Qlean Dataset、「日本語・1話者・事件犯罪テーマトーク音声コーパスデータセット」を提供開始
〜GENIAC採択企業のVisual Bank、事件・犯罪領域の独り語り音声でASR・NLP・生成AI基盤を支援〜

Visual Bank株式会社(東京都港区、代表取締役CEO 永井真之、以下「Visual Bank」)は、傘下の株式会社アマナイメージズを通じて展開するAI学習用データソリューション『Qlean Dataset(キュリンデータセット)』において、『日本語・1話者・事件犯罪テーマトーク音声コーパスデータセット』の提供を開始しました。本データセットは、事件・犯罪を題材とした一人語りの音声を収録しており、音声認識(ASR)、自然言語処理(NLP)、生成AI基盤モデルの研究・開発に活用できます。
本データセットは、事件・犯罪に関する歴史的事例、制度説明、社会課題などをテーマに、話者が連続的に説明・解説する音声を収録したデータセットです。自然な話題転換や文脈依存の語り、主張整理、エピソード紹介を含む長尺のモノローグ形式で構成されており、台本に依存しない自然発話としての特性を備えています。収録時間は総計約350時間(1音声5分〜40分)、20代〜50代の男女話者の音声で構成しており、学習・検証データとして利用可能な44.1kHzの音声形式(mp3)で提供します。
本データセットは、事件・犯罪領域における説明的・専門的内容を含む自然発話を収録しているため、文脈把握や長尺音声処理、意味理解が求められるAIモデルの性能検証に適しています。業務利用を想定したASR精度向上、生成AIのナレッジ拡張、教育・研究用途での対話モデル評価など、対象分野に応じた幅広い用途で活用できます。
今回提供を開始する「日本語・1話者・事件犯罪テーマトーク音声コーパスデータセット」の概要

|
データ種別 |
音声 |
|
被写体属性 |
20代〜50代の男女 |
|
データ形式 |
mp3 |
|
収録時間 |
計約350時間(1音声約5分〜40分) |
|
音声レート |
44.1kHz |
|
対象のシーン] |
・話者が事件や犯罪のテーマについて連続的に説明・解説するシーン ・長尺の独白・語りかけ形式の自然発話シーン — 日常的な話題展開、主張の整理、エピソード紹介を含む ・台本に依存せず、話者の自然なリズムや間が反映された一人語りシーン — 文脈依存の語り、話題転換、感情の抑揚などを含む |
|
サンプルページ |
「日本語・1話者・事件犯罪テーマトーク音声コーパスデータセット」のユースケースイメージ
【研究用途(アカデミア)】
-
長尺モノローグを対象としたASRモデル研究
事件・犯罪領域に関する説明的音声を用いることで、文脈依存の語り・話題転換を含む日本語ASRモデルの認識性能を検証できます。
-
NLP領域の文脈理解・要約モデルの評価
一人語り形式の長文構造により、意味単位抽出、談話構造解析、要約モデルの評価に利用できます。
【産業用途(企業)】
-
専門領域における音声入力対応AIの高精度化
犯罪・制度説明など専門性のある語彙を含むため、コールセンター向け音声処理、知識ベース検索型AI、ドメイン特化対話AIの精度向上に活用できます。
-
生成AI基盤モデルの音声→テキスト→意味理解処理の強化
自然発話ベースのモノローグデータにより、音声起点での要約生成・説明生成などのマルチモーダル処理の性能向上に寄与します。
【その他実需要(教育・社会実装)】
-
司法・社会教育向けの教材AI研究
事件・犯罪領域の説明音声を素材として、教育向けAIの音声理解・自動説明生成モデルの基礎データとして利用できます。
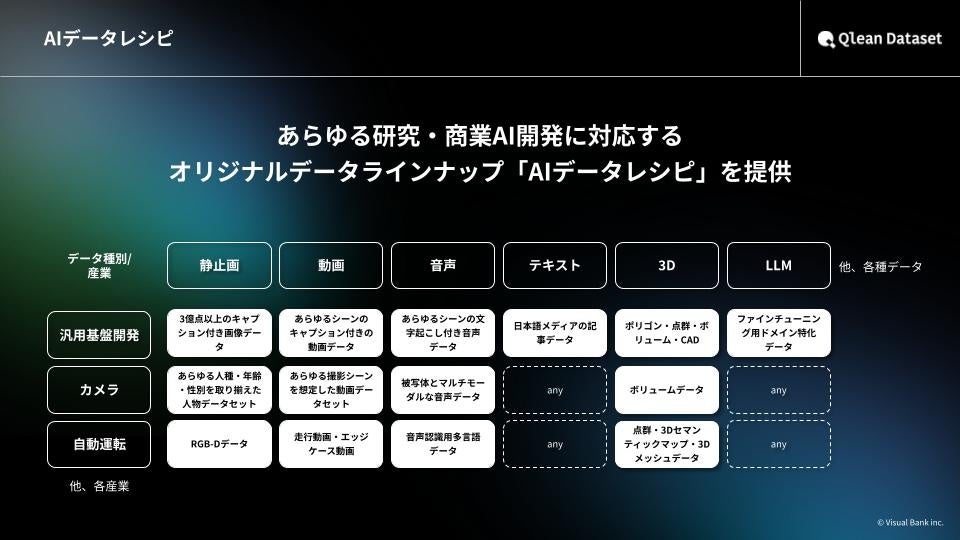
『Qlean Dataset(キュリンデータセット)』について
『Qlean Dataset』は、Visual Bank傘下の株式会社アマナイメージズが提供する商用利用可能なAI学習用データソリューションです。
画像・動画・音声・3D・テキストなど、多様な形式のデータに対応し、研究・商用いずれの用途でも安全に利用できる環境を整備しています。
また、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社をはじめとするデータパートナーとの協業を通じ、業界特化・最新トレンドに即したデータラインナップ「AIデータレシピ」を継続的に拡充しています。
Qlean Datasetは、AI開発現場におけるデータ収集・整備の負荷を軽減し、権利クリアで法的リスクのないAI開発環境の構築を支援します。
▶ Qlean Datasetサイト:https://qleandataset.visual-bank.co.jp/
▶ AIデータレシピ:https://qleandataset.visual-bank.co.jp/lineup
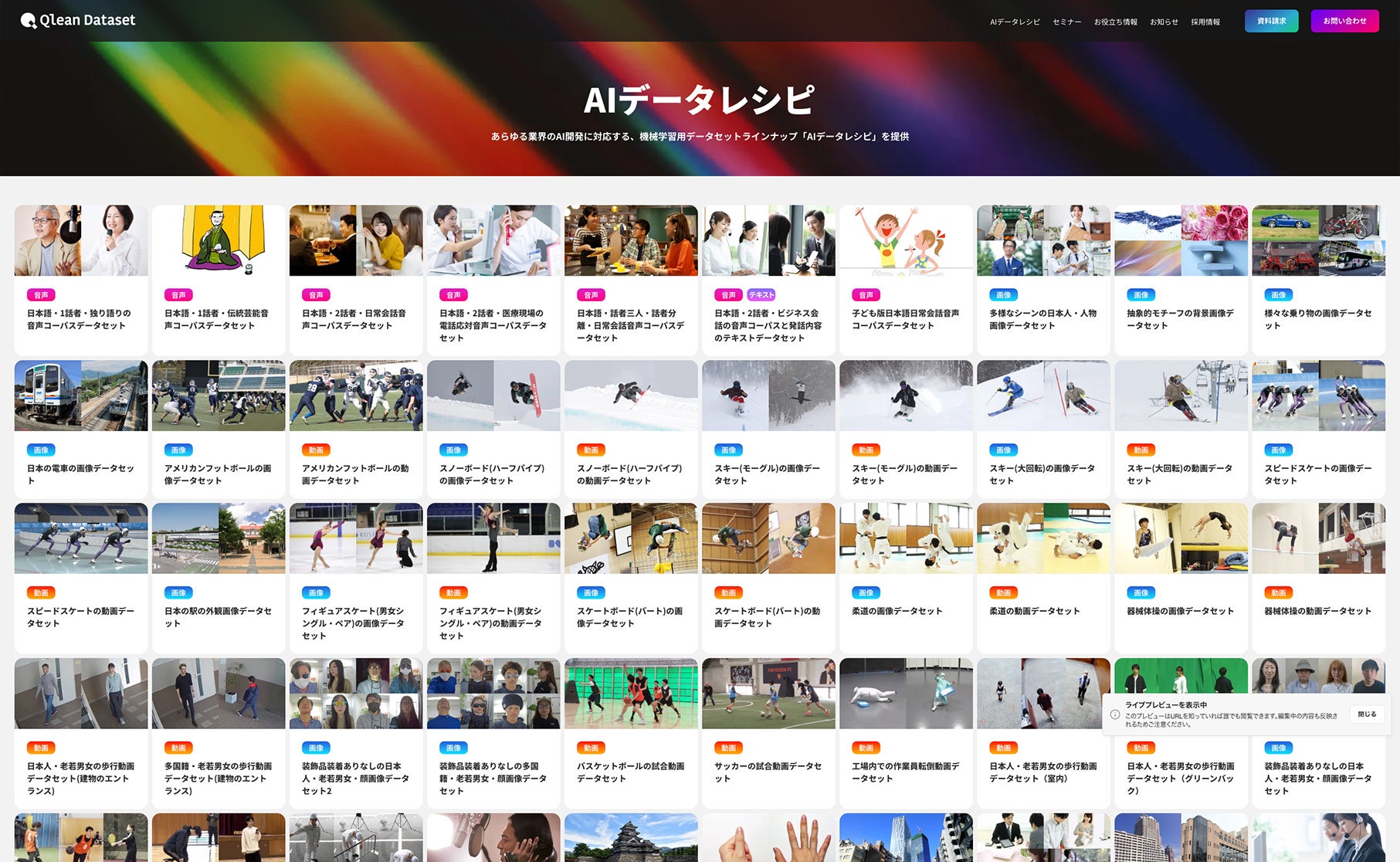


Qlean Datasetの特長
-
すべての被写体から同意取得
-
既存データは最短1日で納品可能
-
カスタム撮影・収録・収集による独自データ構築にも対応
▶ お問い合わせ:https://qleandataset.visual-bank.co.jp/contact
Visual Bank株式会社
AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業として、「あらゆるデータの可能性を解き放つ」をミッションに掲げ事業活動を展開。漫画家の「もっと描きたい!」をサポートするAI補助ツールを提供する『THE PEN』の他、AI学習用データセット開発サービス『Qlean Dataset(キュリンデータセット)』を提供する株式会社アマナイメージズを100%子会社に持つ。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択され、社会実装に向けた取り組みを加速させています。
代表取締役CEO:永井 真之
所在地:〒107-0062 東京都港区南青山7-1-7C-Cube南青山ビル6F
Visual Bank企業URL:https://visual-bank.co.jp/
アマナイメージズ企業URL: https://amanaimages.com/about/
【Translation】

Japanese Crime-Themed Monologue Speech Corpus for ASR and Language Modeling
Long-form natural Japanese speech for ASR training, Conversational AI evaluation, and Educational AI research
Visual Bank Inc.(Minato-ku, Tokyo; CEO: Saneyuki Nagai, hereinafter “Visual Bank”)has released the Japanese Single-Speaker Crime-Themed Monologue Speech Corpus under its AI training data solution Qlean Dataset, operated through its subsidiary Amanaimages Inc.
This dataset contains single-speaker narrative audio on topics related to incidents and crimes, and is designed for applications in Automatic Speech Recognition (ASR), Natural Language Processing (NLP), and the development of generative AI foundation models.
The dataset consists of continuous explanatory monologues covering historical cases, legal and institutional topics, and social issues related to crime.
It is structured as long-form monologue speech that includes natural topic shifts, context-dependent narration, opinion structuring, and episodic explanations.
All recordings are natural speech not dependent on scripted text.
The total recording duration is approximately 350 hours, with individual audio lengths ranging from 5 to 40 minutes.
The dataset includes male and female speakers in their 20s to 50s and is provided in 44.1 kHz mp3 format suitable for training and evaluation.
Because the dataset contains natural speech with explanatory and domain-specific content related to crime, it is suited for evaluating AI models that require contextual understanding, long-form audio processing, and semantic comprehension.
It can be used for improving ASR accuracy in professional environments, extending knowledge for generative AI systems, and evaluating dialogue models in academic and education-oriented research settings.
Dataset Overview – “Japanese Single-Speaker Crime-Themed Monologue Speech Corpus”
|
Data Type |
Audio |
|
Speaker Attributes |
Male and female speakers in their 20s to 50s |
|
Format |
mp3 |
|
Total Duration |
Approx. 350 hours (5–40 minutes per audio) |
|
Sampling Rate |
44.1 kHz |
|
Recorded Scenes |
・Continuous explanations and commentary by a speaker on themes related to incidents and crimes ・Long-form natural monologue speech with topic transitions, argument structuring, and episodic narration ・Unscripted speech reflecting natural rhythm, pacing, and context-dependent storytelling, including emotional variations and topic changes |
|
Sample Page |
Use Case Examples – “Japanese Single-Speaker Crime-Themed Monologue Speech Corpus”
【Academic Research】
-
ASR research on long-form Japanese monologues
The dataset enables evaluation of Japanese ASR systems on context-dependent narration that includes natural topic transitions in the crime domain. -
Evaluation of NLP models for contextual understanding and summarization
Its long-form monologue structure supports tasks such as semantic unit extraction, discourse analysis, and summarization model benchmarking.
【Industrial Applications】
-
Enhancing accuracy of AI systems handling domain-specific speech input
Because the dataset includes specialized vocabulary related to crime and institutional explanations, it can be used to improve speech processing for call centers, knowledge-base search AI, and domain-specific conversational AI. -
Strengthening multimodal generative AI pipelines (speech → text → semantic understanding)
Natural monologue audio enables performance improvement for tasks such as speech-based summarization and explanatory text generation.
【Education / Public-Sector Use】
-
AI research for judicial and social education applications
Explanatory audio on crime topics can be used as foundational material for developing AI systems that support educational content, including automated explanation generation and speech understanding.
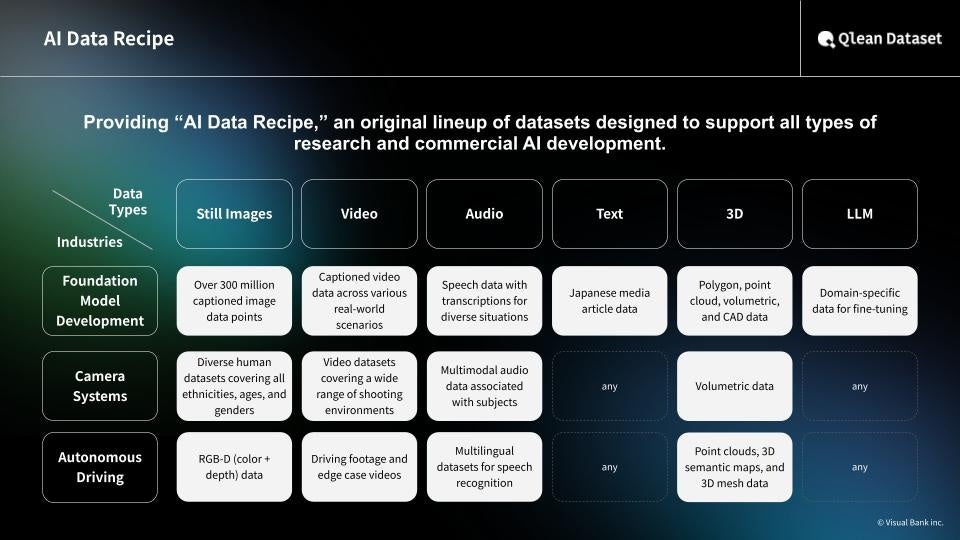
About Qlean Dataset
Qlean Dataset is a commercial-use-ready AI training data solution provided by Amana Images Inc., a subsidiary of Visual Bank Inc.
It supports diverse data types including images, videos, audio, 3D, and text—enabling both research and commercial AI development in a legally safe environment.
Through collaborations with data partners such as Chiba Lotte Marines Co., Ltd. and Toyo Keizai Inc., Qlean Dataset continuously expands its specialized, industry-relevant lineup known as the “AI Data Recipe.”
By reducing the operational burden of data collection and preparation, Qlean Dataset helps build legally compliant and risk-free AI development environments.
▶ Qlean Dataset: https://qleandataset.visual-bank.co.jp/en
▶ AI Data Recipe: https://qleandataset.visual-bank.co.jp/en/lineup
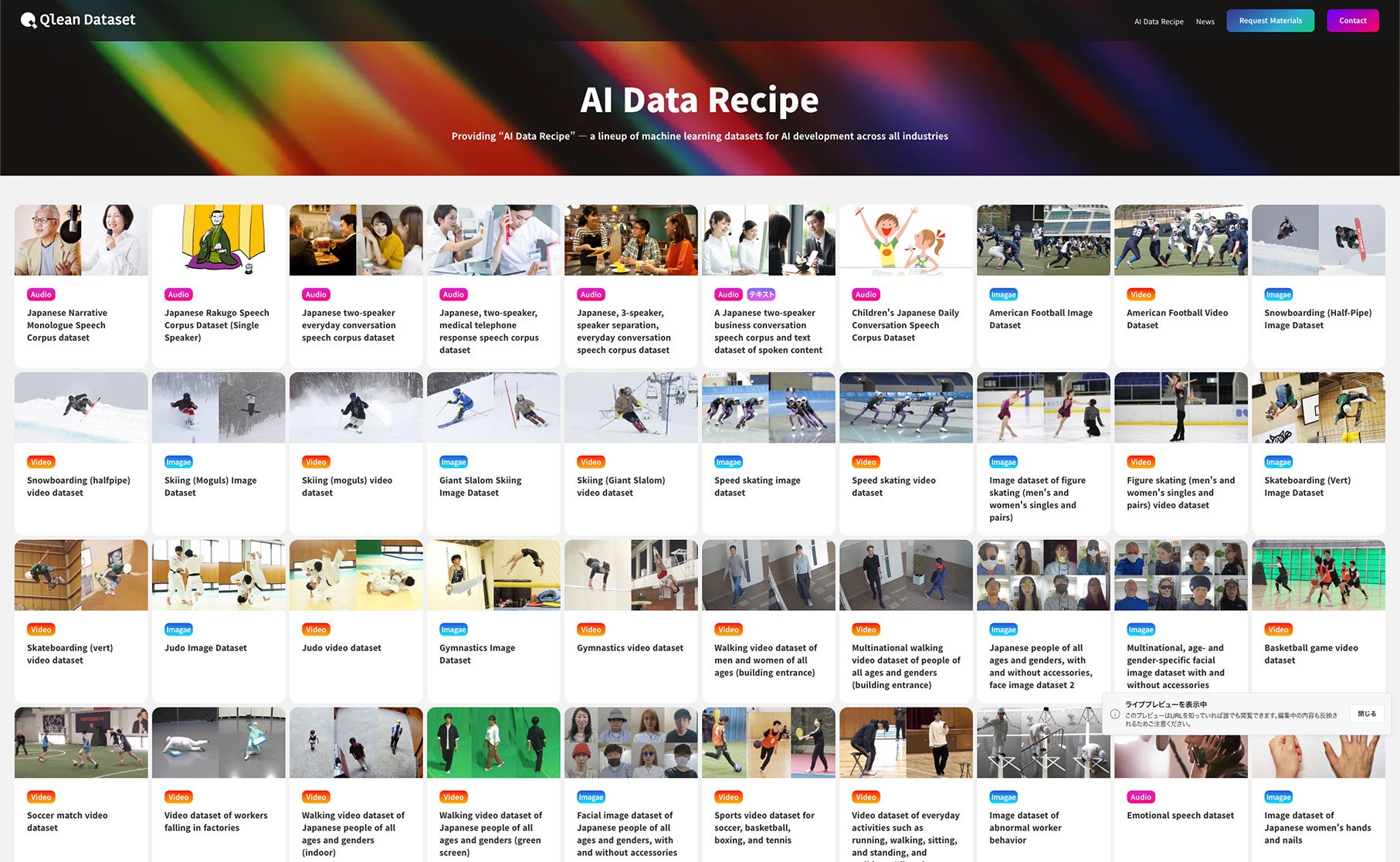


Key Features of Qlean Dataset
-
Full consent obtained from all subjects
-
Existing datasets deliverable within one business day
-
Custom data collection and recording available
▶ Contact: https://qleandataset.visual-bank.co.jp/en/contact
About Visual Bank Inc.
Visual Bank Inc. is a Tokyo-based startup building next-generation data infrastructure to maximize AI development capabilities under the mission, “Unlock the potential of all data.”
The company operates THE PEN, an AI-assisted creative tool for manga artists, and wholly owns Amana Images Inc., which provides the Qlean Dataset service.
CEO: Saneyuki Nagai
Address: C-Cube Minami Aoyama Building 6F, 7-1-7 Minami-Aoyama, Minato-ku, Tokyo 107-0062
Corporate Site: https://visual-bank.co.jp/en
Amana Images: https://qleandataset.visual-bank.co.jp/en/company-overview
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像