アナログインメモリ計算回路のチュートリアル:計算原理、非理想性、ハードウェア考慮学習の体系化
[ 発表者 ]
・酒見 悠介 (千葉工業大学 数理工学研究センター 副所長 上席研究員/東京大学国際高等研究所ニューロインテリジェンス国際研究機構(WPI-IRCN) 連携研究者)
・粟野 皓光 (名古屋大学 大学院工学研究科 教授)
・森江 隆 (九州工業大学 ニューロモルフィックAIハードウェア研究センター 特別教授・名誉教授)
キーワード:アナログインメモリ計算、アナログ回路、エッジAI
[ 内容 ]
酒見悠介、粟野皓光、森江隆による研究チームは、次世代の超低消費電力AIハードウェアとして注目される「アナログ・インメモリコンピューティング(AIMC)」の招待付きチュートリアル論文を発表しました。本論文の主な貢献は、(1) AIMCの演算方式をメモリ種に依存せず6種類に整理したこと、(2) 非理想性をデバイス起因・回路構造起因に分類したこと、(3) hardware-aware trainingを3系統に体系化したことです。
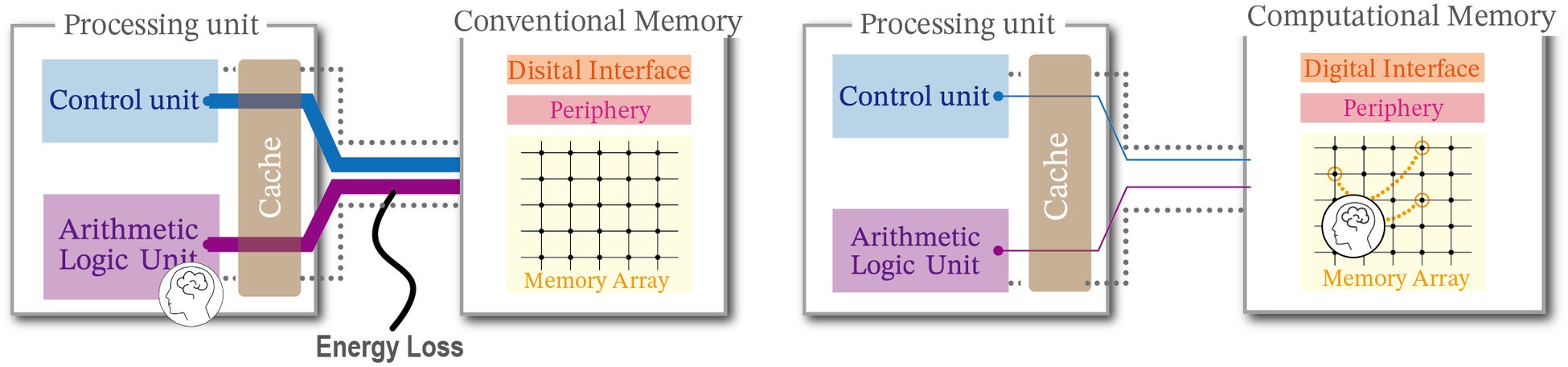
AIMCは、AI処理で大きな電力要因となる「プロセッサとメモリ間のデータ移動」を減らすため、メモリ内部で演算を実行する計算技術です(図1)。AIMCが行う代表的な計算は、次のような行列ベクトル積です。
z=Wx
ここで、xは入力ベクトル、zは出力ベクトル、 Wは重み行列です。行列ベクトル積はAI計算の中核となる演算であり、AIMCはこの計算を高いエネルギー効率で実行することができます。
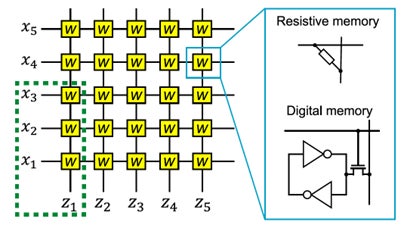
AIMCの演算方式を6つに分類
AIMCは一般に、図2のようなクロスバーアレー構造を用いて計算を行います。入力を横方向の配線(ワード線)に与え、出力を縦方向の配線(ビット線)から得ます。横方向と縦方向の配線の交点にはメモリ素子が配置され、その状態によって重み行列Wを表現します。しかし、入力・出力や重みをどの物理量で表すか、乗算と総和をどの回路原理で実行するかは実装によって大きく異なります。そのため、用いるメモリの種類や演算方式が多様であり、従来は全体像を理解することが容易ではありませんでした。
本チュートリアルでは、行列ベクトル積の計算原理に着目し、既存のAIMCによる演算方式を、電流ドメイン、電荷ドメイン、電荷再分配、容量分割、抵抗分割、時間ドメインの6つに整理しました。話を単純化するため、図2の緑破線で囲った一部に着目すると、例えば次の積和演算になります。
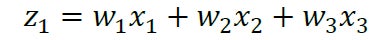
これは、3つの乗算と2つの加算からなる演算です。この同じ積和演算をAIMCで実行する方法は、図3のように複数の回路原理として整理できます。
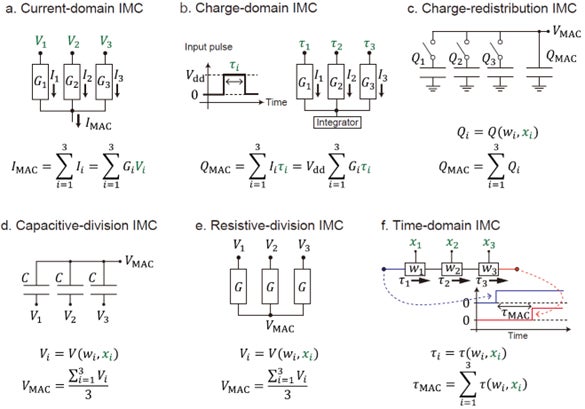
例えば、current-domain IMCでは、入力を電圧値viとして表現し、重みをコンダクタンスとして表現します。コンダクタンスGiの素子に電圧を印加すると、オームの法則によりIi=Gi Viの電流が流れます。さらに、各素子からの電流はキルヒホッフの電流則により加算されるため、例えば、current-domain IMCでは、入力を電圧値として表現し、重みをコンダクタンスとして表現します。コンダクタンスの素子に電圧を印加すると、オームの法則によりの電流が流れます。さらに、各素子からの電流はキルヒホッフの電流則により加算されるため、
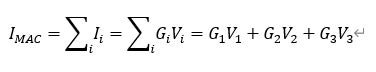
IMAC=∑iIi =∑iGi Vi =G1 V1+G2 V2+G3 V3
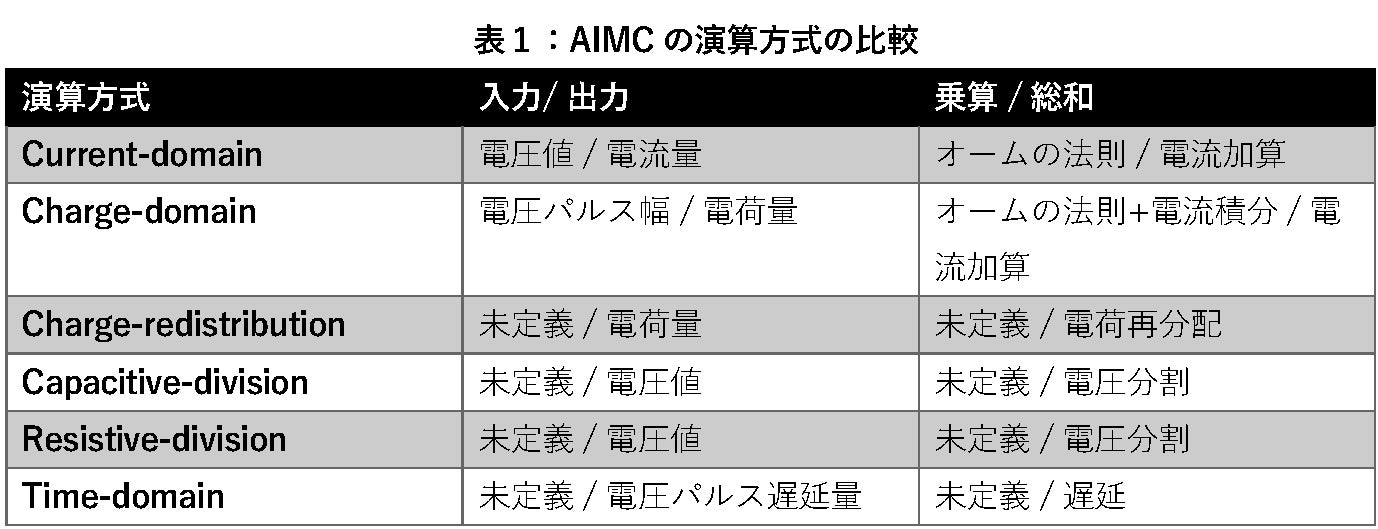
となり、アナログ回路によって積和演算を実行できることがわかります。ほかの演算方式でも、異なる入出力形式、乗算方式、総和方式を組み合わせることで積和演算を実行できます (表1)。詳細は論文をご参照ください。なお、表において「未定義」とある箇所は多くの場合、デジタル回路によって実装されています。つまり、デジタル回路とアナログ回路を組み合わせた回路構成となっています。
従来、AIMCは「SRAM型」「抵抗メモリ型」など、用いるメモリの種類に基づいて整理されることが多くありました。しかし本チュートリアルの分類により、演算方式とメモリ種は独立に考えられることがわかります。例えば、同じSRAMを用いる場合でも、current-domain IMCやcharge-redistribution IMCなど、異なる演算原理を採用できます。
この整理により、既存研究の関係を理解しやすくなるだけでなく、用いるメモリに応じた適切な演算方式の選択や、これまで十分に検討されてこなかったメモリ種と演算方式の組み合わせを考える手がかりが得られます。
非理想性とハードウェアを考慮した学習手法
本チュートリアルではさらに、AIMCの設計技術、特に数理的手法を用いた設計技術についても整理しました。AIMCの実用化に向けた重要な課題の一つが、アナログ演算に起因する非理想性です。代表例として、プロセスばらつき、デバイスの非線形性、ドリフト、配線抵抗による電圧降下(IR drop)、スニークパス電流、入出力の量子化誤差や非線形性などが挙げられます。
本チュートリアルでは、これらの課題を、デバイスに起因する非理想性と、回路構造に起因する非理想性に分けて整理し、それぞれの代表例と対策を解説しました。さらに、非理想性の影響を学習段階で取り込む手法であるhardware-aware training(HAT)について体系的に整理しました(図4)。
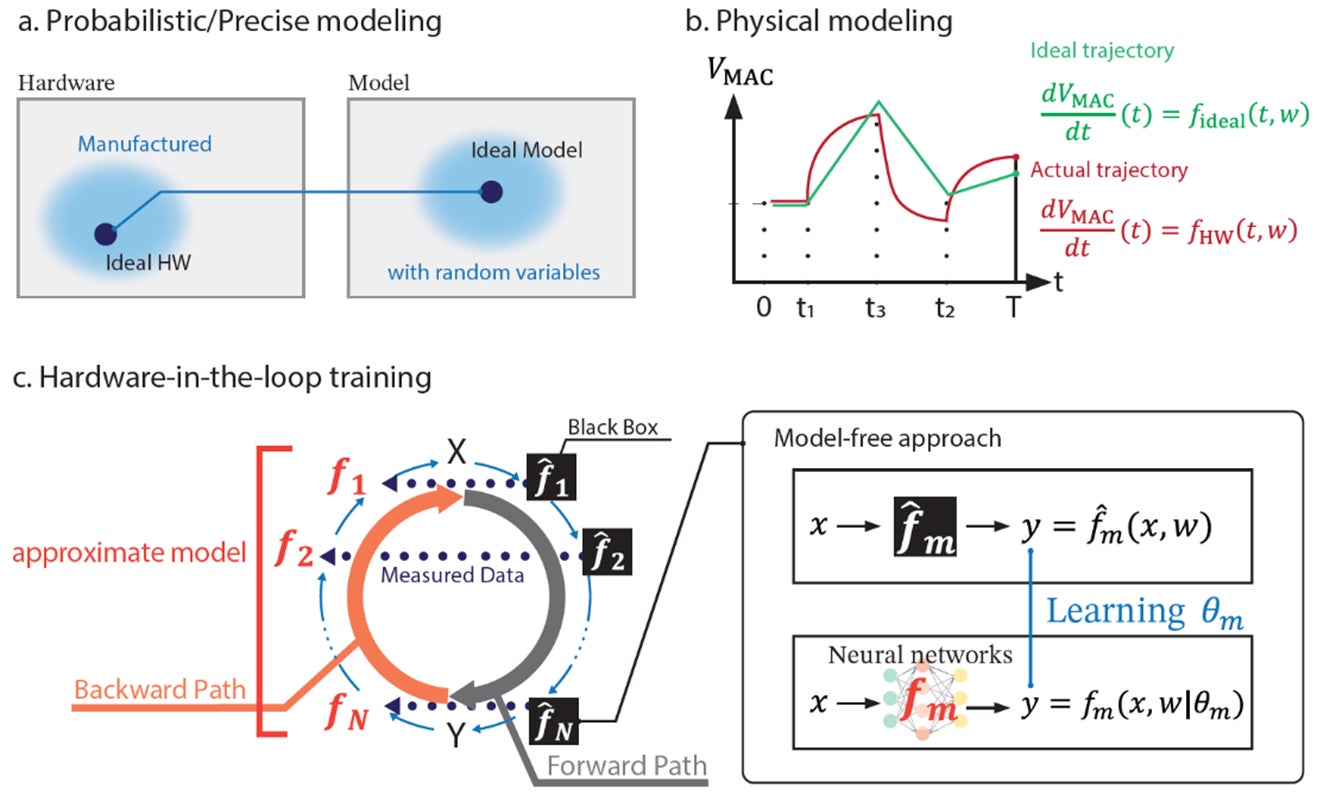
HATは、実際のAIMCハードウェアで生じるばらつきや量子化誤差、IR dropなどの影響を、学習時のモデルやデータに反映することで、推論精度の低下を抑えることを目指す手法です。本チュートリアルでは、HATを次の3つの系統に大別しました。
第一に、probabilistic/precise modelingです。これは、GPUなどの計算機上で学習するモデルに、実際のハードウェアのばらつきや量子化、IR dropなどを取り込む考え方です。代表例として、重みを表現する抵抗値にばらつきがある場合、学習時に重みへノイズを加えてロバスト性を高める方法があります。なお、この手法は、再パラメータ化トリックの考えを導入することで、モデルの重みを確率変数化しているものとしてみなすことができます。
第二に、physical modelingです。これは、AIMCの動作をより詳細に表現するため、微分方程式などの物理モデルを学習モデルに組み込む方法です。回路の非理想的な振る舞いを数理モデルとして扱うことで、より現実に近い学習が可能になります。
第三に、hardware-in-the-loop trainingです。これは、推論(forward path)は実際のハードウェアで行い、学習に必要な誤差逆伝播(backward path)は数理モデルを通して行う手法です。実ハードウェアの入出力データを取り込めるため、複雑な非理想性を完全に手でモデル化することが難しい場合にも有効です。詳細はチュートリアル論文をご参照ください。
今後の展望
以上のように、本チュートリアルでは、AIMCについて、回路原理から非理想性、ハードウェアを考慮した学習手法までを体系的に整理しました。一方で、AIMCで大規模なAIモデルを動作させるには、複数の行列ベクトル積タイルを組み合わせる必要があり、信号の一時保存や伝搬経路の制御、製造ばらつきや温度変化への対応など、実用化に向けた課題も残されています。
AIMCは、AI計算に伴うデータ移動を減らすことで、エネルギー効率の高いAIハードウェアを実現する有力な候補の一つです。デバイス技術、回路設計、数理的設計手法、AIアルゴリズムを統合的に考えることで、エッジAIやロボットなど限られた電力環境で動作するAIハードウェアの発展が期待されます。
■ 論文情報
雑誌名: IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences
論文題目: Analog In-Memory Computing from a Memory-Agnostic Perspective: Theory, Nonidealities, and Hardware-Aware Training
著者: Yusuke Sakemi, Hiromitsu Awano, Takashi Morie
URL: https://www.jstage.jst.go.jp/article/transfun/E109.A/5/E109.A_2025GCI0001/_article/-char/ja
DOI: 10.1587/transfun.2025GCI0001
論文掲載日: 2026年5月1日
■ 謝辞
本研究の一部は、JSTさきがけJPMJPR22C5/JPMJPR22B1、国立研究開発法人 新エネルギー・産業技術総合開発機構(NEDO)の委託プロジェクト JPNP14004/JPNP16007 、JSPS KAKENHI Grant Number 25K00148、JST 次世代エッジAI半導体研究開発事業 JPMJES2511から助成を受けて行われました。
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像