TV録画から自動構築した音声コーパス『 LaboroTVSpeech 』を開発&公開
日本語音声コーパスとして最大規模 2,000時間の音声データから構成
<今回のポイント>
✔︎ 日本語音声コーパスとしては最大規模の約2,000時間のデータ
✔︎ TV番組に含まれる音声と字幕データから、音声コーパスを自動構築するシステムを開発
✔︎ 既存の音声コーパスより優れた誤認識率を達成し、商用の音声認識APIにも匹敵する精度を確認

オーダーメイドによるAI・人工知能ソリューション『カスタムAI』の開発・提供およびコンサルティング事業を展開する株式会社Laboro.AI(ラボロエーアイ、東京都中央区、代表取締役CEO椎橋徹夫・代表取締役CTO藤原弘将。以下、当社)は、当社の研究開発として、TV録画から長時間音声と字幕テキストを抽出して音声コーパスを自動構築する独自システムを用い、約2,000時間に及ぶ音声データから構築した日本語音声コーパス『LaboroTVSpeech(ラボロティービースピーチ)』を開発し、学術研究用に無償公開いたしました。
LaboroTVSpeechは、B-CASカードによるアクセス制限がないワンセグ放送を利用しており、複数ジャンルの計9,142番組のTV録画から抽出した約2,000時間の音声データから構成されています。研究用途として代表的な日本語話し言葉コーパス(CSJ:約600時間)や新聞記事読み上げ音声コーパス(JNAS:約90時間)など、これまで公開されている日本語音声コーパスと比較しても最大規模のものです。当社比較実験の結果では、LaboroTVSpeechで構築した音声認識モデルが従来の研究用日本語音声コーパスで構築したモデルを凌ぐ誤認識率となり、さらに商用で提供されている主要な他社製クラウド音声認識APIにも匹敵する誤認識率を確認いたしました。
なお、本年12月2日(水)・3日(木)に開催される(一社)情報処理学会 第246回自然言語処理・第134回音声言語情報処理合同研究発表会にて、LaboroTVSpeechについての報告を実施予定です。
本件について詳細は、以下もしくはこちらのPDF版プレスリリース(全文)からご確認いただけます。
https://prtimes.jp/a/?f=d27192-20201113-2182.pdf
- 背景 ― これまでの音声認識モデルと音声コーパス(※1)
一方、日本語の音声コーパスについては、研究用として代表的な日本語話し言葉コーパス(CSJ※2)で約600時間、新聞記事読み上げ音声コーパス(JNAS※3)で約90時間など、英語と比較すると十分なデータの音声コーパスが存在しているとは必ずしも言えないのが現状です。
この背景としては、音声コーパスの構築に際して書き起こしや録音作業など、人手による手間やコストがかかることが理由として挙げられます。その対応として、これまで人手の作業を伴わず自動的にデータ収集を行う手法が模索されてきました。その一つの方法として挙げられるのが、テレビ放送を用いた音声コーパスの自動構築です。多くのテレビ番組には字幕情報が付与されているため、音声と字幕のテキスト情報を時間的に紐付けることで、コーパスを自動構築できる可能性が示されてきました。


|
●字幕の表示時間と実際に音声が発生される時間にはズレがあり、特にニュースなどの生放送番組では音声が発せられてから字幕が表示されるまで10秒以上の遅れを伴う場合がある。 ●バラエティ番組などでは発話の一部が字幕ではなく,いわゆるテロップとして映像上に付与される場合があるが、テロップはテキストとして情報を取得できないため、データとして取得される字幕テキスト上では複数の単語や文章が不規則に削除されているような状態となる。 |
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
※1 コーパスとは、言語情報を大量に集積したデータベースのことを指します。※2 国立国語研究所、情報通信研究機構 (旧通信総合研究所)、東京工業大学が共同開発した話し言葉データベース。
※3 日本音響学会が公開している新聞記事を読み上げた音声コーパス。
- LaboroTVSpeechについて
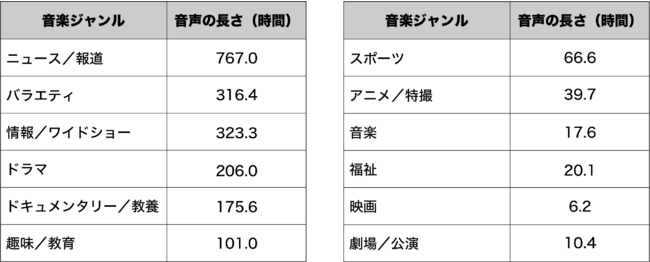
(LaboroTVSpeechを構成する番組ジャンルと音声の長さ)
LaboroTVSpeechは、当社が独自開発したシステムにより構築しています。具体的には、テレビ番組の長時間の音声データと、その不完全な書き起こしである字幕データの時間的な対応関係を抽出する手法である準教師付きデコーディング(lightly-supervised decoding)と呼ばれる手法をベースとしています。これにより、本来であればテレビ番組のデータから音声と字幕がセットになって抽出されるべきところ、先のような何らかの問題で対応した情報として取得できなかった場合に、準教師付デコーディングによる音声と字幕の対応関係の抽出を繰り返し行うことで、一度対応が取れなかった区間からも可能な限りデータ抽出を行う仕組みを採用しています。
なお、LaboroTVSpeechについては、本年12月2日(水)・3日(木)に開催される(一社)情報処理学会 第246回自然言語処理・第134回音声言語情報処理合同研究発表会にて報告を予定しています。
- LaboroTVSpeechの比較実験について
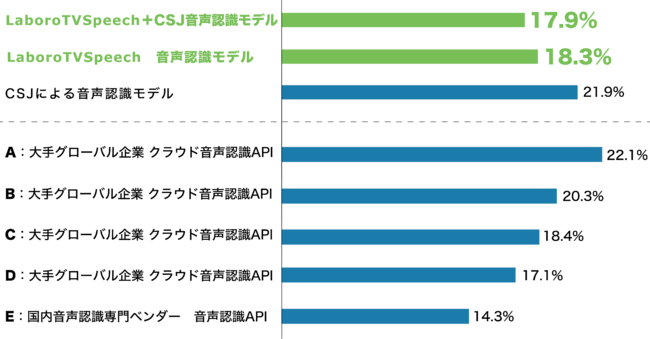
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
※4 YouTube上のプレイリスト「TEDx talks in Japanese」に含まれる動画から、1万発話文の音声とその字幕データを取得した上で、人手で修正を加えたものです。
※5 クラウド音声認識API の評価は、全てデフォルトの音響モデル及び言語モデルを用いて実施しています。上記の結果は、実環境での音声認識システムの性能とは異なる場合があります。
- LaboroTVSpeechの今後の可能性

- LaboroTVSpeechの利用について
営利企業における研究開発用途や商用目的での利用をご希望の場合は、当社ホームページのお問い合わせフォーム(https://laboro.ai/contact/other/)からのご相談をお願いしております。
- 株式会社 Laboro.AIについて
<会社概要>
社 名:株式会社Laboro.AI(ラボロ エーアイ)
事 業:機械学習を活用したオーダーメイドAI開発、およびその導入のためのコンサルティング
所在地:〒104-0061 東京都中央区銀座8丁目11-1 GINZA GS BLD.2 3F
代表者:代表取締役CEO 椎橋徹夫・代表取締役CTO 藤原弘将
設 立:2016年4月1日
URL : https://laboro.ai/

このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像
