楽天、日本語に最適化した大規模言語モデルと楽天初の小規模言語モデルを提供開始
- 業界最高水準のスコアで効率化を実現し、国内のAIアプリケーション開発の促進を目指す -
楽天グループ株式会社(以下「楽天」)は、Mixture of Experts(MoE)(注1)アーキテクチャを採用した新しい日本語大規模言語モデル(以下「本LLM」)「Rakuten AI 2.0」と、楽天初の小規模言語モデル(以下「本SLM」)「Rakuten AI 2.0 mini」の2つのAIモデルを本日提供開始しました。2024年12月に発表した両モデルそれぞれについて、基盤モデル(注2)と同モデルを基にしたインストラクションチューニング済モデル(注3)を提供します。全モデルは、Apache 2.0ライセンス(注4)で提供されており、楽天の公式「Hugging Face」リポジトリ(注5)からダウンロードすることができます。
■LLMを人間の嗜好を近づけるための革新的な手法
「Rakuten AI 2.0」基盤モデルのファインチューニングでは、最新の研究成果である SimPO (Simple Preference Optimization with a Reference-Free Reward)(注6)を活用してアライメントの最適化を行いました。従来のRLHF(Reinforcement Learning from Human Feedback)やDPO(Direct Preference Optimization)と比較して、SimPOはシンプル、安定的、効率的という利点を兼ね備えており、モデルを人間の嗜好に合わせてファインチューニングするための費用対効果が高く、実用的な代替手段となっています。
■最高水準の日本語性能
楽天は、会話形式や指示形式のデータにて基盤モデルをファインチューニング後、インストラクションチューニング済モデルを評価するために幅広く使用されているベンチマークであり、特に会話能力と指示追従能力を測定するために使われている日本語版MT-Bench(注7)を使用してモデル評価を行いました。「Rakuten AI 2.0」インストラクションチューニング済モデル、「Rakuten AI 2.0 mini」インストラクションチューニング済モデル、および他の日本初のオープンモデルとの比較スコアは、以下の表(注8)の通りです。
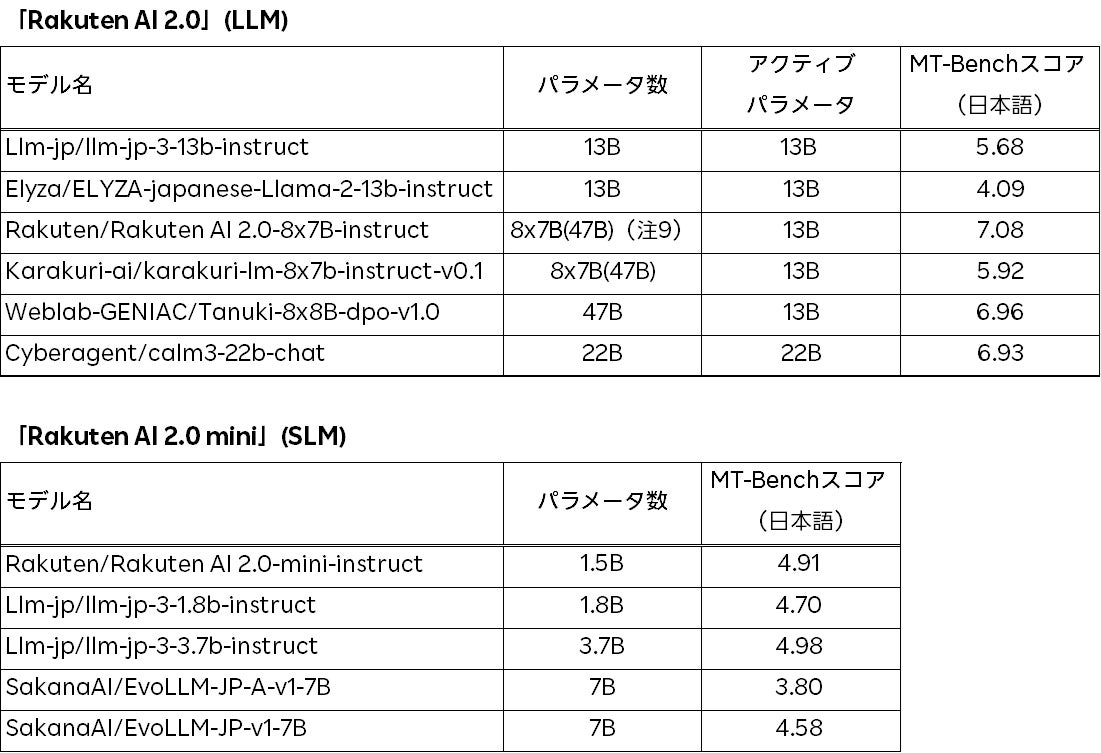
「Rakuten AI 2.0」インストラクションチューニング済モデルは、同程度のアクティブパラメータ数を持つ他のモデルと比較して、日本語版MT-Benchにおいて最も高い性能を発揮しています。同様に、「Rakuten AI 2.0 mini」インストラクションチューニング済モデルも、同様のサイズのオープンモデルの中で最も高い性能を発揮しています。これらのモデルは、コンテンツの要約、質問への回答、一般的なテキスト理解、対話システムの構築など、様々なテキスト生成タスクでの商業利用が可能です。さらに、これらのモデルは新しいモデルを構築するためのベースとしても利用することができます。
楽天グループのChief AI & Data Officer(CAIDO)であるティン・ツァイは次のようにコメントしています。「私たちの新たなAIモデルは、効果的かつコストパフォーマンスの良いソリューションを提供することで、企業が迅速に価値を実現し、新たな可能性を開くための最適な選択を行えるようにします。オープンモデルの公開は、日本におけるAI開発を加速すると考えています。私たちは、日本のすべての企業が、AIの活用によって新しいサービスや製品を作り上げ、実験しながら成長していくことを後押しし、人々の進歩のために協力し合うコミュニティを構築していきたいと考えています」
■新AIモデルの特徴
楽天は、AIアプリケーションを開発する企業や技術者などの専門家を支援することを目的として、以下のモデルを提供します。
・「Rakuten AI 2.0」: 2024年3月に公開した日本語に最適化した高性能なLLM「Rakuten AI 7B」を基に開発した8x7BのMoEモデルです。本LLMは、8つの70億パラメータで構築した「エキスパート」と呼ばれるサブモデルで構成され、高品質な日本語と英語の言語データを用いて継続的に学習されています 。
・「Rakuten AI 2.0 mini」: 15億パラメータのモデルです。本SLMは、内製の多段階データフィルタリング、アノテーションプロセスを通して構築された、高品質かつ広範な日本語と英語のテキストデータで最初から学習されています。
楽天では現在、LLMを研究目的で開発しており、お客様に快適なサービスを提供するため、今後も様々な選択肢を評価・検討していきます。また、社内におけるモデル開発を通してLLMに関する知識と専門性を高め、「楽天エコシステム(経済圏)」をサポートするために最適化されたモデルの作成を目指します。
楽天は、AI化を意味する造語「AI-nization(エーアイナイゼーション)」をテーマに掲げ、さらなる成長に向けてビジネスのあらゆる面でAIの活用を推進する取り組みをしています。今後も豊富なデータと最先端のAI技術の活用を通じて、世界中の人々へ新たな価値創出を目指してまいります。
(注1)Mixture of Expertsアーキテクチャは、モデルが複数のサブモデル(エキスパート)に分割されているAIモデルアーキテクチャです。推論および学習中は、最も適したエキスパートのサブセットのみがアクティブ化され、入力処理に使用されることで、より汎用的で高度な推論を行うことができます。
(注2)基盤モデルは、大量のデータで事前学習され、その後特定のタスクやアプリケーションに微調整できるモデルです。
(注3)インストラクションチューニング済モデルとは、指示形式のデータで基盤モデルをファインチューニングしたモデルです。このファインチューニングにより、利用者が入力した指示に対して返答を生成することができるようになります。
(注4)Apache 2.0ライセンス: https://www.apache.org/licenses/LICENSE-2.0
(注5)楽天グループの公式「Hugging Face」リポジトリ: https://huggingface.co/Rakuten
(注6)SimPOは、参照モデルに頼るのではなく、モデル出力の平均確率を暗黙の報酬として使用しています。この方法は、計算オーバーヘッドを削減し、より大きなモデルの選好最適化を可能にします。https://arxiv.org/abs/2405.14734
(注7)評価は日本語版MT-Benchで行っています。日本語版MT-Benchは、LLM を8つの側面(ライティング、ロールプレイ、推論、数学、コーディング、抽出、STEM、人文科学)で評価するために作られた80の挑戦的な質問からなる自由回答形式の評価データです。回答に対する評価は、GPT4(gpt-4o-2024-05-13)を用いたLLM-as-a-judgeにより行っています。
https://github.com/Stability-AI/FastChat/tree/jp-stable/fastchat/llm_judge
(注8)その他のモデルについては、Weights and Biasesが管理する公開リーダーボードから2025年1月27日時点のスコアを引用しています。
https://wandb.ai/wandb-japan/llm-leaderboard3/reports/Nejumi-LLM-3--Vmlldzo3OTg2NjM2
(注9)8x7Bモデルでは「エキスパート」以外のパラメータが共有されているため、サイズが560億未満となります。
※記載されている会社名・製品名・サービス名などは、各社の登録商標または商標です。
以 上
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像