【LLMO診断ツール】AIに「引用される会社」を100点満点で診断する。独自アルゴリズム搭載のLLMO/エンティティ診断ツール「Mesut Tools」、5月31日提供開始
~ ChatGPT・Claude・Gemini・Perplexityが“自社をどう語るか”を、100点満点で可視化。公開研究+公的知識グラフを一本の評価式に束ねた、再現可能な被参照度アルゴリズム ~
株式会社Mesut(東京都新宿区/代表取締役:宇田晃平)は、2026年5月31日、生成AI検索時代に対応した無料のAI検索最適化(LLMO)診断ツール「Mesut Tools」を提供開始します。記事URLを入力するだけで「AIに引用されるサイトかどうか」を100点満点でスコア化する『LLMOサイト診断』と、自社名・ブランド名がGoogle Knowledge Graph・Wikidata上で正式な“実体(エンティティ)”として認識されているかを判定する『エンティティ診断』の2機能を、登録不要・完全無料で公開します。
最大の特長は、診断の中核に、Mesutが独自に体系化した被参照度アルゴリズム「CITE Score(Citation-oriented Index by Tuned Entities)」を実装している点です。これは“Googleの隠れた仕組みを暴いた”といった類のものではありません。Princeton大学のGEO論文(KDD 2024)で実証された被引用率の改善戦略と、Google/Wikidataという公的な知識基盤を、7つのレイヤー・合計100点の一本の評価式に束ね直した、出所が明確で再現可能なスコアリングモデルです。
※「日本初」表記は、LLM被参照度スコアの100点満点診断と、Google Knowledge Graph/Wikidataベースのエンティティ判定を、単一の無料ツール上で統合・自動化した点に基づく自社調べ(2026年5月時点)。
■ 開発背景 ―「検索される会社」から「AIに語られる会社」へ

ChatGPT、Claude、Gemini、Perplexityといった生成AIが、検索エンジンに代わる“最初の入口”になりつつあります。ユーザーは10本の青いリンクをクリックする代わりに、AIが要約・引用した数行の答えだけを読むようになりました。
この変化は、これまでのSEOの前提を静かに、しかし根本から崩します。
・どれだけキーワードで上位表示されても、AIの回答内で引用・言及されなければ、ユーザーの目には一度も触れない
・AIは「キーワードの一致」ではなく、「誰が・何を・どれだけ信頼できる文脈で語っているか(エンティティ)」を手がかりに引用元を選ぶ
・結果、多くの企業が「自社がAIにどう認識され、どう語られているか」をまったく把握できないまま、機会損失を垂れ流している
つまり今、企業に必要なのは「検索順位」だけでなく、「AIからの被引用力(LLMO:Large Language Model Optimization)」を“測り、分解し、改善する”手段です。ところが現実には、その被引用力を一本の指標として定義し、点数化するツールは存在しませんでした。Mesut Toolsは、この“見えない指標”に初めて再現可能な物差しを与えるために開発されました。
■ 私たちが体系化したもの ― 被参照度アルゴリズム「CITE Score」の全体像
Mesut Toolsの心臓部は、独自アルゴリズム「CITE Score」です。AIがあるページを“引用したくなる”度合いを、次の7レイヤー・合計100点に分解して算出します。各レイヤーの配点は、被引用率への寄与が大きい要素ほど重く配分する設計思想に基づきます(配点はMesutによる設計値。出典のある係数は該当レイヤーに明記)。
【CITE Score 7レイヤーと配点(LLM被参照度・100点満点)】
・レイヤー1:LLM抽出最適化 26点 ― AIが本文をそのまま引用しやすい書き方か(Princeton GEO論文 KDD 2024に準拠)
・レイヤー2:エンティティ接続 20点 ― Google KG/Wikidata上で“実体”として接続されているか
・レイヤー3:AI開門設定 15点 ― AIクローラー17種にクロール・参照を許可しているか
・レイヤー4:構造化データ(Schema) 13点 ― JSON-LD等でAIが意味を解釈しやすいか
・レイヤー5:著者・運営者プロファイル 11点 ― 誰が書いたか(E-E-A-T)が明示されているか
・レイヤー6:ブランド・サイテーション 9点 ― ブランド名・固有名詞が文脈内で適切に出現しているか
・レイヤー7:鮮度・更新シグナル 6点 ― 情報の更新性・最終更新の明示
・合計:100点
この100点(LLM被参照度)に加え、従来型SEOの観点を別軸の100点(従来検索シグナル)として並走測定。2軸を統合してS+〜Dの総合グレードを判定します。
▼ レイヤー1の内訳 ― ここが“発掘した法則”の核心
レイヤー1(LLM抽出最適化/26点)は、Princeton大学のGEO論文(KDD 2024)で「AIの回答内に引用される確率」を有意に押し上げると実証された3戦略を、論文の実証値の比率そのままに配点しています。
・引用文(Quotation)密度の最適化 ― 論文実証値 AI被引用率 +42.6% → CITE配点 10.7点
・統計データ(Statistics)密度の最適化 ― 論文実証値 +32.8% → CITE配点 8.3点
・外部権威リンク(Citation)の最適化 ― 論文実証値 +27.7% → CITE配点 7.0点
※上記の改善率(+42.6%/+32.8%/+27.7%)はPrinceton GEO論文(KDD 2024)の実証値であり、Mesut Tools導入による実績値ではありません。CITE配点は当該実証値の比率(42.6:32.8:27.7)をレイヤー1の26点に正規化したMesutの設計値です。
「流行りの体感SEO」ではなく、査読を経た学術研究の実証値を、そのまま配点ロジックに落とし込む――これがCITE Scoreの設計思想です。
■ コア機能①:LLMOサイト診断 ―「AIに引用されるサイトか」を100点満点で診断
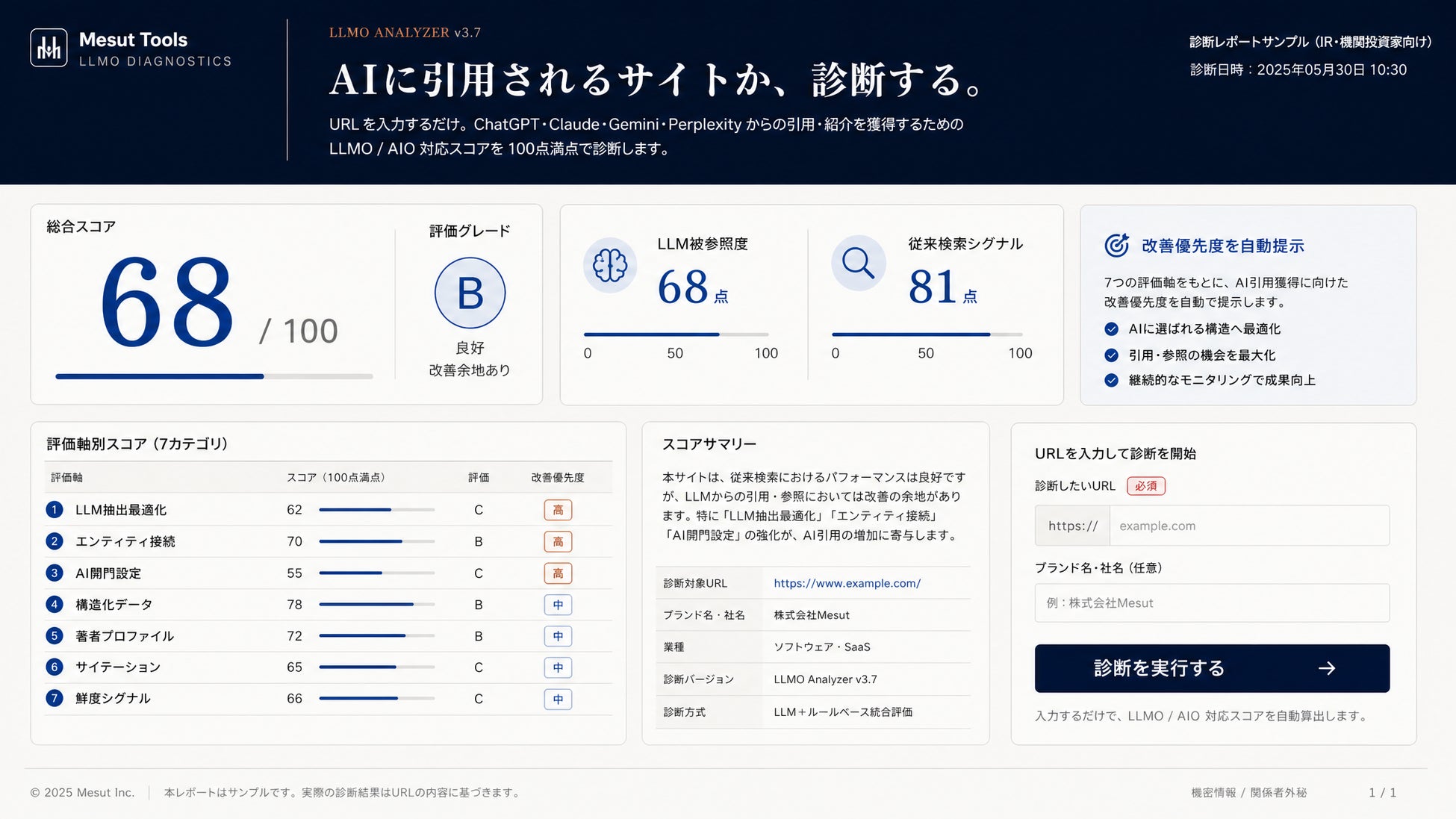
メインコピーは「AIに引用されるサイトかどうか、診断する。」
診断したい記事URLを入力するだけ(任意でブランド名・社名も入力可能)。約15〜30秒で、CITE Scoreが7レイヤーを自動採点し、ChatGPT・Claude・Gemini・Perplexityから引用・紹介を獲得するためのLLMO/AIO対応スコアを100点満点で算出します。完全自動・登録不要・完全無料。
▼ 出力される主なスコア・指標
・LLM被参照度 ― AIに引用されやすいかを100点満点で数値化(CITE Score本体)
・従来検索シグナル ― 従来型SEOの観点を100点満点で数値化(別軸で並走測定)
・グレード判定 ― 下記6段階で総合評価
【グレード判定(6段階)】
・S+:95〜100点 ― AIが第一引用元に選ぶ最上位水準
・S:85〜94点 ― 主要AIから安定的に引用される水準
・A:75〜84点 ― 引用獲得の有力候補。あと一歩で上位
・B:60〜74点 ― 部分的に引用される。改善余地が大きい
・C:40〜59点 ― 引用されにくい。複数レイヤーに課題
・D:0〜39点 ― AIにほぼ認識されていない要改善状態
▼ 7レイヤーの診断軸(詳細)
・AI開門設定 ― AIクローラー17種(GPTBot/ChatGPT-User/OAI-SearchBot/ClaudeBot/anthropic-ai/Google-Extended/Googlebot/Applebot-Extended/PerplexityBot/Perplexity-User/Bingbot/CCBot/Bytespider/Amazonbot/Meta-ExternalAgent/cohere-ai/Claude-Web)の許可状況を一括判定。1種でも誤ってブロックしていれば、そのAIからは永続的に引用されません。
・構造化データ(Schema)レイヤー ― Article/Organization/Person/FAQ等の構造化データの整備状況。
・著者・運営者プロファイル ― 誰が書いた情報かの明示度(E-E-A-T)。
・LLM抽出最適化 ― AIが本文を引用しやすい書き方か(GEO 3戦略の達成度)。
・エンティティ接続 ― 固有名詞がKG/Wikidataに接続されているか。
・ブランド・サイテーション ― ブランド名出現箇所の可視化と、競合4社との並列比較表。
・鮮度・更新シグナル ― 情報の更新性・最終更新日の明示。
▼ サンプル診断書(カルテ・イメージ)
・診断URL:example.co.jp/column/llmo
・総合グレード:B(68点/100点)
・LLM被参照度:68点 / 従来検索シグナル:81点
・L1 LLM抽出最適化:18.2/26点(引用文密度が基準未満)
・L2 エンティティ接続:9.0/20点(Wikidata未接続)
・L3 AI開門設定:15.0/15点(全17ボット許可)
・L4 構造化データ:11.0/13点(Article・FAQ実装済)
・L5 著者プロファイル:7.0/11点(著者schema欠落)
・L6 サイテーション:5.0/9点(ブランド出現が薄い)
・L7 鮮度シグナル:3.0/6点(最終更新日が非表示)
・最優先改善:L2エンティティ接続(+11点の伸びしろ)
・※数値は仕様説明のためのサンプルです。
▼ 改善まで自動生成 ― 診断して終わりにしない
CITE Scoreは「どこで何点を失ったか」を示すだけでなく、失点レイヤーごとに具体的な修正素材を自動生成します。
・robots.txt/llms.txt のひな型(AI開門設定の修正)
・JSON-LD(構造化データ・著者schema)のひな型
・FAQ HTML のひな型(LLM抽出最適化の補強)
「次に何を直せば、何点上がり、どのグレードに届くか」を具体的なアクションとして提示。結果はCSV/JSON/PDFで出力できます。これまで感覚でしかなかった「AIにどう評価され、どこを直せば引用されるのか」という問いに、初めて数字で答えるツールです。
■ コア機能②:エンティティ診断 ―「AIはあなたの会社を“実在する存在”として認識しているか」
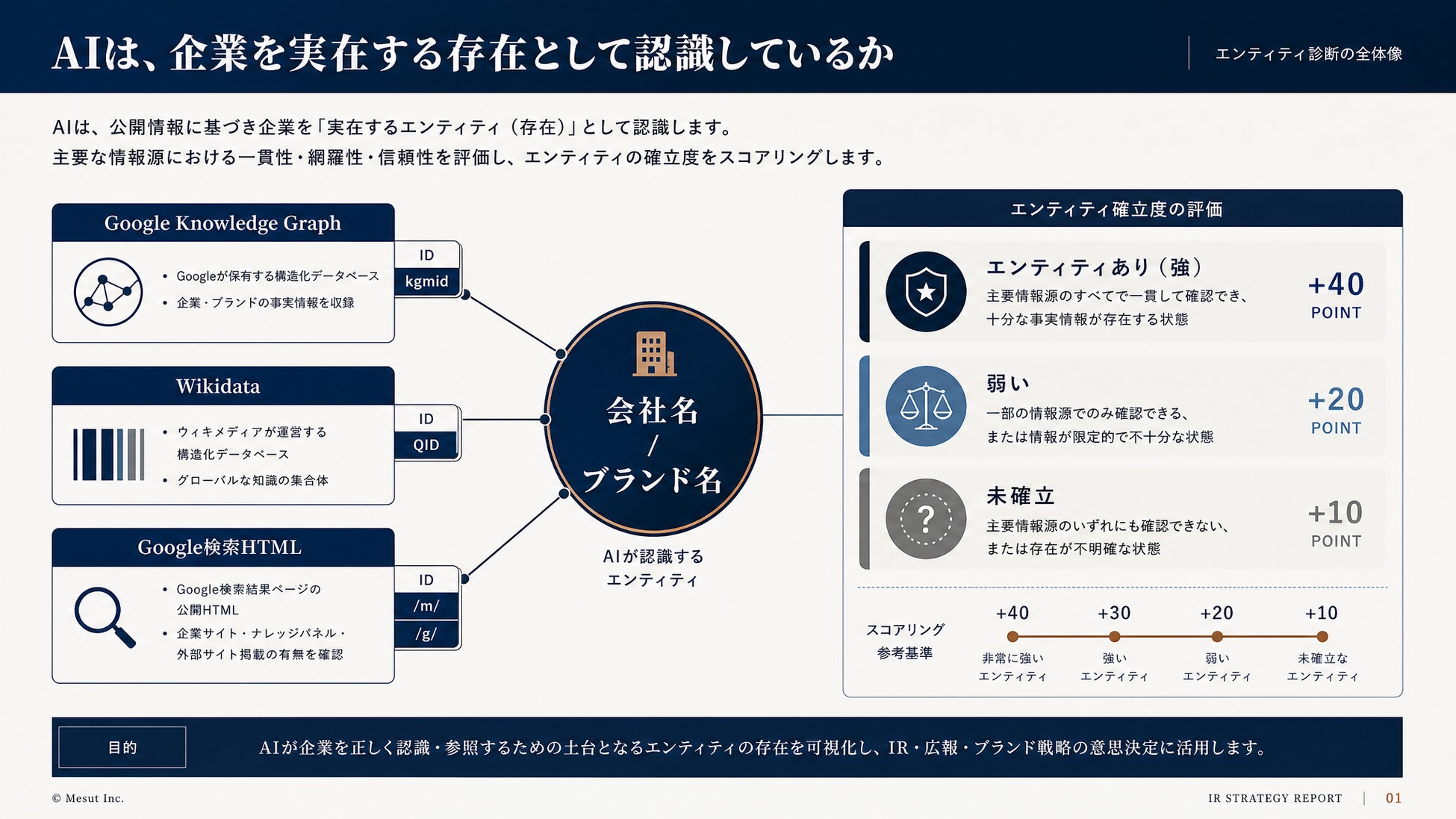
LLMOのもう一つの鍵がエンティティ(実体)です。LLMOでは、エンティティ化されている固有名詞ほど引用されやすい傾向があります。AIは、Wikidataなどの知識グラフ上で“正式な存在”として認識している固有名詞を、安心して引用するからです。逆に言えば、知識グラフ上に存在しない名前は、AIにとって「よく知らない名前」であり、引用のリスクとして避けられます。
エンティティ診断は、自社名・ブランド名・人名などの固有名詞を入力するだけで、その名前がAIにとって“実在する存在”として認識されているかを判定します。実行は「判定する」ボタンを押すだけ。Person/Organization/Place/Book/Movie/Event の6タイプで絞り込みも可能です。
▼ 3つのデータソースを並行参照(エンティティ強度の算出)
・Google Knowledge Graph ― 正式ID(kgmid)を取得
・Wikidata ― QID・Freebase ID・Google KG IDの相互紐付けを取得
・Google検索HTML ― /m/・/g/ で始まる識別子を抽出
これら3ソースの紐付け状況を統合し、エンティティ強度を判定します(判定ロジックの配点はMesut設計値)。
・Google KG ID(kgmid)あり:+40
・Wikidata QID あり:+30
・KG IDとWikidataの相互紐付けあり:+20
・検索HTML識別子(/m/・/g/)あり:+10
▼ 判定結果
・「エンティティあり(強)」:Google/Wikidataの双方に正式な識別子が紐付き、相互参照されている状態
・「弱い」:Wikidataのみ、または間接的なシグナルしか存在しない状態
・「未確立」:いずれの知識グラフにも識別子が見当たらない状態
つまりこのツールは、「AIから見て、あなたの会社は“実在する存在”か、それとも“よく知らない名前”か」を一発で突きつけます。多くの企業が「弱い」「未確立」と判定される現実――それこそが、AI検索時代に真っ先に可視化すべき新たな課題です。
■ なぜMesut Toolsか ― 独自アルゴリズムと透明な根拠
従来のSEOツールは「検索エンジンにどう評価されるか」を測ってきました。Mesut Toolsが測るのは、その先にある「AIにどう引用・認識されるか」です。
・独自アルゴリズム「CITE Score」:AIからの被引用力を、感覚ではなく7レイヤー・100点満点に分解して数値化。S+〜Dのグレードで自社の現在地が一目でわかる
・出所が透明:配点の根拠となる学術研究(Princeton GEO論文 KDD 2024)と公的知識基盤(Google KG/Wikidata)を明示。ブラックボックスではなく、再現可能なロジック
・エンティティ判定:公的知識基盤を直接参照し、「AIに認識されているか」を客観的に判定
・改善まで一気通貫:スコアを出すだけでなく、robots.txt/llms.txt/JSON-LD/FAQのひな型を自動生成し、明日から直せる
「AIが自社をどう語るか」を数字で可視化し、改善アクションまで示す――Mesut Toolsは、キーワードSEOの次に来る“AI検索最適化”の標準ツールを目指します。
■ 限定オファー ― 先着50社限定「無料LLMOエンティティスコア診断レポート」

提供開始を記念し、先着50社限定で、専門家による「無料LLMOエンティティスコア診断レポート」を進呈します。
・貴社サイトのCITE Score(LLM被参照度)スコア・7レイヤー内訳・グレード判定
・自社名/ブランド名のエンティティ強度判定結果
・AIに引用されるための優先改善アクション(個別コメント付き)
▼ お申し込みはこちら
https://mesut.co.jp/ai-checker/
(お申し込み・ご相談:https://mesut.co.jp/contact/ )
募集期間:2026年5月31日〜先着50社に達し次第、受付を終了します。対象:法人サイトを運営する企業のご担当者さま。
■ 会社概要
・会社名:株式会社Mesut
・所在地:〒160-0023 東京都新宿区西新宿7丁目5-12 岡田ビル302号
・代表者:代表取締役 宇田 晃平
・設立:2024年8月1日
・事業内容:AI検索最適化(LLMO)ツールの開発・提供、SEO・MEOを中心としたWebマーケティングのコンサルティング支援
・電話番号:080-6421-7280
・コーポレートサイト:https://mesut.co.jp/
・お問い合わせ:https://mesut.co.jp/contact/
・サービスサイト:https://mesut.co.jp/ai-checker/
■ 本件に関するお問い合わせ
・株式会社Mesut 広報担当:宇田 晃平(代表取締役)
・TEL:080-6421-7280
・お問い合わせフォーム:https://mesut.co.jp/contact/
・Email:info@mesut.co.jp [※実際の受信アドレスをご確認ください]
・サービスURL:https://ai-checker-red.vercel.app/
■ 注釈・出典
・「日本初」表記は、LLM被参照度スコアの100点満点診断とGoogle KG/Wikidataベースのエンティティ判定を単一の無料ツール上で統合・自動化した点に基づく自社調べ(2026年5月時点)。
・改善率(+42.6%/+32.8%/+27.7%)はPrinceton GEO論文(GEO: Generative Engine Optimization, KDD 2024)の実証値であり、本ツール導入による効果を保証するものではありません。
・「CITE Score」各レイヤーの配点、およびエンティティ強度の配点は、公開研究と公的知識基盤に基づきMesutが独自に設計・正規化した設計値です。Google等の非公開アルゴリズムを解析・再現したものではありません。
・導入実績・社数・効果に関する数値は確定後に差し替えます(現時点では実測値を記載していません)。
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像