デンソーITLABが、NVIDIA社などが提供する汎用GPUの新たな演算量削減と精度維持を両立する手法を提案
~機械学習・AI分野のトップカンファレンス「ICLR2024」に主著研究論文が採択~
クルマとモビリティ社会全体の未来を見据え、「種」となる先端基礎研究を行う株式会社デンソーアイティラボラトリ(本社:東京都港区 代表取締役社長:岸本正志)の研究者である関川雄介らによる論文「SAS: Structured Activation Sparsification」が、5月7日から11日にオーストリアのウィーンで開催された「The Twelfth International Conference on Learning Representations (ICLR 2024)」で採択されました。「ICLR」は機械学習分野において国際的に権威のあるトップカンファレンスの一つです。本研究では、ニューラルネットワークの演算量を増やさずにパラメータ数を増やす演算手法を提案しました。これにより、演算量削減と精度維持の両立が実現できます。また専用ハードウェアを新たに開発することなく、NVIDIA社やAMD社などの汎用GPUを活用することで実装することが可能です。
■リリース詳細 > https://www.d-itlab.co.jp/blog/2024/06/03/ICLR2024.html
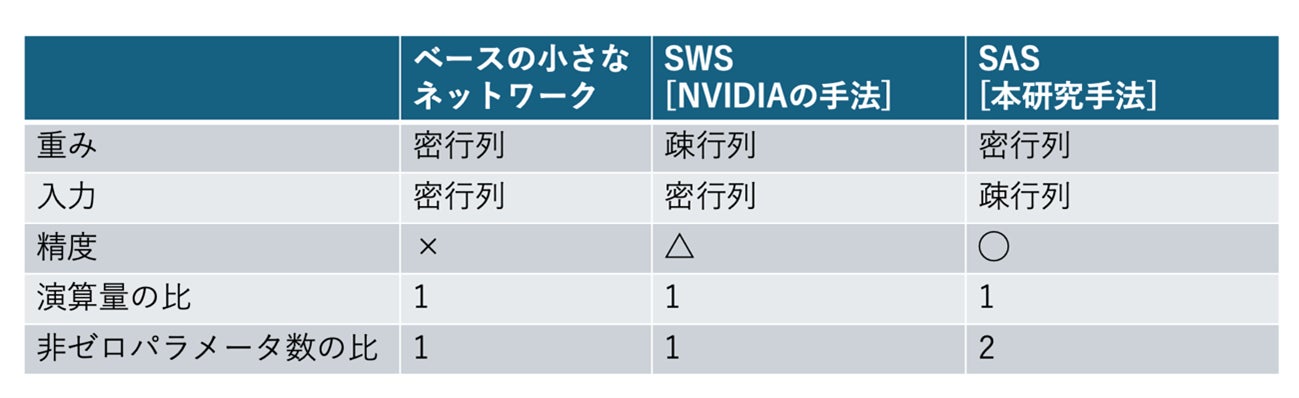
【図1】 2:1のスパースパターンを用いて演算量を保ったまま層ごとのパラメータ数を増やす手法の比較
自動車や携帯電話などのエッジ端末に大規模な高精度ニューラルネットワークのモデルを組み込むには、ハードウェアの性能や使用電力に制限があるため精度を落とさず演算量を減らす必要があります。本手法はその課題への新しいアプローチであり、世界中で幅広く活用されているGPUに搭載された、疎(スパース)な行列の高速計算機能の有益な活用法を考案した点も評価されました。
■研究の背景:ニューラルネットワークの精度向上における壁
ニューラルネットワークは、各層のパラメータが多い(幅が広い)ほど精度が高くなります。しかし、各層のパラメータが多い大規模なネットワークでは演算量が増えるため、高性能なハードウェアや高電力の供給が必要となります。一方、AIの更なる利用が期待される携帯電話や自動車などは、エッジ端末としてハードウェア性能や使用電力に制限があります。そのため、ニューラルネットワークの実装にあたってはモデルの精度を落とさず演算量を減らすことが課題となります。
前提として、ニューラルネットワークの演算は各層の入力と重みの内積を取る演算で構成されます。そして、この演算量を減らす手法として、学習したモデルの重みパラメータの一部をゼロにする「枝刈り」という手法がよく用いられます。「枝刈り」を行って、ゼロに近いパラメータを厳密にゼロに置き換えても精度への影響が小さいことが知られています。さらに、ゼロにするパラメータの位置に構造(規則性)を持たせることで、精度を保ったまま演算量を減らすことが可能です。ただし、それを実現するにはその構造を高速に処理する演算機能を搭載したGPUなどのハードウェアが必要となります。
これまでにNVIDIA社は、「連続するM個のモデルの重みのパラメータのうちN個をゼロ」にする構造を持った枝刈り手法(SWS)を提案しています。同社が開発したGPUにはこの手法をサポートする演算器Sparse Tensor Coreが実装されており、演算量を元のモデルの半分に減らすことができます。
一方で、演算量を減らすために重みではなく入力の一部をゼロにする(スパースにする)方法もあります。しかし、固定されたモデルの重みのパラメータと異なり、入力は毎回異なる値を取るため精度劣化を抑えつつ、構造を持たせてスパースにすることはこれまで困難でした。そのため、構造を持たせずにスパースにする手法が提案されてきましたが、それらの手法はハードウェア上で実装することは非常に困難です。
■本研究の成果:SWSより高い精度を同じ演算量で実現
本研究で提案するSAS(Structured Activation Sparsification)は、入力の一部をゼロにするのではなくむしろ、「連続するM個のうち1個だけ値を持つ」ような規則で入力の次元を増やす変換をします。これにより、入力数はM倍の構造化されたスパースな行列となり、重み行列もM倍のパラメータを有することが可能となります。この演算は率直には元の行列に比べてM倍の演算量を必要としますが、その構造を持ったスパース性を利用することで、元の行列と同じ大きさの小さな行列同士の演算に帰着できます。さらに、M=2の時はNVIDIA社のAmpere(Sparse Tensor Core)やAMD社のCDNAなどに搭載のスパース行列の高速計算機能を入力行列に応用することでそのまま実装することが可能です。
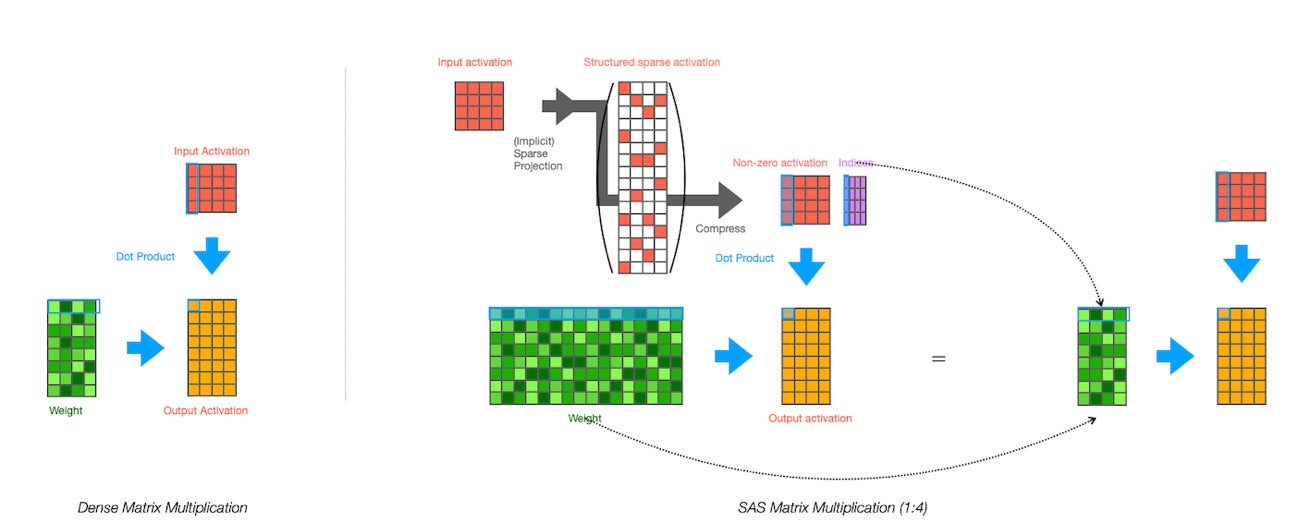
このように、本研究の提案するSASは演算量を変えずにたくさんのパラメータをもった幅の広いニューラルネットワークを実現します。そのため、同じ演算量のもとで、直接重みをスパースにする従来のSWSより高い表現力・精度を保持できます。さらに入力のスパース性を上げていくことで演算量を変えずに精度が向上していくことも確認できました。また、SASによる内積がSparse Tensor Coreで動作することも検証しました。
■本研究の論文
Yusuke Sekikawa and Shingo Yashima. “SAS: Structured Activation Sparsification.” In The Twelfth International Conference on Learning Representations (2024)
■今後の展開
今回の研究発表では、SASのアルゴリズムの提案とその精度評価ならびに汎用GPUでの動作検証を行いました。今後は、実際のアプリケーションに向けたニューラルネットワークを構築するためのソフトウェア開発を進めていきます。
また、本研究成果は汎用GPUへの適用に留まらず、SASの原理を活用した、自動車や携帯電話などのエッジ端末向けの高精度専用AIアクセラレータの開発が期待されます。

■ICLRについて
機械学習分野の国際会議「ICLR 2024」※1は世界中の研究者によって毎年開催される国際会議で、「ICML」※2「NeurIPS」※3と並び、機械学習や深層学習の分野で権威あるトップカンファレンスの一つです。
※1 「ICLR」The International Conference on Learning Representations( https://iclr.cc/ )
※2 「NeurIPS」Neural Information Processing Systems( https://nips.cc/ )
※3 「ICML」International Conference on Machine Learning(https://icml.cc/)
■株式会社デンソーアイティーラボラトリとは
デンソーグループにおける情報技術の先端研究を担う25人ほどの研究者集団であり、「自分たちで課題を見つけ、それを解決する技術の柱を作る」シーズ提案型の先端基礎研究企業です。研究分野には、深層学習やニューラルネットワーク、画像認識、自然言語処理、認知科学、信号処理、ユーザーインターフェース、センシング技術などがあります。株式会社デンソーの100%出資子会社となります。
社名 :株式会社デンソーアイティーラボラトリ
HP :https://www.d-itlab.co.jp/
所在地 :〒105-0004 東京都港区新橋4丁目3-1 新虎安田ビル13階
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像