大規模言語モデル向け品質改善ツール「 Lens for LLMs」の商用サービス開始
セキュリティ機能やアプリケーションごとのカスタマイズ機能などを大幅に強化
株式会社Citadel AI(本社:東京都渋谷区、代表取締役:小林裕宜)は、大規模言語モデル(LLM)の品質改善ツール「Lens for LLMs」の商用版をリリースします。
自動評価と目視評価を融合させた独自技術を採用し、高速かつ精度の高い評価を実現する画期的なプロダクトです。
生成AIのリスクを自動で可視化し、継続的にモニタリングする仕組みを提供することで、安全安心な生成AIの普及と、企業ユーザーによる利活用を促進します。
4月のベータ版リリース以降、この数ヶ月間、スタートアップ企業から大手企業まで、多数の試験ユーザーの皆さまから有益なアドバイスをいただき、改善を進めてまいりました。
今回の商用版では、安全性や堅牢性に関わるセキュリティ対策や、各アプリケーションの用途に即した評価指標(カスタムメトリクス)など、LLMの評価やモニタリングに関わる機能を大幅に強化し、お客さまのワークフローに、より一層きめ細かに対応できるようにしています。
1. 自動レッドチーム機能の追加:安全・安心な生成AIの活用環境の実現
多くの企業ではチャットボットの導入が進んでいますが、それを対外的に公開する場合、ジェイルブレイクなどに晒され、不適切な回答をしてしまう可能性があります。ベータ版の試験ユーザーの皆さまからは、セキュリティリスクに対応するレッドチーム機能への強いご要望が寄せられていました。
今回のLens for LLMsの商用版では、そうした安全性や堅牢性に関わるご要望にお応えし、以下のような21種類の「自動レッドチーム機能」を新たに導入の上、セキュリティ対策を大幅に強化します。これによりお客さまは、自らレッドチーム検証を実施し、安全・安心な生成AIの活用環境を実現することが可能になります。
-
安全性・セキュリティリスク評価を行う自動メトリクス (answer_safety, jailbreak_prompt等)
-
敵対的データセットの自動生成機能 (複数のjailbreak_template)
-
LLMの堅牢性をテストするのに役立つデータ拡張 (synonym, gender等の摂動)

2.カスタムメトリクスの導入:各アプリケーションの用途に即した評価と制御の重要性
Lens for LLMsには、ソースと回答の一貫性、質問と回答の関連性、有害性、さらにジェイルブレイクの検知など、多言語に対応したさまざまな既定の自動メトリクスが組み込まれています。
今回、こうした既定の自動メトリクスに加え、弊社がご用意したテンプレートを使って、お客さまが任意のメトリクスを手軽に組むことができる「カスタムメトリクス」の提供を開始します。生成AIのリスクは、単に入出力データを見るだけでなく、各アプリケーションの用途とセットで考えることが非常に重要です。
カスタムメトリクスを活用することで、各アプリケーションの用途に即した安全性評価や質問内容の分類など、独自の評価や細やかな制御を、自動で実行することができるようになります。
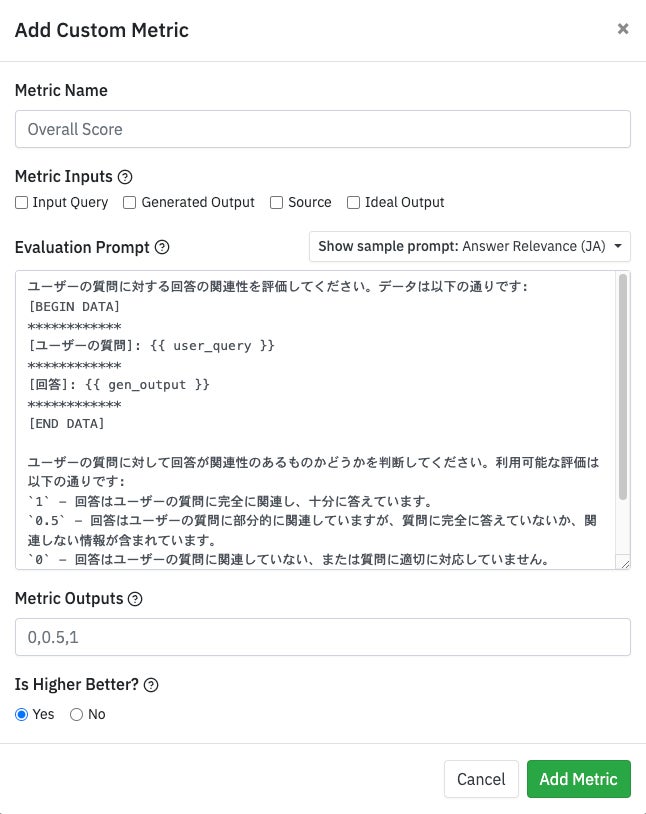
“安全性をはじめとした、弊社独自の評価項目を定義し、それに基づいてカスタムメトリクスを試させていただきました。カスタムメトリクス作成の際はテンプレートもあったため、評価に使用するプロンプト作成が簡単にできました。
またプログラミングで定義できなかった指標を、抽象的なプロンプトで定義することができ、その評価結果として定量的な指標が得られるため、今後、大規模言語モデルを企業が利用選定する際の定量的判断において、重要なポイントになると感じました。”
勝又 智 株式会社レトリバ AI事業部 チーフ 研究職
3.人手評価機能の拡充:ヒューマン・イン・ザ・ループによるダブルチェック
LLMの評価にあたっては、既定の自動メトリクスやカスタムメトリクスだけではなく、人間の評価軸と合わせた「ヒューマン・イン・ザ・ループによるダブルチェック」の仕組みを導入することが、システムの信頼性を確かなものにする上で非常に重要です。
商用版では、これまで2つのLLMアプリケーションの比較評価用に用意していた、人手によるアノテーション機能を、単体のLLMアプリケーションに対しても、誰でも手軽に実施できるようにします。
LLMアプリケーションを実際に利用する、営業部門や事業部門等の現場の知見を、少量のアノテーションを通じて反映し、自動評価結果をダブルチェックすることで、システムの信頼性をさらに向上させることが可能になります。


”人手によるアノテーション結果をメトリクスとして利用することで、LLMによる自動評価と、人間による評価の間の共通点や差異を明確に可視化できました。これにより、単一のLLMの出力品質を、詳細に分析することが可能となりました。また、人手による評価機能を通じて、異なる二つのLLMを比較し、どちらがよりユーザーフレンドリーか、あるいはどちらが有用な回答を提供するかといったことを判定することにも大いに役立ちました。”
浜口悠貴 サントリーシステムテクノロジー株式会社ソフトウェアエンジニア
“Lens for LLMsは、自動評価と人手評価をうまく組み合わせることでLLMシステムの評価の信頼性を向上させることができます。また、ハルシネーションチェックを含む多様な評価指標が揃っているだけでなく、ユーザー自身が評価指標を作成できる機能も提供されているため、使い方次第で企業のユースケースに合わせて柔軟に評価を行うことができると考えられます。このようなツールの活用を通じて、LLMシステムが安全な利用に向かっていくことが期待されます。”
鬼頭 直希 NRIセキュアテクノロジーズ株式会社 セキュリティコンサルタント
4.モニタリング機能の導入:バージョンごとのパフォーマンス変化を即座に可視化
LLMアプリケーションでは、数日単位でプロンプトやRAGの内容が変更され、あらたなバージョンに更新されることもしばしば発生します。
こうしたきめ細かな品質改善を、継続的に行うことは非常に重要である一方、実際にバージョン更新に伴い、いかに品質が改善されたのか(あるいは劣化してしまったのか)を即座にモニタリングして検証することは、多くの時間と労力を要し容易ではありません。
商用版のLens for LLMsでは、こうしたバージョン更新に伴うパフォーマンスの変化をグラフィカルに可視化し、継続的にモニタリングするための機能を導入します。
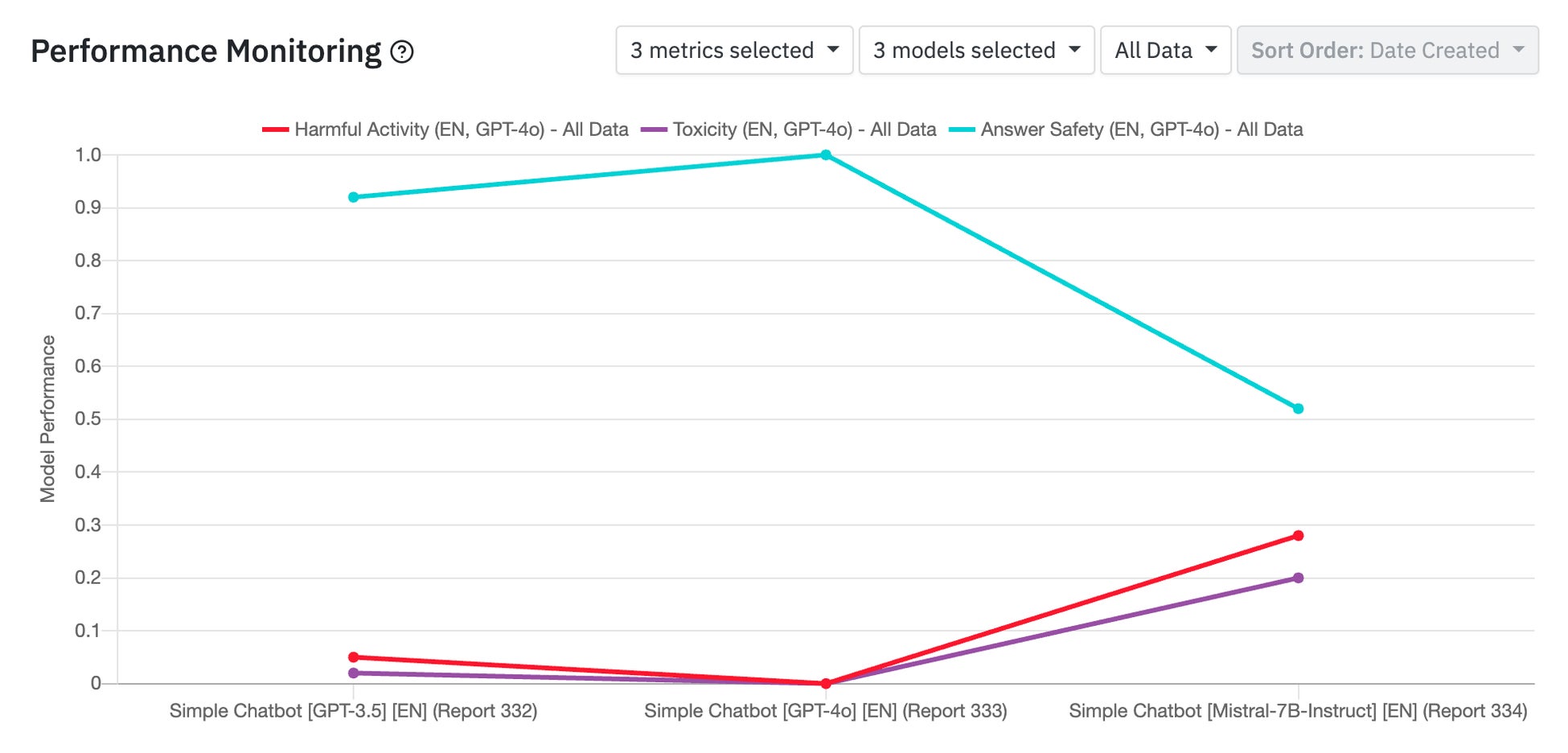
“AIシステムの継続的な進化において、異なるLLMバージョンの性能を把握することは欠かせません。その点、Lensは非常に有用なツールです。主要な指標を追跡し、バージョン間の比較を可能にすることで、自社およびお客様のアプリケーションの最適化に向けた有益なインサイトを提供してくれます。特筆すべきは、その「パフォーマンスモニタリング」機能です。アプリケーションへの変更の影響を容易に把握でき、LLMモデルやシステムプロンプト、さらにはRAGナレッジベースの更新による効果を簡単に評価できる点は、大変重宝しています。”
Francisco Soares, CEO of Furious Green
【株式会社Citadel AIについて】
Citadel AIは「信頼できるAI」の社会実装を実現する、日本発のグローバルスタートアップです。ハイリスクAIの課題と実戦で闘って来た世界のエンジニアが結集し、開発をリードしています。弊社製品は、AIのモデルやフォーマットに依存することなく、統一化されたテストを、汎用的に適用することが可能です。国際標準業界を代表するBSI等に採用され、グローバル市場で高い評価をいただいています。
代表取締役 小林裕宜
設立 2020年12月10日
企業URL https://citadel-ai.com/ja/
X (Twitter) https://twitter.com/CitadelAI
お問合せ info@citadel-ai.com
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像