<大林組 × Laboro.AI>AIによる建設物の揺れ制御が実現!
強化学習の実用化に向けた取り組みで成果
(株)大林組との建設物の揺れを制御することを目的としたAI開発の取り組みにおいて、従来よりも高い効果で揺れを制御することに成功いたしました。
<今回のポイント>
✔︎ 産業実装が難しいと考えられていた手法の一つ、強化学習を活用
✔︎ AIが自ら揺れを抑えるための動き方を学習した結果、従来手法の1/2を下回る制振効果
✔︎ 制振領域に留まらず、強化学習のあらゆる制御分野での産業応用の可能性を見込む
<今回のポイント>
✔︎ 産業実装が難しいと考えられていた手法の一つ、強化学習を活用
✔︎ AIが自ら揺れを抑えるための動き方を学習した結果、従来手法の1/2を下回る制振効果
✔︎ 制振領域に留まらず、強化学習のあらゆる制御分野での産業応用の可能性を見込む
- リリース概要
「強化学習」は、機械学習の学習方法として知られる「教師あり学習」「教師なし学習」に並ぶ学習手法の一つで、これまではゲームを始めとする限られたシミュレーション環境での活用が中心であり、物理的なビジネス現場への応用は難しいと考えられていました。今般、強化学習によるAIの実装成果を見出せたことは、AIのビジネス活用に新たな可能性を切り開くものとして大変意義のある取り組みだと捉えています。
当社は今後、大林組とともにさらなる研究開発を進めてまいります。また、機械学習技術を用いたオーダーメイドAIソリューション『カスタムAI』をより多くの産業の企業様に導入いいただくことを目指すとともに、すべての産業にイノベーションを創出するパートナーとして引き続き精進してまいります。
1.大林組との振動制御AI開発プロジェクトについて
<概要>
今回のプロジェクトは、建設物の揺れを制御するために建物内部に設置される重り(マスダンパー)の動きをAIで制御することにより、従来よりも揺れにくい環境の実現を目指したものです。
制振技術による振動制御は大きく受動的な制御法であるパッシブ制振(TMD:Tuned Mass Damper)と、能動的な制御法のアクティブ制振(AMD:Active Mass Damper)に分けられます。当プロジェクトは、アクティブ制振にAIを活用したものです。
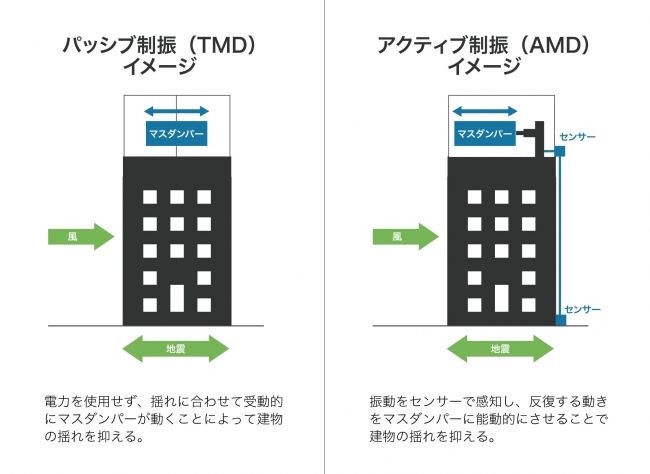
<実験環境>
まず、Laboro.AIの機械学習エンジニアが物理計算にもとづくシミュレーション環境を構築し、シミューレーター上で効果が高い制御則を獲得しました。次いで、大林組技術研究所(東京都清瀬市)内に造られた橋を実験の場として利用し、実際に人が歩いた際の振動を制御対象として検証を行いました。

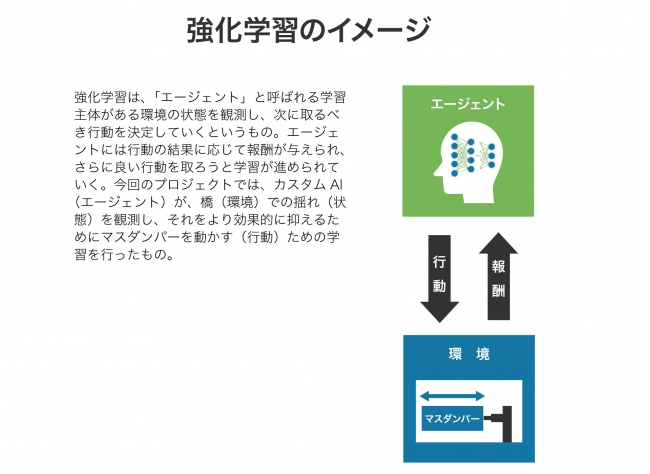
<AIの学習アルゴリズム(強化学習)>
今回のカスタムAI開発では、その学習アルゴリズムとして「強化学習」を用いています。強化学習は、AIが試行錯誤を経て、どのように行動すれば良いかを自ら習得していくアルゴリズムです。
AI、とくにその主流である機械学習の手法として知られる「教師あり学習」「教師なし学習」と比べると、手本となる正解データ(教師データ)を参照させる必要がない自律的な学習アルゴリズムと言えます。強化学習は、シミュレーション環境が必要であることなどから、リアルな現場を伴う産業では活用されにくい手法とされていましたが、今回、強化学習にニューラルネットワークを用いることにより成果に至りました。
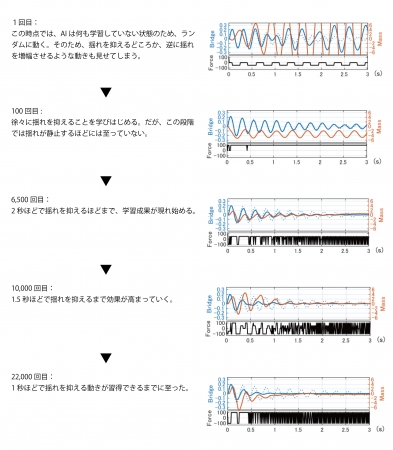
<成果解説①>
まず、シミュレーション環境で約2万回に及ぶ実験を繰り返し実施した結果が下記の図です。1回のシミュレーションは3秒間単位で実施し、図中の青い線が橋の揺れを、赤い線がAIによって制御されたマスダンパーの動きを示しています。マスダンパーの動き(赤)によって、上下の揺れ(青)が早い段階で低減されるほど、AIが効果的に制御力を発揮していることを表しています。
<成果解説②>
次に、シミュレーション環境での結果を橋の制御システムに転用し、実際に人が歩いた時の振動の違いを比較検証した結果が次のグラフです。グラフの山が小さいほど人が揺れを体感しにくいことを示しています。なお横軸は周波数(揺れの周期)で、値が小さいほど人が体感しやすい大きな揺れを、値が大きいほど揺れを感じにくい細かな揺れを意味します。
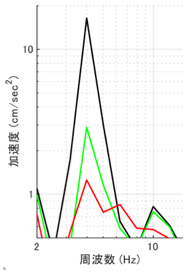
- 非制振(図中の黒線):何も制御を施さない状態
- 従来手法(図中の緑線):従来手法のAMDによる制御
- AI制御(図中の赤線):今回の強化学習によるAIモデル
非制振の状態で揺れが最大となる箇所(4Hzあたり)で、強化学習によるカスタムAIが最も小さく位置していることがわかります。数値としては従来のAMDによる制御の1/2を下回る数値を示しており、これまで以上に揺れが感じられにくい環境をAIが作り出すことに成功したことを意味しています。
2.制御系カスタムAIの将来展開について
<様々な振動制御への応用>
今回の成果は、建設物の揺れの制御に留まらず、例えば次のような振動を生じるあらゆる機械設備でも同様にAIによる学習効果が期待でき、技術転用の可能性が高い成果だと言えます。
・自動車、鉄道などの公共交通機関
・半導体製造など、振動にシビアな製品の製造機器
・空気抵抗による振動への対策が必要な航空宇宙技術
<あらゆるリアルタイム機械制御への応用>
また、強化学習を用いた今回のプロジェクトは、制御技術における「フィードバック制御」の延長線上にあります。(フィードバック制御は、機械から出力される信号を入力側へフィードバックすることによって両者を比較し、その差から両者を一致させるような修正を行うことにより最適な動きを促す技術)。
AIが自ら最適な動きを学習することに成功した今回のプロジェクト成果を踏まえると、例えば次のようなリアルタイム制御を必要とする機械設備をはじめとした、あらゆる領域への展開が見込めます。
・建設用クレーンの操作制御
・工場プラントでの化学合成工程における火力制御
・空調設備の自動制御
・製造系ロボットの制御
<日本のグローバルニッチトップ産業への展開>
AIの研究開発に関してはアメリカや中国の台頭が取り沙汰されますが、AIの産業応用という点では各国横並びの状態と言えます。その点で、日本の産業からAIを活用した世界的なイノベーションが誕生する可能性は十分にあり、その典型的な分野が、日本が誇るグローバルニッチトップ(GNT)産業で、今回の制御系AIはその代表的な例だと考えています。
Laboro.AIは、こうしたGNT分野の企業の方々とのAI活用を積極的に推進・支援し、日本から世界に対するイノベーション創出に貢献してまいります。

- <ご参考(※AI・人工知能分野を専門とする方向け)>
アルゴリズムの詳細
今般のカスタムAIでは、3つのアルゴリズムからアプローチを実施しています。
① Q-Learning
:古典的な強化学習のアルゴリズム。ある状態である行動をとる価値(状態行動価値)を全ての状態と行動の組み合わせについて保持するテーブル関数を学習する。
② DQN(Deep Q-Network)
:Q関数のテーブル関数をニューラルネットワークに置き換えた学習を行う。価値関数から行動を決定。行動の種類が多い場合に困難を生じる。
③ Actor-Critic
:DQNは価値関数の学習により行動を改善するが、Actor-Criticは価値関数と方策関数を同時に学習する。行動が連続値で表現される場合に有効である。
- 株式会社 Laboro.AIについて
<会社概要>
社 名:株式会社Laboro.AI(ラボロ エーアイ)
事 業:機械学習を活用したオーダーメイドAI開発、およびその導入のためのコンサルティング
所在地:〒104-0061 東京都中央区銀座8丁目11-1 GINZA GS BLD.2 3F
代表者:椎橋徹夫(代表取締役CEO)・藤原弘将(代表取締役CTO)
設 立:2016年4月1日
H P : https://laboro.ai/

このプレスリリースには、メディア関係者向けの情報があります
メディアユーザーログイン既に登録済みの方はこちら
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像
- 種類
- 商品サービス
- ビジネスカテゴリ
- システム・Webサイト・アプリ開発建設・土木
- 関連リンク
- https://laboro.ai
- ダウンロード
