楽天、日本語に最適化した新たなAIモデルを発表
- 新しい大規模言語モデルと楽天初の小規模言語モデルにより効率化を実現し、AIアプリケーション開発の促進を目指す -
楽天グループ株式会社(以下「楽天」)は、Mixture of Experts(MoE)(注1)アーキテクチャを採用した新しい日本語大規模言語モデル(以下「LLM」)「Rakuten AI 2.0」と、楽天初の小規模言語モデル(以下「SLM」)「Rakuten AI 2.0 mini」の2つのAIモデルを本日発表しました。両モデルは、AIアプリケーションを開発する企業や技術者などの専門家を支援することを目指しており、来春を目途にオープンソースコミュニティに向けて公開予定です。
「Rakuten AI 2.0」は、2024年3月に公開した日本語に最適化した高性能なLLMの基盤モデル「Rakuten AI 7B」を基に開発した8x7BのMoE基盤モデル(注2)です。本LLMは、8つの70億パラメータで構築した「エキスパート」と呼ばれるサブモデルで構成されています。トークンはルーターによって選定された最も適した2つの「エキスパート」に処理されます。それぞれの「エキスパート」とルーターは共に高品質な日本語と英語の言語データを用いた継続的な学習を行っています。
楽天が初めて開発したSLM「Rakuten AI 2.0 mini」は、15億パラメータの基盤モデルです。本SLMは、内製の多段階データフィルタリング、アノテーションプロセスを通じてキュレーションおよびクリーンアップされた広範な日本語と英語のデータセットで最初から学習されており、テキスト生成において高性能かつ高精度な処理を実現しています。
楽天グループのChief AI & Data Officer (CAIDO)であるティン・ツァイは次のようにコメントしています。
「楽天では、AIは人々の創造性と効率性を高めるソリューションであると考えています。今年の3月には、様々な課題を解決するためにAIテクノロジーを活用し、国内の研究開発支援を目的とする、高性能な日本語LLM『Rakuten AI 7B』を発表しました。今回開発した日本語に最適化したLLMと楽天初となるSLMは、高品質な日本語データや革新的なアルゴリズム、エンジニアリングにより、従来以上に効率性が高いモデルです。これは、日本の企業や技術者などの専門家がユーザーに役立つAIアプリケーションを開発することを支援するための、継続的な取り組みにおける重要な節目となります」
■「Rakuten AI 2.0」: 高効率な先進モデル構築
「Rakuten AI 2.0」は、入力トークンに対して最も関連性の高い「エキスパート」を動的に選択する高度なMoEアーキテクチャを採用しており、計算効率と性能を最適化します。本LLMは、8倍規模の高密度モデルに匹敵する性能を発揮しますが、消費計算量においては1/4程度に抑えることができます(注3)。
パフォーマンス向上
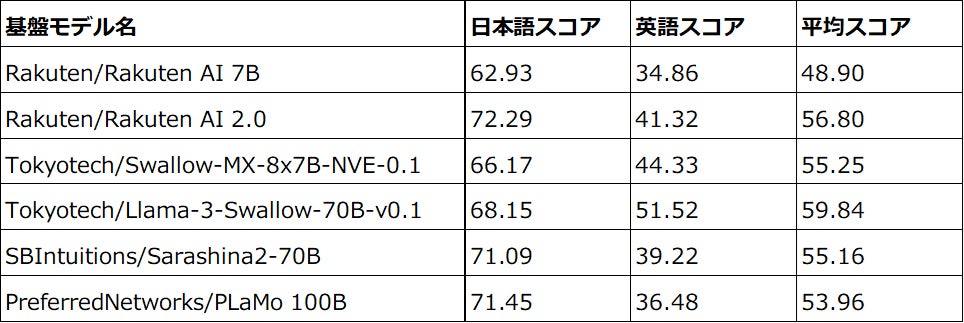
楽天は、LM-Harness(注4)を使用して日本語と英語の能力測定を行うモデル評価を実施しました。リーダーボードは、対象言語の特性を反映した広範な自然言語処理および理解タスクに基づいて言語モデルを評価しています。「Rakuten AI 2.0」の平均日本語性能は、「Rakuten AI 7B」と比較して8つのタスクで62.93から72.29に向上しました。
■「Rakuten AI 2.0 mini」: 実用的なアプリケーション向けのコンパクトかつ効率的なモデル
本SLMは、コンパクトなモデルのためモバイル端末に導入でき、データをリモートサーバーに送信することなく自社運用することが可能となります。汎用アプリケーションに使用される大規模モデルと比べ、SLMはプライバシーの保護、低遅延、コスト効率が求められる特定のアプリケーションに適した形で活用できます。
楽天グループのAIエンジニアリング統括部のジェネラルマネージャーであるリー・ションは次のように述べています。
「今回、新たなLLMを発表できることを非常に嬉しく思います。『Rakuten AI 2.0』はMoEアーキテクチャを活用することで、従来モデルと比較して大幅にコストを削減しながら高性能な処理を行うという大きな進化を遂げました。本LLMは、類を見ない多様性と効率性を提供できるため、日本語モデルの新基準となるでしょう。一方、『Rakuten AI 2.0 mini』はコンパクトかつ優れたモデルであり、エッジベースのSLMに革命を起こすことができると考えています。私たちのチームはこれらの開発に全力を注いでおり、今後もAIの力で日本のビジネス体験を向上させることを目指していきます」
既存の基盤モデルである70億パラメータの「Rakuten AI 7B」の事前学習では、楽天が設計した内製のマルチノードGPUクラスターを拡張することで、大規模で複雑なデータを使用した事前学習プロセスを高速で実現することができました。楽天は最新のLLMおよびSLMをオープンなモデルとして提供することで、オープンソースコミュニティへの貢献を目指すと共に、日本語LLMのさらなる発展に寄与していきます。そして、自社で最新のLLMモデルの開発を継続することにより、知見やノウハウを蓄積し、「楽天エコシステム(経済圏)」の拡大に取り組みます。
楽天は、AI化を意味する造語「AI-nization(エーアイナイゼーション)」をテーマに掲げ、さらなる成長に向けてビジネスのあらゆる面でAIの活用を推進する取り組みをしています。今後も豊富なデータと最先端のAI技術の活用を通じて、世界中の人々へ新たな価値創出を目指してまいります。
(注1)Mixture of Expertsアーキテクチャは、モデルが複数のサブモデル(エキスパート)に分割されているAIモデルアーキテクチャです。推論および学習中は、最も適したエキスパートのサブセットのみがアクティブ化され、入力処理に使用されることで、より汎用的で高度な推論を行うことができます。
(注2)基盤モデルは、大量のデータで事前学習され、その後特定のタスクやアプリケーションに微調整できるモデルです。
(注3)以下の方法で、MoE LLMアーキテクチャにおけるアクティブエキスパートとエキスパートの比率に基づく計算を行っています。
https://arxiv.org/abs/1701.06538
(注4)2024年10月から12月にかけてLM Evaluation Harnessで実施された評価テストの結果。以下のコミットからのデフォルトタスク定義を使用。
https://github.com/EleutherAI/lm-evaluation-harness/commit/26f607f5432e1d09c55b25488c43523e7ecde657
日本語評価のために考慮したタスクは以下を参照ください。
英語評価のために考慮したタスクは以下を参照ください。
https://huggingface.co/docs/leaderboards/en/open_llm_leaderboard/archive
https://github.com/EleutherAI/lm-evaluation-harness/blob/main/lm_eval/tasks/leaderboard/README.md
以 上
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像