FuriosaAI、NeurIPS 2025で「持続可能なAI」に向けたRNGD NPUを披露
12月2日から7日にかけて、米国カリフォルニア州サンディエゴで、神経ネットワークおよび人工知能分野において最も権威ある学術イベントの一つであるNeurIPS(Neural Information Processing Systems Conference)2025が開催された。NeurIPSは1987年、神経ネットワーク研究を目的に生物学、物理学、計算機科学の研究者が集まったことを起点とし、現在では世界最大規模の人工知能学術会議として評価されている。
NeurIPSは、Googleの学術検索サービス「Google Scholar」におけるコンピュータサイエンス/AI分野で、NatureやScienceといった最高峰の科学誌と同等の影響力を持つとされている。今年は計2万1,575本の論文が投稿され、そのうち24.52%にあたる5,290本が採択された。データマイニングおよび機械学習の起点と評価されるAlexNet、自然言語処理に革命をもたらしたWord2Vec、そして大規模言語モデル(LLM)の中核技術であるTransformerモデルはいずれもNeurIPSで発表された論文だ。
今年のNeurIPSにおける主要キーワードは、▲OpenAIのo1モデルに代表される段階的思考を行う推論(Reasoning)能力 ▲クラウド接続なしでスマートフォンやノートPC上で動作するオンデバイスAI ▲AI倫理に関わる安全性およびアライメントだった。韓国企業では、NAVERが超大規模AIの効率化やロボティクス関連で10本の論文を発表し、Viva Republica(ビバ・リパブリカ、TOSS)も連合学習の最適化に関する論文が採択され注目を集めた。

一方、AI半導体技術企業のFuriosaAI(フュリオサAI)は「シルバー・パビリオン」として参加し、カン・ジフンFuriosaAI最高研究責任者(CRO)が「シリコンからモデルまでのAI効率最適化(Optimizing AI Efficiency from Silicon to Model)」をテーマにスポットライト発表を行った。
カンCROは「データセンターが処理できるデータ量は電力消費量と強い相関関係にある。ハイパースケーラーやAIデータセンター運営企業が発電所への投資を検討する理由も、最終的にはデータセンターの処理量を拡大するためだ」と述べ、「同じ電力消費でより多くの処理を行えるようにすることが業界全体の課題だ」と説明した。
さらに「ハードワイヤード(半導体設計時に回路が物理配線として固定され、後から変更できない方式)で半導体を設計すると、製造コストが高く、開発期間も長くなる。結果として、性能最適化の観点から、データバッチを並列処理するGPUを使うのか、大規模行列演算(シストリックアレイ)に特化した専用半導体を使うのかを選択する必要がある」と述べた。
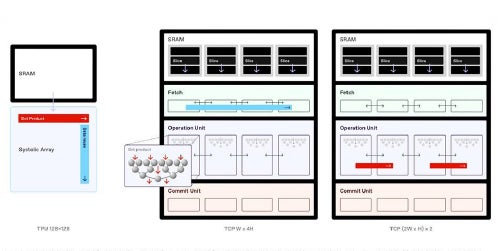
GPUは複数のメモリ階層構造を持ち、柔軟なデータフローを提供する。グローバルメモリからローカルメモリへの移動など、多様な処理に適している点が強みだ。その結果、高帯域幅メモリ(HBM)から内部メモリ(SRAM)へのデータ移動が自由である一方、追加の実行時間と消費電力が必要となる。この特性により、AIモデルの学習には有利だが、推論用途では投入コストに対する効率が相対的に低い。
一方、シストリックアレイ方式はGoogle TPUやAWS Trainiumのように、特定用途向けに設計された専用半導体を指す。最近ではGemini 3.0 ProがTPUで学習されたことで再び注目を集めているが、データフローが固定されている点が特徴だ。個々の演算効率は高いものの、行列積など特定の演算に用途が限定される。また、企業の用途に合わせて設計されるため、特定企業で大規模に採用されるケースが多い。
FuriosaAIのRNGDは、テンソル縮約プロセッサ(TCP)を通じてGPUとシストリックアレイの中間に位置するバランスを提供する。カンCROは「TCPではSRAMが複数のスライスに分割され、それぞれのスライスからデータが抽出される形でルーティングされる。データパケットはそのまま転送される場合もあれば、複数のスライスに分配されることもある」と説明した。
簡単に言えば、シストリックアレイが一方向のデータフローを前提とするのに対し、RNGDはデータフローの方向を構成できる。SRAMを複数スライス単位で管理し、データを順次送るだけでなく、2枚から最大8枚まで同時に分配できる。従来のシストリックアレイが固定サイズの行列しか処理できなかったのに対し、RNGDは任意サイズの行列演算を分割処理することで、ハードウェア資源を最大限活用できる。
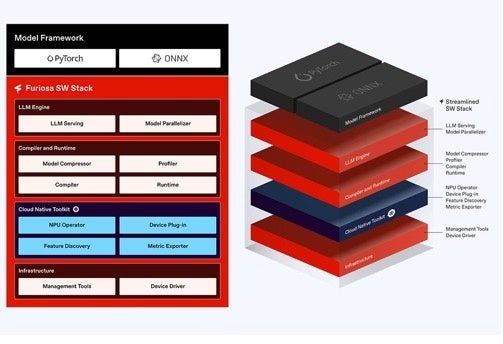
カンCROは「RNGDのデータフローは、処理効率の向上だけでなく、ソフトウェア管理の面でも優れている。PyTorchで実行される高水準かつ集約的な演算をアーキテクチャに直接マッピングでき、成果を確認しやすい。結果としてFuriosaAIは、LLMサービスを含む独自構築のソフトウェアスタックを提供している」と語った。

TCPの技術的説明に続き、カンCROは来年1月から2万枚規模のRNGDチップを量産する計画を明らかにし、電力効率についても言及した。「現在、データセンターで使用されるラックは平均18kWを超えることが難しく、空冷方式ではほぼ上限だ。RNGDは15kWラックを基準に、NVIDIA H100システムより3.5倍多くのトークンを生成できる」と述べ、「電力効率を高めることでデータセンターの電力密度をさらに引き上げることができる。次世代製品は180WのTDPを超え、400W級となる見込みだ」と説明した。
最後にカンCROは「RNGDはクラウド環境での効率的な管理と配備を想定し、Kubernetesをサポートしているほか、低レベルアクセスAPIを提供することで、専門開発者が独自に最適化されたコンパイラやシステムを構築できるようにしている」と付け加えた。
AI業界の主要テーマとして浮上する「持続可能なAI演算」
NeurIPSがAI業界最大の学術イベントとして位置づけられる中、AI倫理に関する責任ある議論も活発に行われている。代表的な例として、「機械学習による気候変動への対応」をテーマとしたワークショップでは、従来のように機械学習を用いて気候問題の解決策を探るのではなく、AIモデルを構築する過程における気候的利益とコストを議論し、より効果的なAIアプローチを導き出す試みが行われた。
関連論文にはエネルギーや気候予測に関する研究も多いが、データセンターの持続可能性向上や炭素排出量削減を目的としたワークロード分散、大規模な炭素削減を見据えたLLMアプローチなど、従来のAI構築手法そのものを見直す研究も数多く発表された。結論は「AI構築に必要な電力消費をいかに効率化するか」に集約され、その中核にAI半導体の効率向上が位置づけられている。
FuriosaAIのようなNPU企業がNeurIPSに参加する理由も、こうした解決策を提示するためだ。来年1月からはRNGDの本格量産が始まり、韓国のみならず世界各国のAIデータセンターに導入されることで、炭素排出削減とAI推論効率の向上の両立に寄与する見通しだ。「持続可能なAI演算」というテーマへの関心が高まるほど、RNGDのような高効率AI半導体への注目度も一段と高まるとみられる。
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像