NRIセキュア、生成AIを活用したシステム向けのセキュリティ診断サービス「AI Red Team」を提供開始
リスクベースアプローチで大規模言語モデル(LLM)とシステム全体を2段階で診断
■AIが抱える脆弱性とリスク
近年、多くの分野で生成AI、とりわけ大規模言語モデル(LLM)[i] の利用が増加の一途をたどっています。LLM への期待が高まる一方で、LLMには、「プロンプトインジェクション」[ii] 、「プロンプトリーキング」[iii] と呼ばれる脆弱性や、「ハルシネーション」[iv] 、「機微情報の漏洩」、「不適切なコンテンツの生成」、「バイアスリスク」[v] といったリスクが存在することが浮き彫りになってきました(図を参照)。LLM を利活用する企業は、これらの問題を把握し、適切な対策を施す必要があります。昨今、生成AIを用いたシステムやサービスに特化したセキュリティ診断の重要性が叫ばれており、諸外国では独立した外部の専門家による診断の必要性について言及され始めています。
図:LLMを活用したシステムのイメージとリスクの例
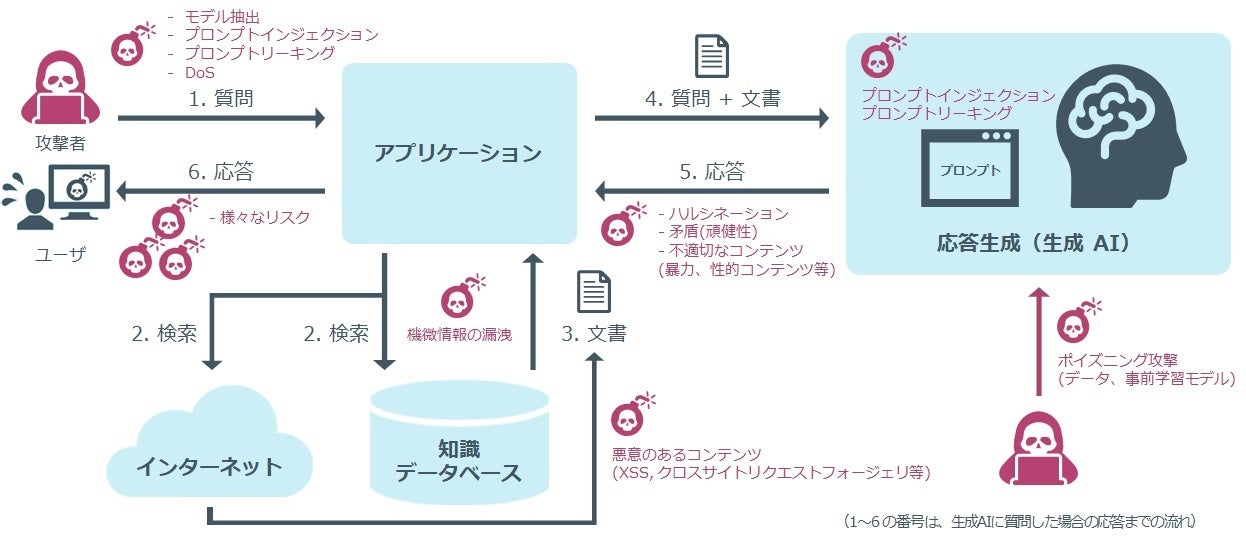
■本サービスの概要と特長
本サービスでは、NRIセキュアの専門家が実際のシステムに擬似攻撃を行うことで、LLMを活用したサービスにおけるAI 固有の脆弱性と、そのAI と連携する周辺機能を含めたシステム全体の問題点を、セキュリティ上の観点から評価します。
AI は、それ単体でサービスとして機能することはなく、周辺機能と連携することで具体的な提供サービスを構成します。そのため、LLM単体のリスクを特定するだけではなく、サービス全体を俯瞰して、「リスクが顕在化した場合に、システムやエンドユーザに悪影響を与えるかどうか」というリスクベースアプローチでも評価する必要があります。
本サービスでは、LLM単体でのセキュリティリスクを洗い出し、LLMを含むシステム全体を評価するという、2段階に分けた診断を実施します。診断の結果、見つかった問題点と緩和策をまとめた報告書を提供します。
本サービスの主な特長は、以下の2点です。
1.独自開発した自動テストと専門家による調査で、効率的・網羅的・高品質な診断を実施
NRIセキュアは、LLM向けDAST [vi]を採用し、自動でテストが可能な診断用アプリケーションを独自に開発しました。このアプリケーションを用いることで、効率的かつ網羅的に脆弱性を検出することができます。さらに、LLMのセキュリティに精通したエンジニアが診断にあたり、自動テストではカバーできない各システム固有の問題点も洗い出し、検出された脆弱性を調査で深く掘り下げます。
2.システムやサービス全体における実際のリスクを評価し、対策コストを削減
生成 AI は、確率的に出力を決定する性質があります。また、内部の動作を完全に理解することは困難であるという特性上、システムの部分的評価で脆弱性を洗い出すには限界があります。NRIセキュアでは、長年培ってきたセキュリティ診断のノウハウを組み合わせることにより、システムやそれが提供するサービス全体を包括的に診断したうえで、AIに起因する脆弱性が顕在化するかどうかを診断します。本サービスは、AI 固有の問題を評価するだけでは対処が難しい「OWASP Top10 for LLM」[vii] にも対応が可能です。
また、仮にAI そのものに脆弱性があった場合、システム全体から見た実際のリスクの程度を評価することによって、実施が難しいAIそのものの脆弱性対応をせずに済むよう、代替の対策案を提示することができます。その結果、対策コストを抑えることが期待できます。
本サービスの詳細については、次のWebサイトをご参照ください。
https://www.nri-secure.co.jp/service/assessment/ai-red-team
NRIセキュアでは、生成AIを利用したシステム等のセキュリティ対策を継続的に支援していくために、本サービスと対をなすサービスとして、AI アプリケーションの定期的なモニタリングを実施する「AI Blue Team」サービスを開発しています。「AI Blue Team」サービスは2024年4月の提供開始を予定しており、現在、PoC(Proof of Concept:概念検証)に参加していただける企業を募集しています。
NRIセキュアは今後も、企業・組織の情報セキュリティ対策を支援するさまざまな製品・サービスを提供し、安全・安心な情報システム環境と社会の実現に貢献していきます。
■ご参考
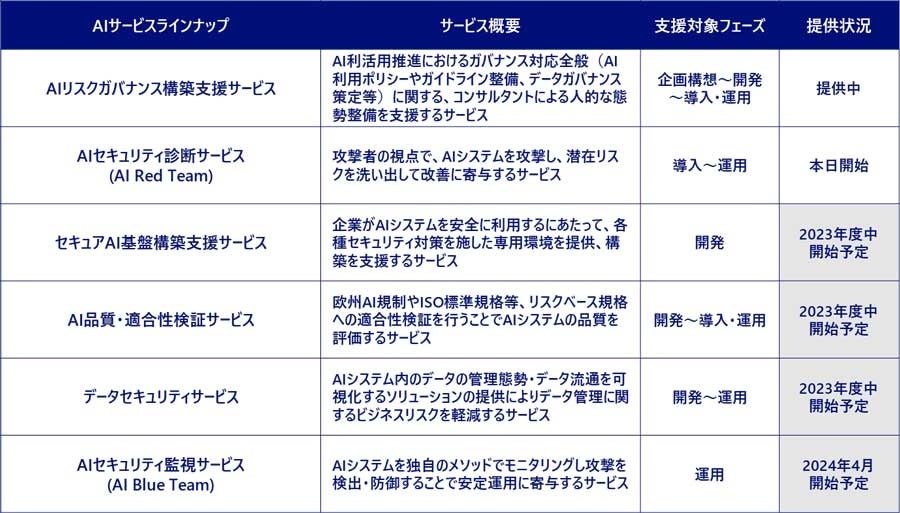
NRIセキュアが提供するAIセキュリティ関連サービスについては、以下のWebサイトおよび一覧表をご参照ください。
https://www.nri-secure.co.jp/service/ai-security
「AIセキュリティ統制支援」サービスの一覧
[i] 大規模言語モデル(LLM):LLMは、Large Language Modelの略で、大量のテキストデータを利用してトレーニングされた自然言語処理モデルのこと。
[ii] プロンプトインジェクション(Prompt injection):主に、攻撃者が入力プロンプトを操作して、モデルから予期しない、または不適切な情報を取得する試みを指す。
[iii] プロンプトリーキング(Prompt leaking):攻撃者が入力プロンプトを操作して、もともとLLMに設定されていた指令や機密情報を盗み出そうとする試みを指す。
[iv] ハルシネーション: AIが事実に基づかない情報を生成する現象のこと。
[v] バイアスリスク:トレーニングデータの偏りやアルゴリズム設計により、偏った判断や予測を引き起こす現象のこと。
[vi]DAST:Dynamic Application Security Testing。実行中のアプリケーションをテストし、潜在的なセキュリティ脆弱性を動的に評価する手法。。
[vii] OWASP Top10 for LLM:世界的なコミュニティである「Open Web Application Security Project(OWASP)」によって作成された、大規模言語モデル(LLM)固有の10大セキュリティリスクのこと。
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像
- 種類
- 商品サービス
- ビジネスカテゴリ
- アプリケーション・セキュリティ
- キーワード
- 人工知能
- ダウンロード