Shisa.AI、国産モデルで最高性能を誇る多言語対応LLMを開発
〜GPT-4を超える日本語性能を実現、本日モデルをオープンソースで公開〜
Shisa.AI(本社:東京都港区)は、2025年6月3日に、日本国内で開発されたモデルとして過去最高水準の日本語性能を実現した多言語対応LLM『Llama 3.1 Shisa V2 405B』※を開発し、オープンソースで公開しました。本モデルは、GPT-4を超えるだけでなく、GPT-4oやDeepSeek-V3といった最先端モデルと主要な日本語ベンチマークで同等の性能を示しており、日本のAI研究が世界レベルで高い競争力を持つことを示しています。

Shisa.AIはこれまで数多くの日本語のトップモデルを開発した経験とノウハウを活かし、新たに複数の最高品質な日本語学習データセットを作成しました。これらは数百回を超える実験と評価テストを通じて最適化され、その有効性を実証しました。なお、これらのモデルの学習に使用した計算リソースは、株式会社ユビタス(本社:東京都新宿区、代表取締役社長兼CEO:ウェスリー・クオ)より提供されました。
また、日本語に特化した新しい評価ベンチマーク(shisa-jp-ifeval、shisa-jp-rp-bench、shisa-jp-tl-bench)も開発し、今後オープンソースとして公開予定です。
主なプロジェクト成果と技術的特長
今回開発したShisa V2 405Bは、経済産業省が設定した主要な日本語ベンチマーク指標をすべて大幅に上回りました。また、日本語・英語の主要な評価項目においてGPT-4およびGPT-4 Turboを超える性能を示しました。
主要な日本語ベンチマーク比較
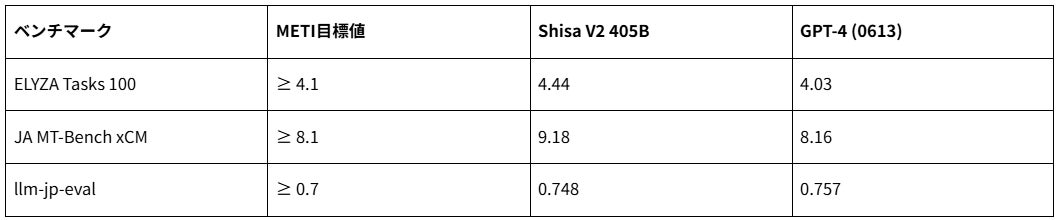
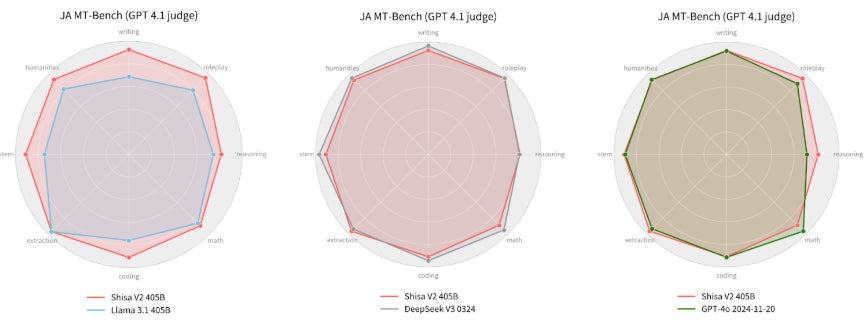
特に、業界標準の日本語ベンチマーク「JA MT-Bench」において、Shisa V2 405BはベースモデルであるLlama 3.1 405Bに対し、全評価カテゴリで性能が向上しました。GPT-4を明確に上回るだけでなく、最新のGPT-4oやDeepSeek-V3など、米国および中国のトップ研究機関のフラッグシップモデルと同等の性能を達成しています。
さらに、Shisa AIは7B〜70BのShisa V2モデルシリーズも同時に開発し、すべてApache 2.0などの商用利用可能なオープンソースライセンスの元、無料で公開しております。すべてのモデルはHuggingFaceでダウンロード可能です。
オープンソースでの高品質な学習データの提供
こうした検証結果を踏まえ、日本でのオープンソースモデルの開発をさらに促進すべく、Shisa.AIは、本プロジェクトで作成したコアデータセットをApache 2.0ライセンスのもと公開しました。これらのデータセットを活用することで、どのモデルでも日本語能力の向上が期待できます。
今後の展望
今回の成果は、日本が高度な言語モデル開発において世界レベルで競争力を有していることを示しています。Shisa.AIは、LLMの性能・信頼性・開発効率の向上を目指した研究開発を推進し、日本語を中心とした多言語AIインフラの構築に貢献していきます。
Shisa.AIについて
Shisa.AIはシリコンバレー出身の技術チームを中核とする次世代AIスタートアップ企業です。シリコンバレーの先端技術と日本市場への深い理解により、「日本語特化AI」と「データドリブン開発」を軸に、オープンソースLLMの革新を牽引しています。日本語処理技術の最先端を切り開き、日本発のAIイノベーションを世界へ発信していきます。
※『Llama』という名称をモデル名の冒頭に使用しているのは、Meta社が定めるLlama Community Licenseによるものです。
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像
- 種類
- 商品サービス
- ビジネスカテゴリ
- システム・Webサイト・アプリ開発アプリケーション・セキュリティ
- ダウンロード