成果
-
障害の発生時刻、影響ジョブ、種別(fatal error / 未実行 / 監視系異常)、ステータス(未対応 / 調査中 / 復旧済み)をダッシュボードで一元管理
-
サイレント・フェイラーの発生件数がゼロに
-
障害検知から初動対応までの平均所要時間が大幅に短縮
AI障害分析(開発中)
検知後の原因調査と復旧作業における「検知から復旧までのギャップ」を埋めるため、AIを活用した障害分析機能の開発を進めています。
分析プロセス
-
実行ログ・スタックトレースの詳細解析:エラーメッセージの内容、例外の種類、呼び出し階層を解析し、直接的な原因箇所を特定
-
正常実行時との差分比較:過去の正常実行時のログと比較し、実行環境・パラメータ・処理対象データの変化を確認
-
ソースコードのコンテキスト解析:エラー発生箇所の前後のコードロジック、依存ライブラリ、外部サービスのエンドポイント情報などを考慮し原因仮説を立案
-
外部サービスの状態確認:API応答時間やステータスコードの変化を追跡し、外部要因によるエラーの可能性を評価
-
類似エラーのパターンマッチング:過去に発生した類似障害と照合し、再発障害であれば過去の対応履歴をもとに迅速な復旧を支援
出力
-
根本原因の推定、影響範囲の評価、推奨される対処方法を含む分析レポート(マークダウン形式)
-
ジョブごとに事前定義されたコンテキスト情報(よく発生するエラーパターン、依存外部サービス一覧、過去の障害履歴)により分析精度を向上
-
ジョブの優先度に応じてレポートの詳細度や通知の緊急度を調整
自動復旧(開発中)

障害の検知→原因分析→復旧までの一連のプロセスをAIが支援し、エンジニアの介入を最小限に抑えることを目指しています。
復旧フロー
AIが障害分析の結果に基づいて修正コード案を生成し、GitHubのプルリクエストとして提出します。
-
AIは対象ジョブのソースコードリポジトリにアクセスし、最小限かつ安全な修正案を生成
-
自動テストによる検証を経た後、プルリクエストとしてGitHub上に作成
-
エンジニアがレビュー・承認・マージすることで障害復旧が完了(人間が品質を担保する安全設計)
対象となる障害カテゴリ
-
外部API仕様変更:パラメータ名変更、必須パラメータ追加に対し、APIドキュメントとエラーレスポンスを照合して修正
-
一時的なネットワーク障害:リトライロジックの追加・調整、サーキットブレーカーパターンの導入
-
データフォーマット変更:外部サービスが返すデータ構造(JSON、日付形式、エンコーディング等)の変更に対応するパース処理を生成
-
依存ライブラリの互換性問題:APIの変更や非推奨メソッドの削除に対する書き換え
-
環境変数・設定値の変更:環境変数名の変更、設定ファイルのパス変更等に対する参照先の修正
安全性の担保
-
対象コードの事前定義:AIが修正を試みてよいコード範囲をジョブごとに明示的に指定し、想定外のファイル変更を排除
-
優先度の事前定義:障害の影響度とジョブの重要度に基づき設定。優先度の高いジョブから順に復旧
-
段階的な自律性レベル:確信度高(過去に成功実績あり)→自動でPR作成 / 確信度中→複数案を提示 / 確信度低→PR作成せずエスカレーション
目指す運用スタイル
深夜・休日の障害に対しても即座に復旧プロセスが開始され、エンジニアは翌営業日の出社時にAIが作成したプルリクエストをレビューするだけで障害対応が完了します。
技術アーキテクチャ
本システムはAzureのクラウドインフラストラクチャ上に構築されており、4層構成で各層は疎結合に設計されています。
ジョブ実行基盤
-
Azure App Service:supervisord上でGunicorn + Celery Worker + Celery Beatを統合管理。Webクローリングやブラウザ操作を伴うジョブなど、アプリケーションサーバーとリソースを共有するジョブが対象
-
Azure Container Apps Jobs:各ジョブが独立したDockerコンテナで実行。PMO日次処理、財務・採用・ECデータ同期、分析データ集計など独立性の高いジョブ群が対象。ジョブごとにリソース(CPU、メモリ)を個別に最適化可能
-
コンテナイメージはGitHub ActionsによるCI/CDパイプラインで自動ビルド・デプロイ
データ永続化層
-
Azure Cache for Redis:タスクキューの管理、ジョブ間のメッセージパッシング、短期的なタスク結果のキャッシュ
-
Azure Database for MySQL:タスクの実行履歴と監視ログの永続化。時系列インデックスにより大量ログの高速検索・集計を実現
監視レイヤー
-
自動ログ記録ライブラリ(celery_task_logger.py):Celeryシグナルをフックし全実行イベントをMySQLに記録(デコレータパターンで実装)
-
統合ジョブ監視ダッシュボードAPI(job_monitoring.py):蓄積ログデータを集約しリアルタイムに提供するRESTful API
-
fatal error判定ヘルパー+メタ監視ジョブ:ジョブの異常終了・未実行・監視システム自体の障害を漏れなく検知する二重の安全網
AI分析・復旧レイヤー
-
検知された障害情報、実行ログ、スタックトレース、ソースコードリポジトリを入力として、大規模言語モデルが原因分析と修正コード生成を支援
-
修正案はGitHub上のプルリクエストとして提出→自動テスト→エンジニアのコードレビューを経てマージ
-
既存の開発ワークフロー(GitHubフロー)とシームレスに統合
デプロイメント
-
GitHub Actionsでテスト実行→コンテナイメージビルド→Azure環境へのデプロイまでを一貫管理
-
ブルーグリーンデプロイメント方式を採用し、デプロイに伴うダウンタイムを排除
今後の展望
renueは本統合モニタリングシステムをさらに進化させ、AIを活用したジョブ運用の完全自律化に向けて段階的に機能拡張を進めてまいります。
障害予測機能
-
「発生した後に対応する」リアクティブな監視から、「発生する前に予兆を捉える」プロアクティブな監視への進化
-
ジョブの実行時間推移、メモリ・CPU使用量の変化パターン、外部APIの応答時間劣化傾向、エラー率の微増トレンドなどの時系列データをAIが継続的に学習
-
「このジョブは3日以内にタイムアウトエラーを起こす可能性が高い」といった予測アラートを生成
自動復旧のカバレッジ拡大
-
現在の対象(API仕様変更、フォーマット変更等)からより広範な障害カテゴリへの対応を拡大
-
インフラレベルの自動スケーリング、依存サービスの代替エンドポイントへの自動切り替え(フェイルオーバー)、データ整合性の自動修復(自動バックフィル)など
社外向けソリューションへの展開
-
DX推進に伴いバッチジョブの数が増加し運用負荷に悩む企業は業種を問わず多数存在
-
SaaS企業、EC事業者、金融機関、製造業など、定期的なデータ処理を行うあらゆる業種・業態で活用可能
-
renueがプロダクト群として展開するAIエージェントと連携し、統合運用基盤としての展開も視野に
障害対応ナレッジの自動蓄積
-
AIが障害分析と復旧を繰り返す中で蓄積される「どのようなエラーパターンに対して、どのような修正が有効だったか」というナレッジベースを自動構築
-
属人的な暗黙知を組織の資産として体系的に蓄積・活用
renueは引き続き、AIエージェント技術を活用した業務自動化ソリューションの開発を推進し、エンジニアリングチームが創造的な開発業務に集中できる環境づくりに貢献してまいります。「人がやるべきこと」と「AIに任せられること」の最適な境界線を見極めながら、テクノロジーの力で企業の生産性向上を支援してまいります。
会社概要
会社名:株式会社renue
所在地:〒105-7105 東京都港区東新橋1-5-2 汐留シティセンター 5階
代表者:山本悠介
事業内容:AIコンサルティング業
本件に関するお問い合わせ
メール:info@renue.co.jp
すべての画像