レトリバ、最高精度の日本語検索向けテキスト埋め込みモデル「AMBER」を公開
〜日本語の検索精度向上により生成AI活用を加速〜
AI技術で組織の課題解決を支援する株式会社レトリバ(東京都豊島区、代表取締役 田口琢也)は、日本語検索向けのテキスト埋め込みモデル「RetrievaEmbedding - 01 AMBER (Adaptive Multitask Bilingual Embedding Representation)」を公開したことをお知らせいたします。
本モデルは日本語検索用途に最適化されております。これにより、外部データベースの情報を検索して生成AIの出力に反映させる技術であるRAG(Retrieval-Augmented Generation)などにおいて、欲しい情報をより正確に、より速く見つけられるようになります。
本モデルの開発背景
日本企業における生成AIの活用は、欧米と比べてまだ発展途上であり、デジタル赤字やIT分野での競争力低下が懸念されています。
その中でも特に、情報の正確性や最新性を向上させるRAG(Retrieval-Augmented Generation)は、多くの企業で期待されていますが、まだ十分に活用が進んでいません。
その要因の一つとして、RAGの重要な要素であるEmbedding技術*に関して、日本語のモデルが英語に比べて十分に整備されておらず、多くの企業で検索精度が不十分なEmbeddingモデルを使用している点が挙げられます。
その結果、生成される回答の精度が低いという課題が顕在化し、日本企業のAI活用を阻む大きなボトルネックとなっています。
こうした課題を解決するため、レトリバは長年にわたり自然言語処理技術を研究・開発し、磨き上げてきたAI技術をもとに、このたび、最高精度の日本語Embeddingモデルの開発に至りました。

AMBERの特長
AMBERは日本企業における社内検索に適したEmbeddingモデルです。
以下のような特徴があります。
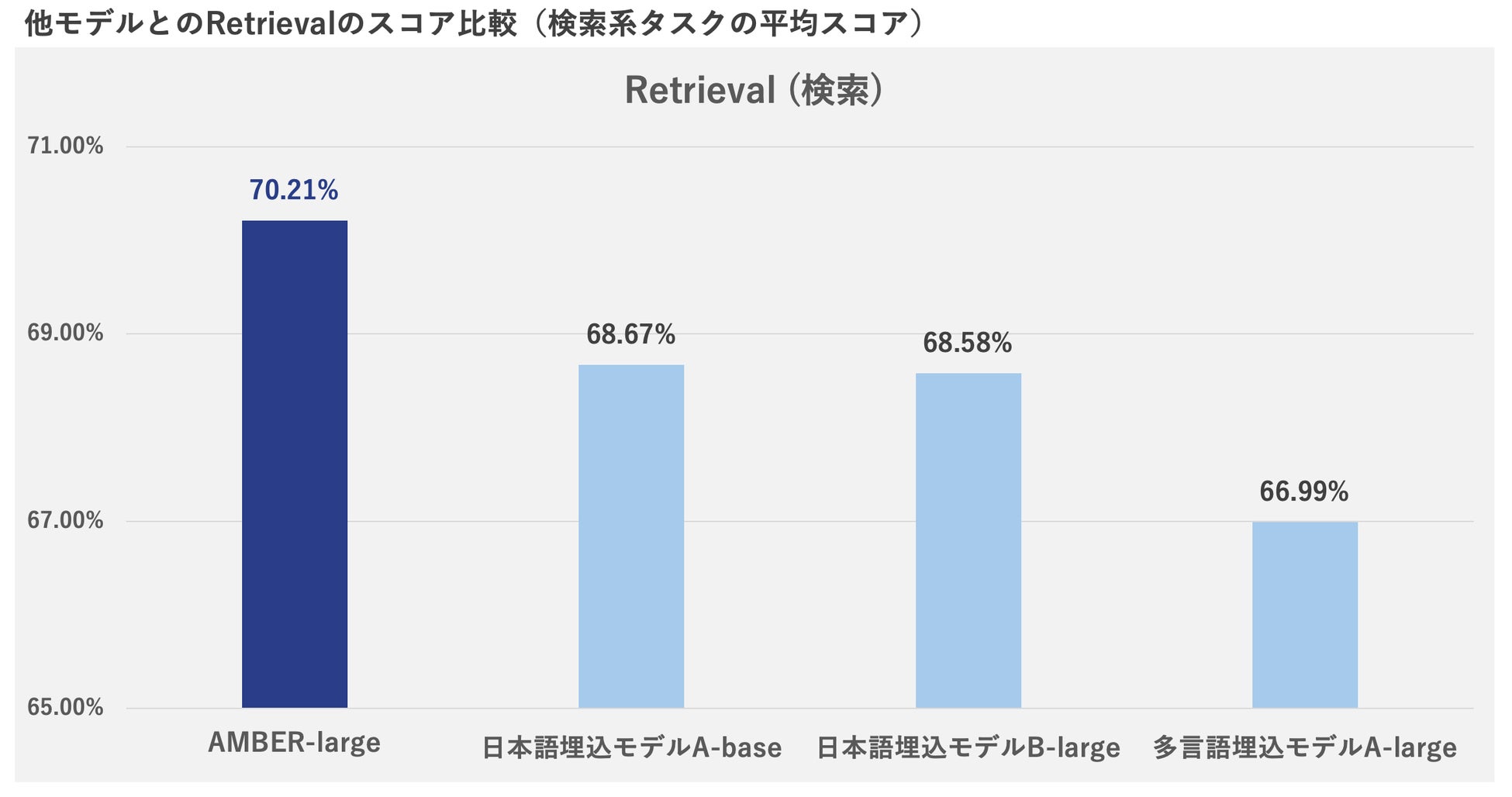
1. 最高精度の日本語検索
AMBERは、実務に適したコンパクトなモデルサイズ(パラメータ500M以下)の中で、日本語検索において最高精度を誇るEmbeddingモデルです。
本モデルは日本語の検索精度を測るテストで、公開されているコンパクトな日本語埋め込みモデルや多言語埋め込みモデルに比べて最も高いスコアを記録しました。
2. 英語を含むドキュメント検索性能
多くの日本企業では、社内のドキュメントに日本語と英語が混在しており、情報検索の際に言語の壁が生じることが少なくありません。
AMBERは、日本語検索において高い精度を実現しつつ、英語の情報も適切に扱うことができるため、業務環境に適したEmbeddingモデルとなります。
AMBERは以下のHugging Face Hubにて公開しており、商用利用可能なライセンスのもと提供いたします。
-
AMBER large:https://huggingface.co/retrieva-jp/amber-large
今後の展開
今後、日本企業のAI活用において「RAG」の重要性がますます高まる中、より優れたモデルの開発に努めてまいります。
また、AMBERをファインチューニングすることで、業界や企業特有の用語に特化した検索モデルの構築が可能です。これを企業とのコラボレーションを通じて実現していきたいと考えています。
株式会社レトリバについて
「AI技術で、人を支援する」をミッションに、自然言語処理と機械学習の技術を武器に、お客様が有するデータ資産の価値を引き出すことによる戦略的AI活用を支援しています。
レトリバという社名には、「Retrieval(検索)」という当社の技術領域と、狩猟犬や盲導犬として活躍するレトリバー犬のイメージの2つの意味を込めています。私たちは狩猟犬のように必要な情報を素早く届け、パートナーとしてお客様に寄り添うことで、AIによる企業活動の変革を支援していきます。
==================================================
本件に関するお問合せ:株式会社レトリバ
担当者:辻 pr@retrieva.jp
==================================================
すべての画像
- 種類
- 商品サービス
- ビジネスカテゴリ
- システム・Webサイト・アプリ開発
- ダウンロード
