Sparticle社が7Bおよび13Bモデルの公開を発表、日本語処理能力向上へ
Sparticle社、日本語LLM開発を加速。革新的なAI技術で日本語処理能力が飛躍的に向上させる
Sparticle社は、2022年11月、OpenAIがインタラクティブな生成型AI「ChatGPT」の潜在能力を素早く認識し、生成型AIの事業拡大を図りました。今年の6月から、彼らはGPT技術を活用して、企業や個人の情報から学習するカスタムAIエージェントの作成を可能にし、「GPTBase」というサービスを提供しています。
Sparticle社は、Amazon Web Services(AWS)ジャパンによるLLM開発支援プログラムパートナーとして選出され、今回のLLM開発は、その一環であるとのことだ。
Sparticleが開発した大規模言語モデル(Llama2-13B-Felo LLM)は、米国のMETAが開発したLlama2に基づいている。Llama-2は3つの異なるサイズで提供されており、それぞれ7B、13B、70Bのパラメータを持っているが、今回、Sparticle社は、この内、日本語および英語データで事前学習を行なった7億パラメータ(7b)及び、13億パラメータ(13b)のベースモデルで、これらのモデルは、業務特化すれば、それぞれ7BはGPT2.0相当、13BはGPT3.5相当となる。また、7bモデルは、オープンソースとして無料公開される。この新しいモデルは、日本語に特化した自然な会話や文章生成の能力を高めることを目指しており、7bモデルは、入出力の長さとして8,192トークンに対応しており、日本語の文章として約4,096文字を一度に処理することができるという。
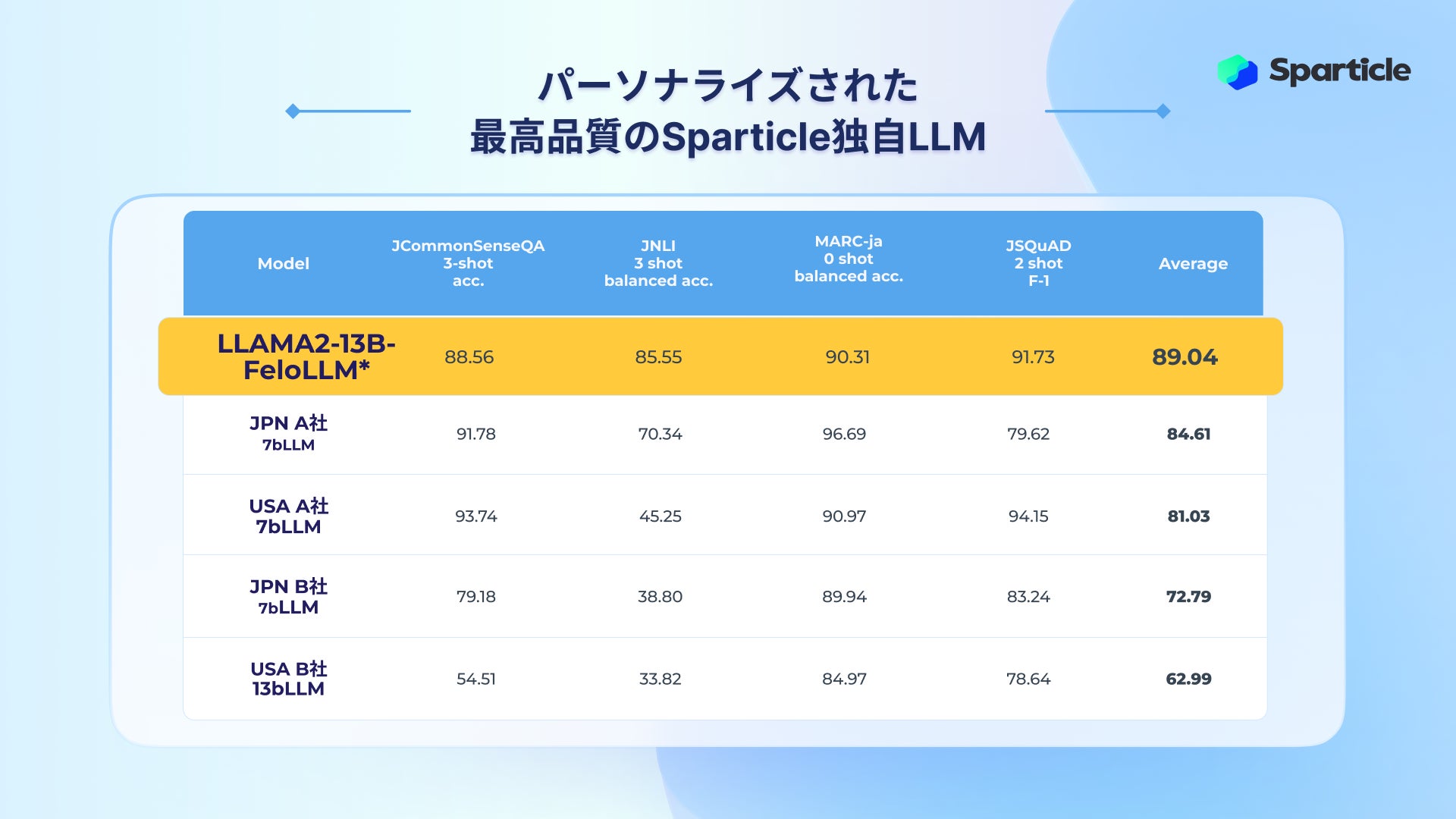
Sparticle社のLlama2-13B-Felo LLM開発では、日本語ベンチマークスコアを公開しており、そのスコアは高く評価され、日本のAI先端企業の日本語向けLLM製品と比較して、20ポイント以上高いスコアを達成している。
Sparticle社は、Llama2-13B-Felo LLMの7Bおよび13Bのバージョンについて、11月中旬から外部検証を可能にする予定で、2024年1月に両バージョン共、リリースを予定している。これにより、外部の研究者や開発者がモデルの性能や応用の可能性を検証できるようになる見込みだ。Sparticle社はこの試験を通じて、モデルの精度や実用性を向上させることに注力している。
Sparticle社は高精度の日本語大規模言語モデルでGPTBaseと組み合わせることで、GPTBaseと組み合わせることで、企業が独自に展開し、データのセキュリティを保護することができるナレッジベースのChatGPTロボットを作るのに役立つ。 企業の既存の知識に基づいて、高精度の知識ベースとなる企業内部展開が実現。

Sparticle社は、日本語LLMの開発において他の関連企業との協力も模索している。彼らの開発チームは、日本語の特性やニュアンスを正確に捉えるための検証作業を継続して行っており、その過程で外部の専門家や研究者からのフィードバックも積極的に取り入れている。
グローバルなIT業界では、生成型AIはモバイルインターネットから約10年後に登場した革命的な変革を意味します。それは人々の生活を根本的に変える可能性を秘めている。
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像