生成AIに化学者の"目"を!文献PDFと化学構造データの同時入力で化学文書理解能力が大幅に向上
化学構造認識AIモデルと生成AIのそれぞれの強みを活かした連携により高精度な化学文書解析を実現。
株式会社ピクシスト(茨城県土浦市、代表取締役:関根章博、以下「当社」)は、特許・論文PDFに含まれる化学構造式を抽出、機械可読な形式に変換して元のPDFファイルと共に生成AIに取り込むことで、PDFファイルを単独で生成AIに取り込む手法と比較してハルシネーション(幻覚)が大幅に減少した高精度な化学文書解析を実現できる可能性があることを見出しました(図1)。
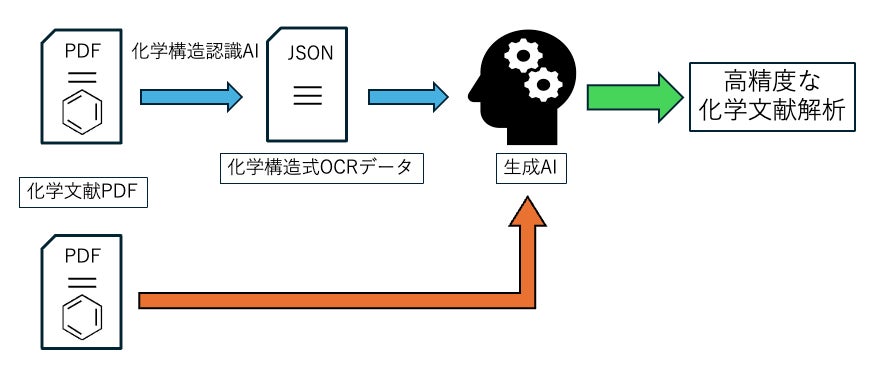
当社は、特許・論文PDFに含まれる化学構造式画像について生成AIが容易に理解できる形式で抽出・構造化することを可能にするWebアプリを開発し、オープンソースツールとして無償公開いたします。
◆背景と課題
近年、生成AIの進化により、文書解析や情報抽出の自動化が急速に進行しています。しかし、化学分野においては特有の課題がありました。
汎用的な生成AIシステム(ChatGPT、Claude、Google Gemini等)は、テキスト情報の理解には優れていますが、化学構造式という専門的な視覚情報の処理には最適化されていませんでした。これらのAIは、PDFに埋め込まれた画像を化学構造式として認識することはできても、その構造を正確に化学的な意味として解釈し、分子の詳細な情報(原子の結合関係、立体配置、官能基など)を抽出することには限界がありました。特に複雑な化合物に関しては、置換位置を間違えるなどして画像とは異なる構造として認識されるハルシネーション(幻覚)の原因となることがありました。
一方で、化学構造式認識に特化した深層学習OCRツールは、高精度で構造式を機械可読な形式(MOL形式、SMILESなど)に変換することができます。しかし、これらの専門ツールは画像から構造式を認識することに特化しているため、文書全体の文脈や、構造式と周辺のテキスト情報との関係性を理解することができません。例として、特許クレームに含まれるマルクーシュ構造式などは、官能基が「R」などの文献独自に設定された一般式グループとして記載されており、その定義は構造式画像の周囲にテキスト情報として記載されていることから、読み取りミスの原因となったり、全ての情報を抽出できないという課題がありました。
◆新手法の概要
本手法は、化学構造式認識OCRツールが提供する高精度な構造データと、生成AIが持つ文脈理解能力を組み合わせることで、両者の長所を最大限に活用した高精度な化学文書解析を可能にします。
1. PDFからの構造式セグメンテーション(構造式抽出)
最初のステップでは、化学文献中の化学構造式抽出に特化した深層学習ツール(*1)を使用します。このツールは、PDFドキュメント内のどこに化学構造式が配置されているかを自動的に検出し、それぞれの構造式を個別の画像として抽出します。
全ての抽出された画像は、Base64形式(画像を64種類の印字可能な英数字(アルファベットの大小文字、数字、+、/)に変換するエンコード方式)でエンコードされ、JSON(JavaScript Object Notation)形式のテキストデータとして出力されます(図2)。
*1 Rajan, K., Brinkhaus, H.O., Sorokina, M. et al. DECIMER-Segmentation: Automated extraction of chemical structure depictions from scientific literature. J Cheminform 13, 20 (2021).
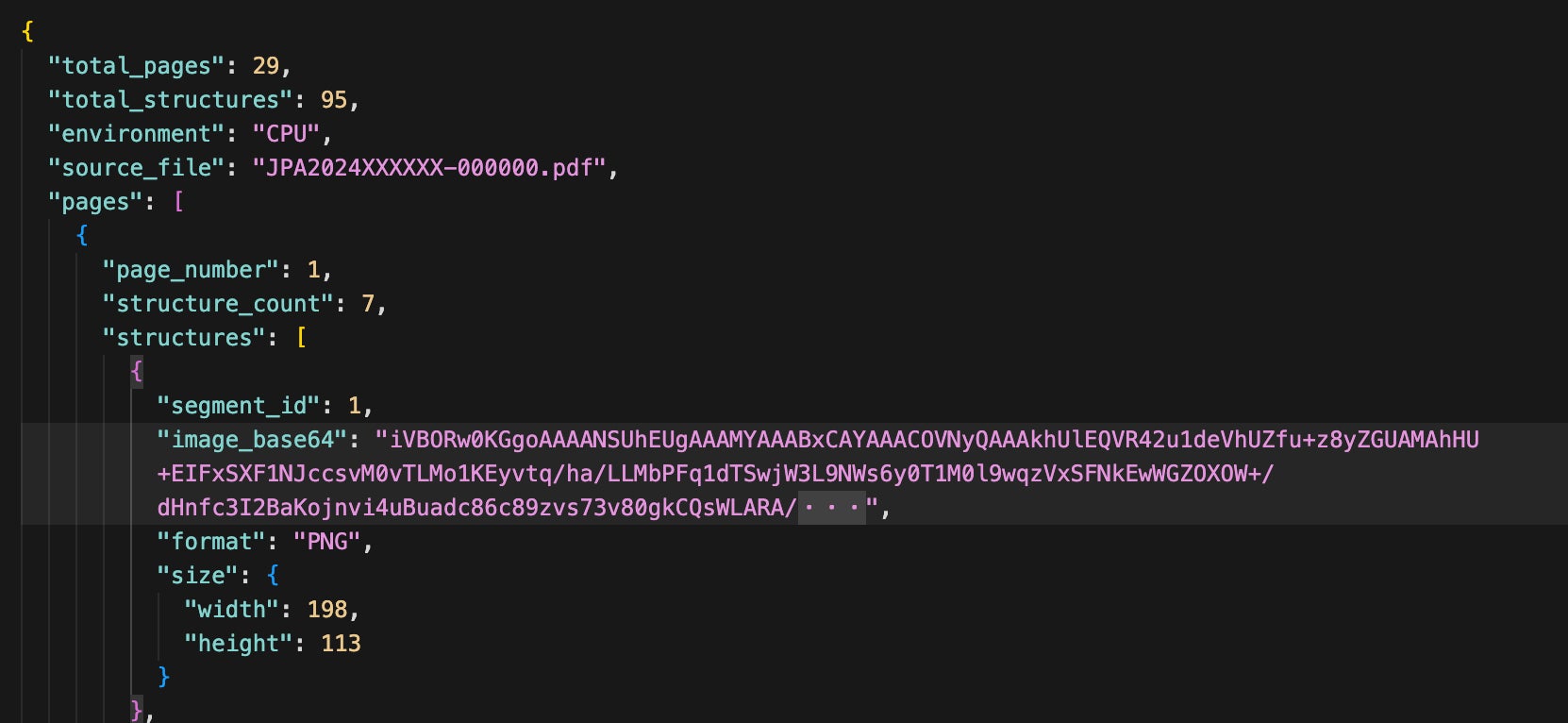
2. Base64形式でエンコードされた化学構造式画像からのOCR(光学文字認識)
第二のステップでは、化学構造式認識OCRツール(*2)を使用して、抽出された構造式画像を機械可読な形式に変換します。画像認識AIは、化学構造式の画像を解析し、以下の情報を含むJSONファイルを生成します(図3):
-
MOL形式の分子構造データ: 原子の種類、位置、結合情報などを含む標準的な分子記述形式
-
SMILES記法: 化学構造を一次元の文字列で表現した表記法
-
構造メタデータ: 画像サイズなどの補助情報
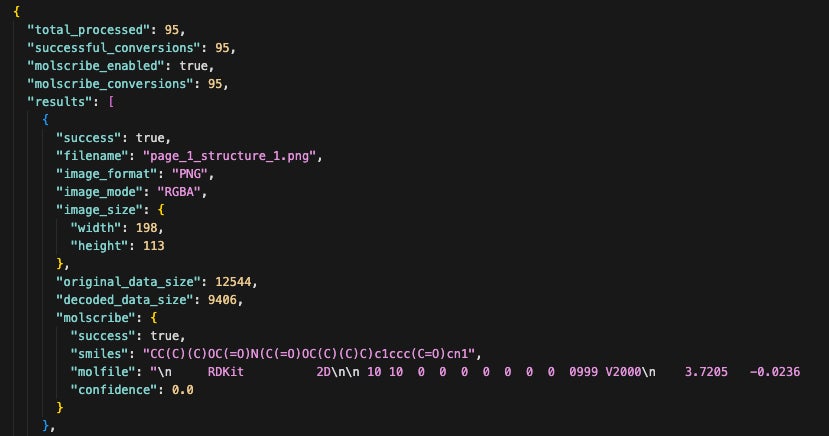
MOL形式は、化学情報学の分野で広く使用されている標準フォーマットであり、分子の三次元構造や結合の種類(単結合、二重結合、三重結合など)を正確に記述することができます。
*2 Qian, Y.etal. MolScribe: Robust Molecular Structure Recognition with Image-to-Graph Generation. Journal of Chemical Information and Modeling63, 1925–1934 (2023).
3. PDFと化学構造データの生成AIへの同時入力による化学文献解析
最後に元のPDFファイルと、上記2段階で生成されたJSONファイルの両方を共にGoogle Gemini等の生成AIのプロンプトとして入力します。
[プロンプトの例]
添付のJSONファイルは特許PDF内の化学構造式について構造化したものです。JSONファイルを参考にクレーム1について説明してください。
生成AIは、PDF内の視覚的な構造式画像と、JSONデータ内の機械可読な分子情報を相互参照することで、以下のような高度な処理が可能になります。
-
視覚情報と構造データの照合: PDFの元画像とMOL形式データを比較し、整合性を確認(必要に応じて修正可能)
-
文脈理解: 文書内の説明文や化合物名と構造式を関連付けた複雑な解析が可能
また、化学構造データがJSON形式で提供されることにより,一つの文書から抽出された全ての構造式を単一のファイルにまとめることができ、以下のメリットがあります。
-
文脈の保持: 構造式間の関係性や文書内での順序が保たれます
-
一括処理: 生成AIが参照しやすいテキスト形式であり、文書全体の構造式を一度に参照・解析できる
◆オープンソースツールの提供
当社は、化学文献PDFファイル中の化学構造式を抽出変換してJSON形式データを作成する下記デモWebアプリをオープンソースツールとして提供します。ブラウザで下記URLにアクセスするだけで、PDFファイルからMOL形式への変換をお気軽にお試しいただけます。MITライセンスでの提供になっていますので、ご自由に使用、改変、商用利用が可能です。
1. ChemGrasp-Segmentation
機能: PDFから化学構造式を抽出し、Base64 JSON形式で出力
URL: https://huggingface.co/spaces/pyxist2020/ChemGrasp-Segmentation
2. ChemGrasp-OCSR
機能: Base64データを画像に変換し、MOL形式で出力
URL: https://huggingface.co/spaces/pyxist2020/ChemGrasp-OCSR
◆今後の展開
画像情報が大きな部分を占める化学文献を正確に生成AIに分析させることは、依然として大きな課題となっています。
当社は、各種特許調査の受託の他、特許や文献を生成AIで分析するために有効な手法である構造化データの作成方法についての開発およびコンサルティング(構造化データの代行作成)を引き続き行って参ります。
さらに応用範囲を広げるため、関連技術を持つ企業様との技術提携も歓迎しております。
◆お問い合わせ先
株式会社ピクシスト
担当者名:関根 章博
メールアドレス:info@pyxist.co.jp
◆株式会社ピクシストについて

株式会社ピクシスト
超高齢社会である現代において、医療や介護に関する従事者への負担は大きなものとなっています。そんな医療業界を支える存在として注目されているのが、AIやIoTといったデジタルテクノロジーです。株式会社ピクシストは、システム開発や知的財産コンサルティングを通じてこれからの医療に貢献します。
【会社概要】
会社名 :株式会社ピクシスト
代表者 :代表取締役 関根 章博
設立 :2020 年10月 資本金:300万円 ※2025年10月末時点
所在地 :茨城県土浦市おおつ野7-11-6
会社HP :https://www.pyxist.co.jp/
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像
- 種類
- 商品サービス
- ビジネスカテゴリ
- 法務・特許・知的財産
- ダウンロード