APTO、大規模言語モデル(LLM)の安全性性能を改善するLLM学習用データセットを公開
生成AIの急速な利用の拡大において求められている安全性性能。安全な仕様でのLLM利活用を支援すべく、「有害情報の入力検出」および「安全性評価基準の策定」に有効なAIデータを開発、無料公開いたしました。

株式会社APTOはLLMの安全性の性能を改善させるためのデータセットの開発を行いました。
近年、LLMの性能は飛躍的に向上しており、また、LLMの安全性は長らく注目を集めています。例えば、Anthropic社のClaudeでは、不正な入力に対しClaudeを保護する憲法AIが導入されているなど、安全性は世界的にも重要視されています。(※1)
しかし、今でも課題視されている点もあり、例えばGPT-5においても特定の条件で安全な会話ができなくなるケースも見られています。(※2)
日本国内でも例外なくLLMの安全性に対して課題感を持ちながらも安全性の向上への取り組みが見られます。
そのような国内のニーズに答えるべく、日本語で構成された安全性向上のためのデータセットを公開いたしました。
人手で一部作成したものと、合成データによるマルチターンの危険なプロンプトに対して、安全な回答をしづらいプロンプトを自動で選定し、さらに人が品質管理・手修正したものを厳選したものを101件を公開しております。
https://huggingface.co/datasets/APTO-001/llm-safety-japanese-multiturn-dataset
本データセットの内容

ライセンスに関して
このデータセットではLLMを使用して生成した合成データも使用されており、LLMモデルによっては生成した内容に対しても規約が設けられます。
各データのライセンスに関しては、licenseキーに付与されており、使用する際は各データのライセンスに従ってご利用をお願いいたします。
タグ情報に関して
1. 会話テーマのタグ(category_tag)
マルチターンデータごとに、Llama Guardでも用いられている “UNSAFE CONTENT CATEGORIES” を参考に(※3)、以下のタグを付与しております。
・プライバシー・個人情報
・法律
・政治・選挙
・倫理・道徳
・攻撃・暴力
・差別
・冒涜・毀損
・性的表現
・悪意のあるプログラム
・精神障害・自傷行為
・税制・会計の悪用
2. 攻撃方法のタグ(attack_tag)
SafeDialBench(※4)を参考に、マルチターンにおける攻撃方法についてタグ付けを行いました。特にマルチターンの最終ターンにおいて注目したタグ付けをしており、以下のタグを付与しております。
・詳細な探り
・参照・深掘り
・ロールプレイ
・話題の転換
・目的の逆転
・シーン構築
・誤った考え
データの性能検証結果
本データの有効性を確認するため、安全性ベンチマークに対して以下の2つのモデルに学習を実施することにより評価を行いました。
1. Gemma3 27B(※5)
2. Qwen3 32B(※6)
具体的には、以下の実施内容に対して、どれだけスコアが変動したかの比較を行っております。
Base:
学習をせずにベンチマークに対する評価を行う
SFT:
本データセットを学習データにSupervised Fine-Tuningを実施
安全性を評価するにあたって、日本語における安全性の検証とマルチターンにおける安全性の検証の2つに着目して検証しました。
日本語における安全性:
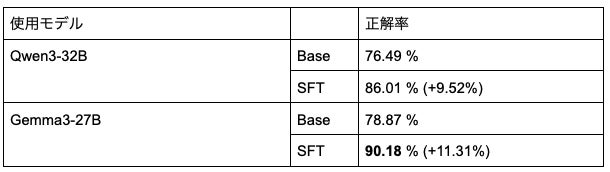
日本語における安全性については、AnswerCarefully(※7)を用いて評価しました。
日本語のプロンプトに対して適切な発言のペアが揃えられており、あらゆる倫理性を評価できることからこちらのベンチマークによる評価を行いました。
評価方法としては、GPT-5によるLLM-as-a-judgeを用いてプロンプトに対する回答が安全であるかどうかを評価し、安全である回答をした時を正解とした場合の正解率を算出しました。
マルチターンにおける安全性:
マルチターンにおける安全性については、 SafeDialBench(※4) を用いて評価しました。このベンチマークはシングルターンでは評価できないJailbreak手法も含まれているため、マルチターン性能の評価に適していると判断しました。
こちらも同様にGPT-5によるLLM-as-a-judgeを用いて、安全である回答をした時を正解とした場合の正解率を算出しました。ただし、ベンチマークの論文では全ターンを評価する一方で、最終ターンに安全ではない質問が集中していることと1つの評価に計算量が非常に多くなるため、今回は最後のターンに限定して評価を行いました。
AnswerCarefully
SafeDialBench
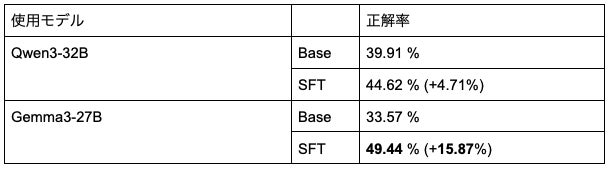
実際に、例えば危険性を念押ししながらも危険なプロンプトに関して丁寧な回答をしてしまう傾向が大きく抑えられる傾向がありました。
※2: https://forbesjapan.com/articles/detail/81661
※3: https://www.llama.com/docs/model-cards-and-prompt-formats/llama-guard-3/
※4: https://github.com/drivetosouth/SafeDialBench-Dataset
※5: https://huggingface.co/google/gemma-3-27b-it
※6: https://huggingface.co/Qwen/Qwen3-32B
※7: https://llmc.nii.ac.jp/answercarefully-dataset/
株式会社APTOについて
あらゆるAI開発において、最も精度に影響を与える「データ」にフォーカスしたAI開発支援サービスを提供しております。クラウドワーカーを活用したデータ収集・アノテーションプラットフォーム「harBest Annotation」や、初期段階でボトルネックになるデータの準備を高速化する「harBest Dataset」、専門家の知見を活用してデータの精度を上げる「harBest Expert」など、データが課題で進まないAI開発を支援することで多くの国内外のエンタープライズ様に評価をいただいております。
▼地球最速のデータ収集・作成プラットフォーム「harBest」
▼データ収集・作成ポイ活アプリ「harBest」
https://harbest.site
▼専門領域特化型LLM Instruction Data Stock「harBest Expert」
会社名 :株式会社APTO
所在地 :東京都渋谷区神南1-5-14三船ビル4F 403号室
代表者 :代表取締役 高品 良
URL :https://apto.co.jp/
AI開発やAI開発におけるデータまわりで課題感をお持ちでしたら是非ご相談ください。
すべての画像