通信建設業界向け安全支援マルチモーダルAIの研究を開始 〜視覚・言語融合モデルによる新たな安全支援DXの実現をめざす〜
NTT東日本株式会社(以下、NTT東日本)は、通信建設現場の安全性と業務効率の向上をめざして危険作業検知AIの開発に取り組んでいますが、2025年10月より、視覚と言語を融合したマルチモーダル生成AI技術を活用した業界特化型VLM(Vision-Language Model:視覚言語モデル)の研究開発を開始します。現場の作業中の映像を生成AIが理解することで、安全確認の精度向上や不安全行動の自動検知、作業報告の効率化を図り、業務のDXを加速させます。
1. 本取り組みの背景と目的
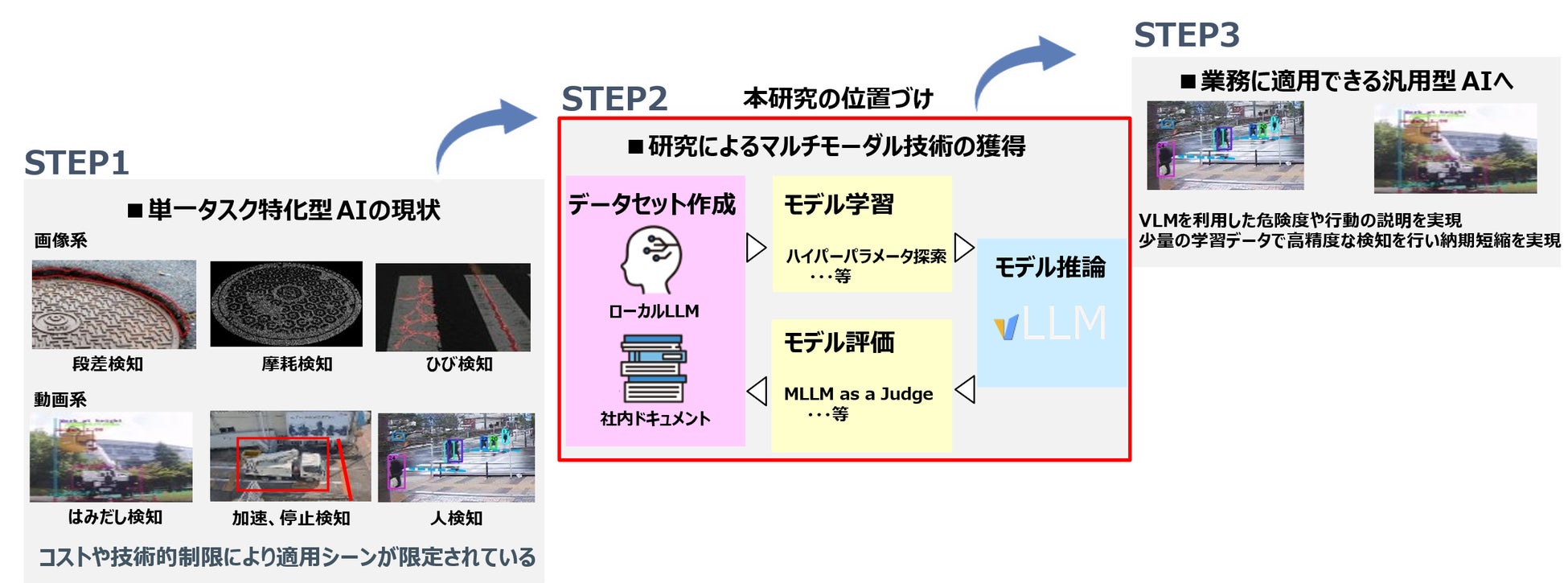
AIの社会実装が進む中、NTT東日本はこれまで、通信建設現場の安全管理業務に物体検知AIを活用した危険作業検知AIを導入し、約5,000台のネットワークカメラを運用することで、不安全行動の検知や遠隔見守りを実現しました。さらに、90%以上のAI判定の精度と約70%の稼働削減を達成し、業務効率の向上とリスクの低減に取り組んできました。しかし、従来のAIモデルでは、複雑な現場状況の文脈理解や、作業内容に応じた柔軟な判断が難しいという課題が残っています。
本研究では、画像とテキストの両方を理解できるVLMを活用し、これまで困難だった現場の状況説明や作業指示の自動生成を可能にすることで、安全確認の精度向上を高め、業務プロセスの高度化を図ります。さらに、作業時間の短縮や確認精度の向上により、安全管理業務の効率を従来比で約30%向上させることをめざします。

2. 取組概要、実施事項など
① 合成データ生成による高品質データセット構築
精度の高いAIモデルの学習をするためには、十分な質と量のデータセットを集めることが必要という課題があります。NTT東日本は、通信建設現場での約5年間にわたるAIの屋外運用により、少量のデータでも多様性のある教師データを選定することで高精度なモデルを構築するノウハウを獲得しています。本研究では、社内業務知識と画像情報を組み合わせたVQA(Visual Question Answering)形式のデータセット作成に取り組みます。特に、LLM(Large Language Model)による合成データ生成手法を活用して高品質なデータセットを効率的に構築する予定であり、LLMのプロンプト設計を工夫し、現場の業務文脈に即した高品質なVQAデータセットを作成していきます。
② VLMのファインチューニングによる最適化
マルチモーダルAIであるVLMをファインチューニングすることで、通信業界に特化したVLMを構築します。学習手法は、フルパラメータやLoRA(Low-Rank Adaptation:効率的なファインチューニング手法)を比較検討し、約720億パラメータ級のモデルの学習と評価に取り組みます。また、現在の危険作業検知AIは優先度の高い8種類(作業者、バケット、車両など)のみに対応している物体検知AIであるため、不安全な行動やヘルメットをはじめ装備品の未着用の検知など、より複雑な状況に対応していくことで、約16種類に適応領域の拡大をめざします。
③ マルチモーダルAIにおける評価手法の確立
独自の業界や業務におけるマルチモーダルAIの評価事例は少ないため、LLMによる自動評価手法である『LLM as a Judge』や自然言語処理の『ROUGE』などの指標をマルチモーダル評価に拡張していきます。さらに、安全管理の専門知識をもとにした独自の評価データセットを作成し、評価手法を確立することで精度を検証予定です。
3. 今後の予定
2025年度中に研究を完了し、その後、見守りや安全指導を行う現場での実用化に向け、現場での有効性を検証していきます。また、本取り組みの成果は自社業務のDXに活用し、そこで培った成果を地域のお客さまにも提供することで、社会課題の解決に貢献していきます。NTT東日本は、先端技術の社会実装を通じて、人間とAIが共創する社会の実現をめざしていきます。
4. 本件に関するお客さまからの問い合わせ先
NTT東日本 先端テクノロジー部 デジタル技術部門 AI技術担当
Mail:snm-dg-ai-gm@east.ntt.co.jp
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像