株式会社EpicAI、日本語特化のプロンプトインジェクション対策モデル「Epic-Guard-JP-4B」を開発:OpenAI/gpt-oss-safeguardらを上回るスコアを達成
日本語1.3万件規模の攻撃データセットを新規構築し、日本語のプロンプトインジェクションに高精度なLLM防御を実現

近年、生成AIの活用が広がる一方、ユーザー入力を悪用してモデルの挙動を逸脱させる「プロンプトインジェクション攻撃」が国内外で問題視されています。既存の研究やデータセットは英語圏を中心としており、日本語特有の表記揺れ・敬語表現・全角半角の混在などに起因する攻撃手法に対応した防御モデルは十分に存在していません。
その課題に応えるべく、当社は日本語環境を前提としたプロンプトインジェクション防御モデルの構築に取り組みました。
取り組み概要
本モデル開発では、日本語環境で発生するプロンプトインジェクション攻撃を高精度に検知するため、データセット整備からモデル学習まで一貫して独自に構築を行いました。特に、日本語特有の表記揺れや敬語表現、全角・半角混在といった要素が攻撃検知を困難にしている点に着目し、それらに対処可能な高品質データとモデルの確立を目指しました。
日本語13,000件規模の攻撃データセットを新規構築
まず、GitHub上からライセンスを確認した20件のリポジトリを抽出し、そこに含まれる英語の攻撃プロンプトを日本語に翻訳して統合し、すべてのデータを安全に日本語化しました。
さらに、日本語特有の攻撃手法(ゼロ幅スペースの挿入、敬語表現を利用した誘導、全角・半角や文字種の混在など)に対応するため、7カテゴリ560例の追加サンプルを新たに生成。これにより、日本語攻撃データは 最終的に7,063件 の規模となりました。また、攻撃/非攻撃をバランスさせる目的で、通常のQAタスクを件生成し、総計13,623件のデータセットを構築しています。

日本語判別モデルの構築
構築したデータセットを用い、Qwen3-4Bをベースとした日本語プロンプトインジェクション検知モデルを開発しました。タスクは攻撃(injection)/非攻撃(clean)の二値分類とし、LoRAによる軽量ファインチューニングを適用しています。
学習では、総データ約3,438件を対象に、LoRAを用いた学習を実施。テストでは、Accuracy・Precision・Recall・F1スコアなどを指標に評価しました。
F1スコア0.99という従来モデルを大幅に上回る性能
本モデルは、既存のプロンプトインジェクション対策モデルと比較して、顕著に高い検知性能を示しました。特に、以下のようにF1スコア0.99という高い精度を達成しています。
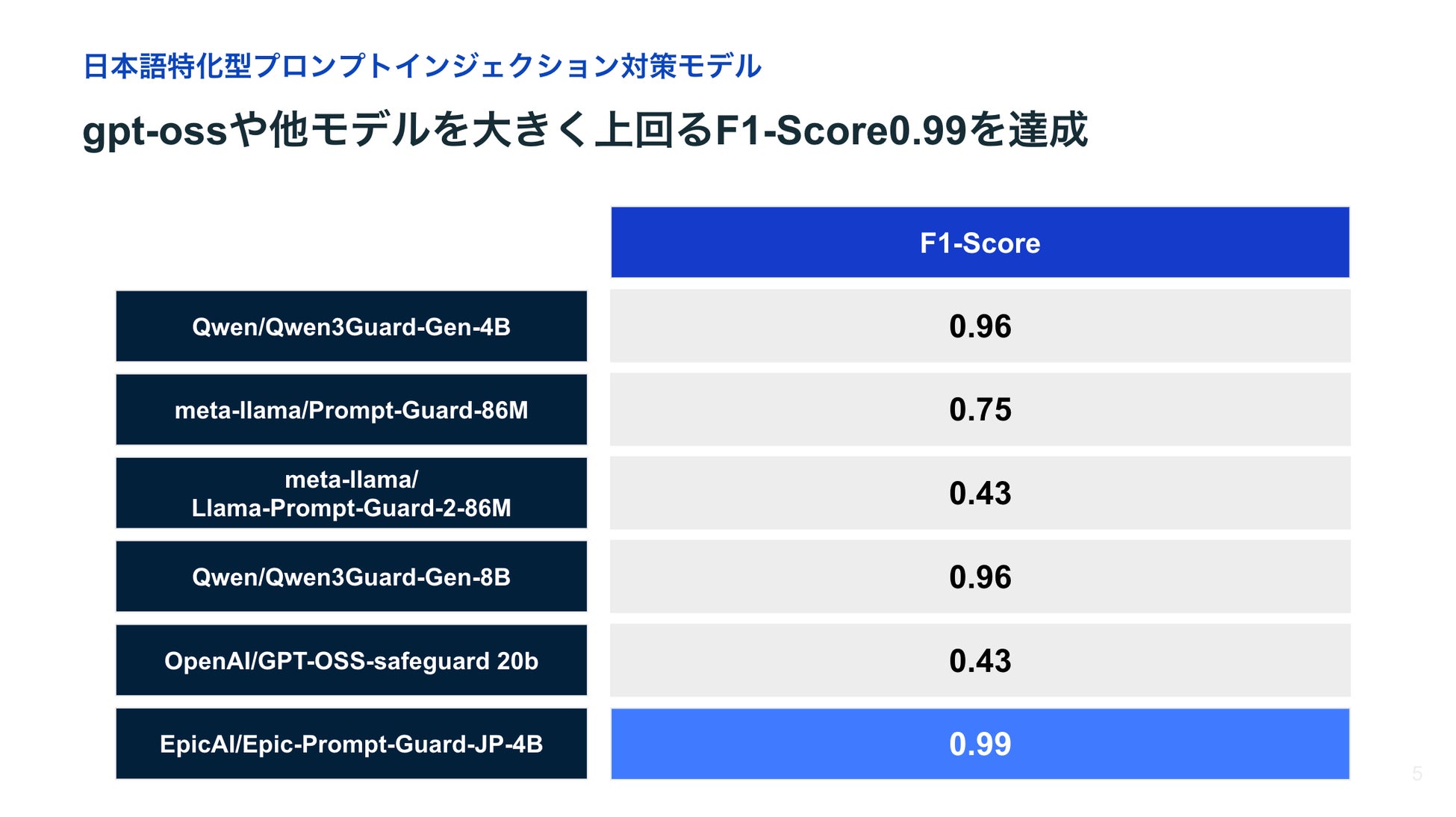
既存の英語中心のGuardモデルは、日本語特有の表記揺れや敬語表現、全角・半角の混在といった攻撃表現を十分に扱えず、過検知あるいは過少検知が目立ちました。一方、当社モデルは日本語表現の多様性に合わせてデータセット設計を行った結果、高い性能を発揮しています。
今後の活用とEpic-Guard-JP-4Bの利用について
Epic-Guard-JP-4Bは順次モデルとして提供して参ります。詳しくはお問い合わせください。
また本研究を踏まえ、以下の取り組みを進めていく予定です。
-
攻撃タイプの多ラベル分類
「社会的エンジニアリング」「表記揺れ攻撃」など、攻撃種類別の早期検知 -
軽量モデル(Edge向け)の提供
インフラや医療機器など、閉域環境での運用を想定 -
実運用LLM/AI Agentとのリアルタイム連携
生成前後のプロンプト監査レイヤーとして統合 -
業界別テンプレートの提供
金融向け禁止表現辞書、医療向けガイドライン反映強度設定など
弊社は官公庁・重工業・金融・医療といった「高信頼性産業」におけるセキュアなAI Agentの活用に向け、「Epic Prompt Guard-JP 4B」の更なる改善/チューニングの提供や、セキュリティモデルの開発、それらを組み込んだAI Agent/LLMソリューションを提供しております。
ご関心のある方はHPよりお問い合わせください。
すべての画像