ジンベイGenOCR、Microsoft Officeファイル(PPTX/Word/Excel)の読み取りに対応

ジンベイ株式会社(本社:神奈川県横浜市、代表取締役:上田英介)は、生成AI×OCRソリューション「ジンベイGenOCR」において、新たに Microsoft Officeファイル(PPTX/Word/Excel)の拡張子サポート を追加したことをお知らせします。これにより、従来のスキャンデータやPDFに加えて、企業が日常的に扱う各種Microsoft Officeファイルからもテキスト情報を直接読み取り、構造化データ化が可能になりました。
▼アップデート情報詳細
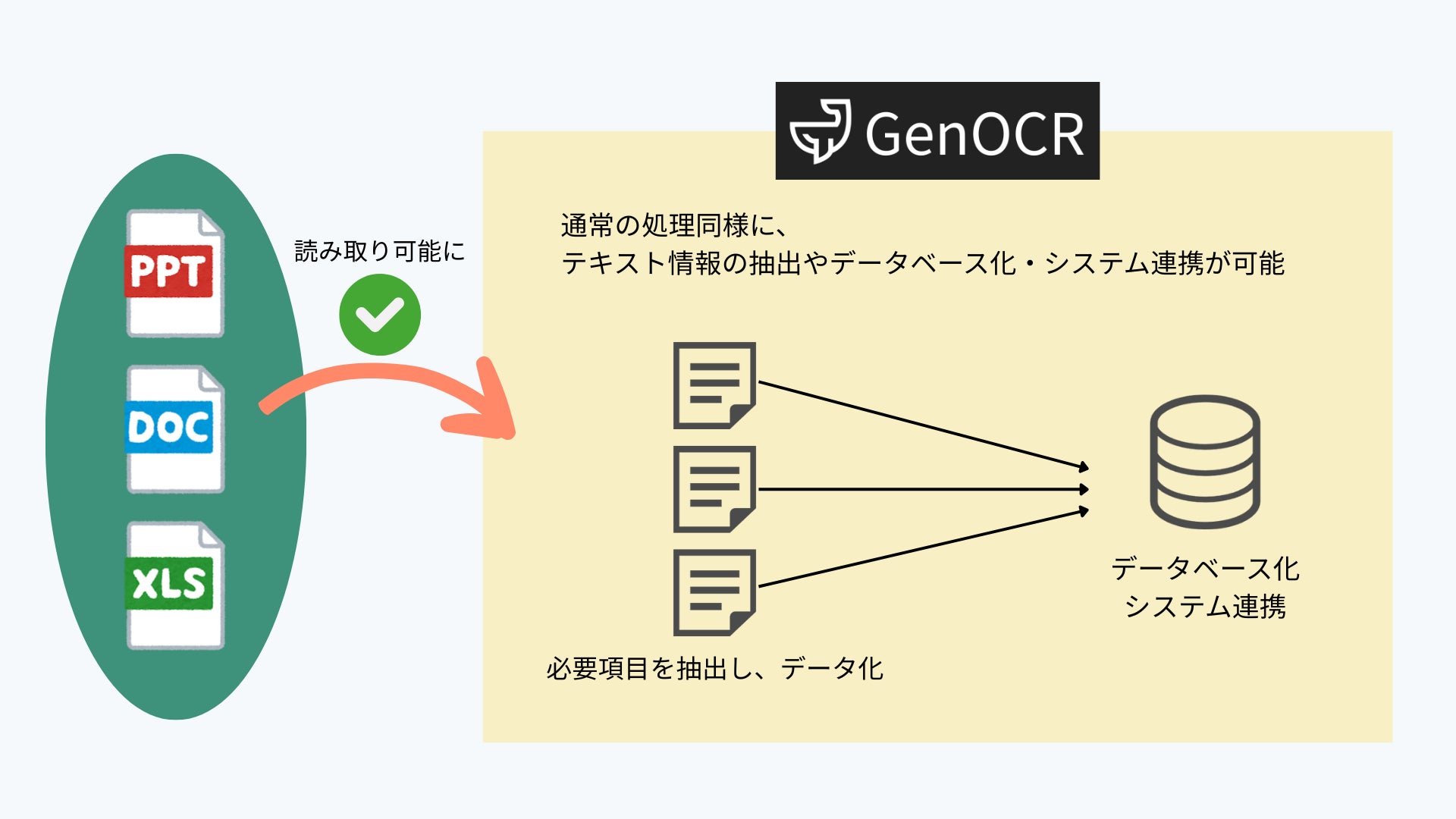
従来、ジンベイGenOCRはスキャン文書や画像、PDFを対象に、OCRと生成AIによるデータ構造化を実現してきました。
今回のアップデートにより、新たに以下のファイル形式に対応します。
・PPTX(PowerPointファイル)
・DOCX(Wordファイル)
・XLSX(Excelファイル)
これらのファイルをアップロードするだけで、テキスト情報を抽出し、OCR処理と同様にデータベース化やシステム連携が可能です。
■特長と注意点
テキスト情報を高速抽出:図表や画像内の情報は対象外とし、あえてテキスト情報に限定することで処理速度を最優先。
10MBまでのファイルサイズに対応:既存の制限と同様、アップロード上限は10MB。大容量ファイルも順次拡張予定。
OCRフローにシームレス統合:既存のPDFやスキャンデータ処理と同じ流れで扱えるため、利用者は形式を意識する必要なし。
▼期待される導入効果
・会議資料(PPTX)の要約やタグ付けを即時に実行
・契約書や稟議書(Word)をそのまま構造化データ化
・請求書・台帳(Excel)を自動で抽出・分類
これにより、「紙」「PDF」「Microsoft Officeファイル」という異なる形式に分散していた社内文書を横断的に扱えるようになり、文書管理や検索性が大幅に向上します。
▼今後の展望
今後は、Microsoft Officeファイル内の画像や表組みの読み取り強化、より大容量のファイルに対応する拡張を予定しています。ジンベイは「紙とデジタルの垣根をなくすOCR体験」を提供し続け、企業のドキュメントDXを推進してまいります。
▼ジンベイGenOCRについて
「ジンベイGenOCR」は、ジンベイが独自に開発した文字認識AIを搭載しているAI-OCRサービスです。従来のOCR技術では困難だった手書き文字や、非定型フォーマットのデータ化を高精度で実現しています。これまで手作業で行っていた退屈なデータ化業務を、ジンベイGenOCRに任せることが可能です。
サービスページ:https://jinbay.co.jp/genocr
■既存のOCRソリューションの課題
・手書き文字や図形・グラフの認識精度が低い。
・設定が煩雑で、使用するまでが大変。
・運用にかかる費用が高い。
■「ジンベイGenOCR」で解決できること
・なぐり書きレベルの手書き文字や、図形・グラフ読み取りにも完全対応。
読み取り精度99%(*)以上を実現。
・事前の設定がほぼ不要で、誰でも使用可能。
・最低価格月額2万円で利用可能。トライアルにも対応。
※読み取り精度、データ入力時間など、上記数値については当社内での検証結果に基づく
■ジンベイについて
ジンベイ株式会社は「働くを変える」をミッションに、最新の生成AI技術を活用した業務DXを推進しています。私たちが提供する「ジンベイ生成AIエージェント」は、各業務プロセスをデジタル化し、過去のデータや社内外のコミュニケーション情報を有効活用することで、生産性向上と企業の成長を支援します。
法人名:ジンベイ株式会社
代表者:代表取締役 上田 英介
所在地:〒220-0072 神奈川県横浜市西区浅間町1-7-1 BIZcomfort横浜西口 C-39
設立:2024年5月24日
事業内容:AI・システム開発、コンサルティング、および関連するサービス
メール : info@jinbay.co.jp
ジンベイGenOCRサービス資料:https://hubs.ly/Q03f2FhC0
すべての画像