Nejumi LLMリーダーボードがアップデートされ、安全性評価など多数の評価を追加
最新の評価データセットを活用した、日本語LLM評価のベストプラクティス
関連リンク:
Nejumi LLM リーダーボード 3:http://nejumi.ai
Nejumi LLM リーダーボード3からの考察ブログ:https://note.com/wandb_jp/n/nd4e54c2020ce
W&Bミートアップ #14 in 東京:https://wandb.connpass.com/event/321967/
今回のアップデートの背景
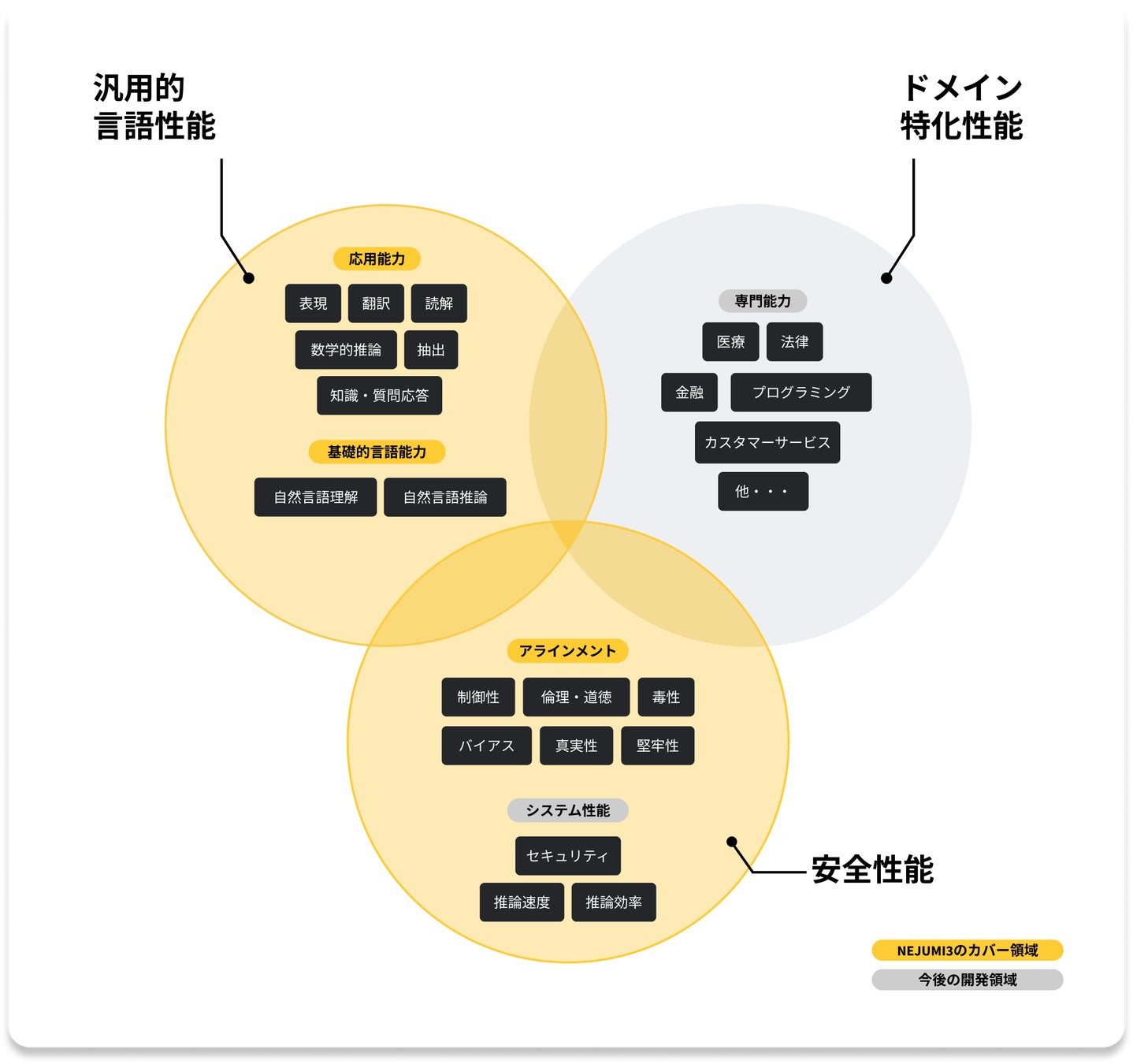
Weights & Biasesでは、2023年7月からLLMモデル評価を行う「Nejumi LLMリーダーボード」にて、当社の提供するLLMOpsプラットフォーム「WandB」を使い、LLMモデルの日本語性能比較を行うためのベンチマークを開発し、幅広いモデルの評価を国内外のAI開発・提供者に提供してきました。
LLM開発の勢いは依然速いペースで進んでおり、モデル性能の急速な向上が続いています。また、LLM技術の社会・事業実装に向けた取り組みも進んでおり、それに伴ってモデルおよびアプリケーションの評価にはこれまで以上に幅広い内容が求められています。本年4月に発表された「AI事業者ガイドライン」においては、AIの開発・提供者が透明性の高い開発体制を構築し、リスクへの対策を講じることなどを通じて、AIガバナンスを確保することの重要性が指摘されています。
このような背景を受け、今回のアップデートに先立ってリリースされたホワイトペーパー、「大規模言語モデルを評価するためのベストプラクティス」では最新のLLM評価手法を網羅的に調査した結果をまとめています。これに基づいて行われたこの度のNejumiリーダーボードのアップデートにおいては評価内容に二つの大きなアップデートを行ないました。
用途主体の評価:これまでの評価データの枠組み主とする主体の評価から利用目的別にLLMの性能を把握することを容易にするためのフレームワークを構築
安全性能の検証:「制御性」「毒性」「偏見」など、人間の価値観と一致した出力を行えるか(アラインメント)を評価するためのフレームワークを構築
これらの評価フレームワークは引き続きオープンソースで共有され、企業のユーザーが結果を公開せずにプライベートな環境で評価を行うことも可能です*。
*プライベート評価にはWeighs & Biasesエンタープライズライセンスが必要です
関連リンク:
ベンチマーク評価実行用コードの公開場所:https://github.com/wandb/llm-leaderboard/tree/main
「大規模言語モデルを評価するためのベストプラクティス」:http://wandb.me/jp-llm-eval-wp
AI事業者ガイドライン:https://www.meti.go.jp/press/2024/04/20240419004/20240419004.html
今回のアップデートの詳細
1.評価の更なる多角化: Nejumi LLMリーダーボード3では、従来のllm-jp-eval (言語理解) とJapanese MT-Bench (言語生成) で評価していた 「汎用的言語能力」に加え、「制御性」「毒性」「偏見」など、人間の価値観と一致した出力を行えるかを評価する「アラインメント」という新たな軸を導入しました。日本語のアラインメント評価においては、LCTGやJBBQ、JcommonseMoralityなど、公開されている最新データセットを最大限取り入れました。
2.実用性を重視した評価体系: 実際のユースケースを想定して、タクソノミーの整理を行い、結果を集計しています。
3.Few-shotプロンプトの導入: 偶然に同様の設問形式を学習したことでフォーマットへの対応力に差がついてしまい、スコアに如実な差がついてしまうことへの対応として、従来のZero-shotに加えてFew-shotプロンプトによる評価を導入しました。最終スコアはZero-shot評価とFew-shot評価の平均によって算出されています。
4.高速で統一された評価プロセス: vLLMを活用することで、評価プロセスの大幅な高速化を実現しました。さらに、推論インターフェースの統一により、様々なモデルの結果追加がより容易になりました。これにより、企業でのプライベート利用もしやすくなりました。また、直近対応するモデルが増えているchat templateをベースとした推論を導入し、モデルごとに適した推論ができるような工夫も行なっています。
インタラクティブにモデル評価結果を分析
前バージョンに引き続き、本リーダーボード公開ページでは、WandB製品の強みを活かして、よりインタラクティブに評価結果を表示し、その場で分析することが可能です。例えば、理解能力と生成能力のバランスを評価したり、二つのモデルの違いがどのような事例で発生するのかを分析したりすることが可能になります。具体的にはインタラクティブに比較対象モデルを選択し、WandB Table機能を用いて、平均スコアではなく、一問ずつの深掘を行うことができます。
Weights & Biases Japan株式会社について
Weights & Biases Japan株式会社は、エンタープライズグレードのML実験管理およびエンドツーエンドMLOpsワークフローを包含する開発・運用者向けプラットフォームを販売する日本法人です。WandBは、LLM開発や画像セグメンテーション、創薬など幅広い深層学習ユースケースに対応し、NVIDIA、OpenAI、Toyotaなど、国内外で50万人以上の機械学習開発者に信頼されているAI開発の新たなベストプラクティスです。
W&B社日本語ウェブサイト:https://wandb.jp

このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像