GMOインターネットグループ、「NVIDIA H200 GPU」搭載環境の性能を実証
生成AI向けクラウドサービス「GMO GPUクラウド」を11月下旬提供開始
GMOインターネットグループ株式会社(代表取締役グループ代表:熊谷 正寿)は、「NVIDIA H200 Tensor コア GPU」(以下、H200 GPU)と AI ワークロード専用に設計された世界初のイーサネットファブリック「NVIDIA Spectrum™-X」(以下、Spectrum-X)(※1)搭載環境を国内で初めて検証し、結果を開示しました。
今回の検証では、グラフニューラルネットワーク(GNN)のベンチマークと、大規模言語モデル(LLM)のファインチューニングの2つのシナリオを実施し、いずれのケースでもH200 GPU は「NVIDIA H100 Tensor コア GPU」(以下、H100 GPU)よりも高い性能を発揮することがわかりました。LLM(Llama3-70B-Instruct)のファインチューニングシナリオにおいては、H100 GPU 搭載機材では103分かかっていた学習時間が、H200 GPU 搭載機材では50分で完了し、処理速度が約2倍となりました。
なお、GMOインターネットグループは、2024年11月下旬に、計算性能においてAI開発の効率化に貢献するサービスとして、H200 GPU と NVIDIA Spectrum-Xを国内で初採用した生成AI向けのクラウドサービス「GMO GPUクラウド」の提供を開始する予定です。
GMO GPUクラウドURL:https://www.gmo.jp/gpucloud/
(※1)「NVIDIA Spectrum-X」はAIワークロード専用に設計された世界初のイーサネットファブリックであり、生成AIネットワークのパフォーマンスを飛躍的に向上させることができます。イーサネットファブリックとは、ネットワークデバイス間の高速かつ効率的なデータ転送を実現するために、スイッチ間の接続を最適化する技術です。(https://www.gmo.jp/news/article/9005/)

【ベンチマークテストの概要と結果】
GMOインターネットグループは、「GNN のベンチマーク」と「LLMファインチューニング」の2つのシナリオにおいてH200 GPU とH100 GPU の性能を比較しました。
■GNNのベンチマーク結果
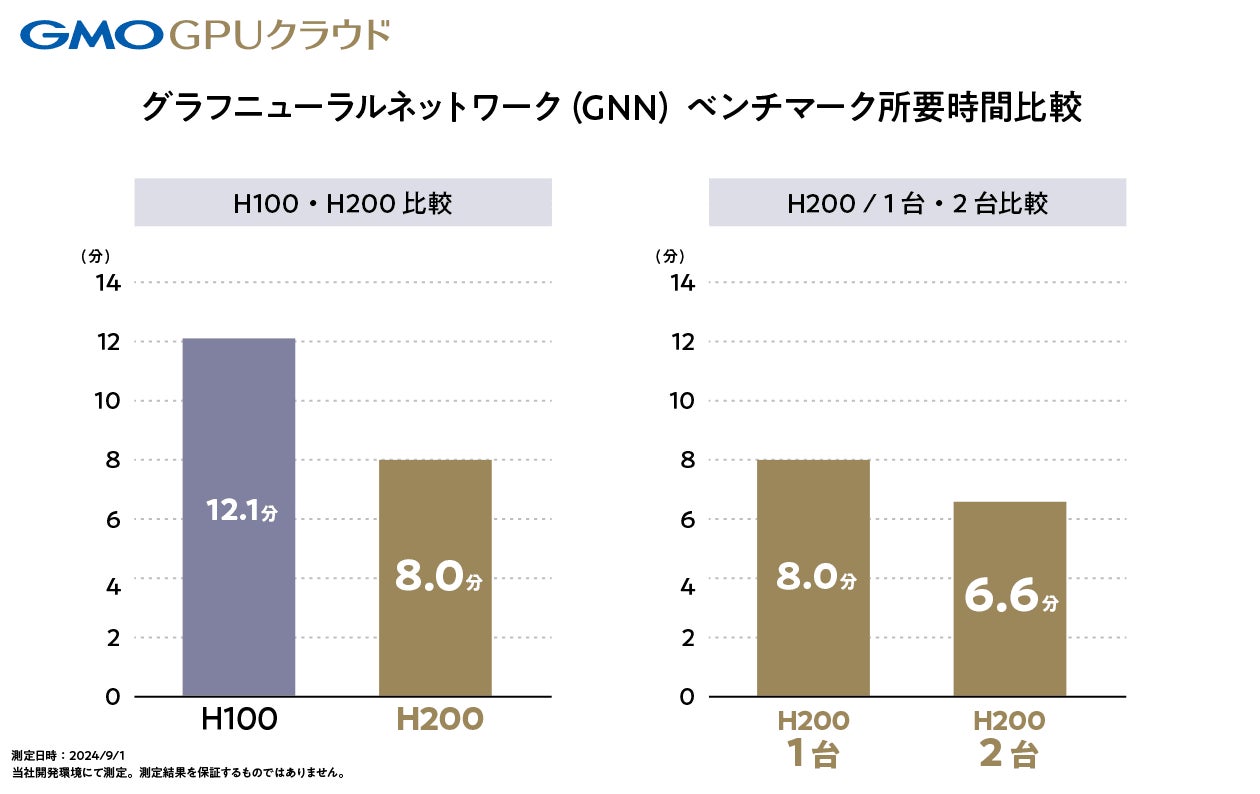
超高速で複雑な計算を行う強力なコンピューターシステムであるHPC(ハイパフォーマンス・コンピューティング)クラスタ全体のGNN学習性能を測定するベンチマーク性能において、H200 GPU はH100 GPU (12.1分)に比べて、約1.5倍の高速化(8.0分)を実現しました。【表1】
これは、H200 GPU がH100 GPU に対してメモリ搭載量が約 1.7 倍に強化されたことで、その演算性能が最適化されたためと考えられます。
また、H200 GPU の2台構成では、GPU数の増加によって、ベンチマーク時間が短縮できていることも確認できました。【表2】
【表1:GNNベンチマーク所要時間:H100 GPU・H200 GPU 所要時間比較】

|
構成 |
所要時間 |
削減時間 |
H100性能比 |
|
H100(1台) |
12.1分 |
ー |
100% |
|
H200(1台) |
8.0分 |
4.1分 |
151% |
【表2:GNNのベンチマーク所要時間: H200 GPU/1台・2台所要時間比較】
|
構成 |
所要時間 |
削減時間 |
H200(1台)性能比 |
|
H200(1台) |
8.0分 |
ー |
100% |
|
H200(2台) |
6.0分 |
1.4分 |
121% |
■LLMファインチューニング結果

さらに、実際のGPUでの学習時間に焦点を絞り、LLMファインチューニングにかかる時間を測定しました。
LLMのファインチューニングにおいては、H100 GPU 搭載機材では103分かかっていた学習時間が、H200 GPU 搭載機材では50分で完了し、処理速度が約2倍となりました。【表3】
前述のGNNのベンチマーク結果と同様に、LLMにおいても、H200 GPU がH100 GPU と比べてメモリ搭載量が増加したことで、モデルがより GPU の性能を生かした学習を行えることがわかりました。
さらに、H200 2台構成では、同1台構成比で処理速度が約2倍の25分で学習が完了しており、GPU が増えたことによって学習時間が短縮されることは当然ながら、Spectrum-Xの採用によって複数台構成でもその性能を最大限に引き出せることがわかりました。【表4】
【表3: LLM(Llama3-70B-Instruct)ファインチューニング所要時間比較)
|
構成 |
所要時間 |
削減時間 |
H100性能比 |
|
H100(1台) |
103分 |
ー |
100% |
|
H200(1台) |
50分 |
53分 |
206% |
【表4: LLM(Llama3-70B-Instruct)ファインチューニング所要時間比較】
|
構成 |
所要時間 |
削減時間 |
H200(1台)性能比 |
|
H200(1台) |
50分 |
ー |
100% |
|
H200(2台) |
25分 |
25分 |
200% |
■実施環境
|
H100 |
H200 |
|
|
サーバモデル |
DELL PowerEdge XE9680 |
同左 |
|
CPU |
第 4 世代インテル® Xeon® スケーラブル・プロセッサー・ファミリー |
同左 |
|
メモリ |
2048GB |
同左 |
|
ディスク構成 |
NVMe 1.92TB x 4 |
NVMe 7.68TB x 4 |
|
GPU(※2) |
NVIDIA H100 SXM x 8 |
NVIDIA H200 SXM x 8 |
(※2)いずれも当社所有機材
・測定日時:2024/9/1
・パフォーマンス結果は、記載された構成でのテストに基づき、当社環境で計測した参考値であり、検証結果ならびに製品の性能・動作について保証するものではありません。
■ GMOインターネットグループ インフラ・運用本部 プロジェクト統括チーム エグゼクティブリード 佐藤嘉昌 コメント
高性能な「NVIDIA H200 GPU」と先進のネットワーク「NVIDIA Spectrum-X」を採用した「GMO GPUクラウド」の提供により、日本のAI研究開発を加速させることを目指しています。高性能かつ柔軟なGPUリソースを提供することで、研究者や開発者の皆様がより効率的にAI開発に取り組めるよう支援してまいります。この新サービスが日本のAI技術革新の一助となり、グローバル競争力の強化につながることを期待しています。
■ 今後の展開
「GMO GPUクラウド」は2024年11月下旬のサービス開始を予定しています。現在、H200 GPU のセットアップを進めており、順次サーバーの設置と稼働テストを行っています。今後も定期的に進捗情報を発信し、ユーザーのニーズに応じたサービス開発を進めていく予定です。GMOインターネットグループは、「GPUならGMOインターネットグループ」と認知されることを目指し、AI産業に欠かせないクラウドサービスとして、市場に新たな価値を提供してまいります。
■「GMO GPUクラウド」トライアルのお申し込みについて
「GMO GPUクラウド」の利用を検討されるお客様には、トライアル環境のご相談を承ります。
本サービスへのお問い合わせ・トライアルのお申し込みはこちら
URL:https://forms.office.com/r/pMi1PzTGEW
■サービス提供の背景
近年の生成AI開発において、LLMのモデルサイズは大規模化しており、それに伴い学習時間が増大し、開発期間の長期化やコスト増加が課題となっています。この状況下で、国内の生成AIインフラ環境には重要な課題が浮上しています。大規模モデル開発のユースケースを正確に把握できていないため、GPUの提供が先行し、必要不可欠な広帯域ネットワークや高速ストレージの整備が遅れがちです。
従来のGPUクラウドサービスでは、これらの複合的な課題を解決することが困難でした。GMOインターネットグループは、このような課題を抱える企業に向けて、より高速で効率的な生成AI開発環境を提供するため、「NVIDIA H200 GPU」採用のGPUクラウドサービスの提供開始に至りました。
【「GMO GPUクラウド」について】
(URL:https://www.gmo.jp/gpucloud/)
GMOインターネットグループの「GMO GPUクラウド」は、高性能な「NVIDIA H200 GPU」を搭載し、国内で最速の提供を目指します。(※3)また、AIワークロード専用に設計された世界初のイーサネットファブリック「NVIDIA Spectrum-X」を国内クラウド事業者で初めて採用しています。このH200 GPU と Spectrum-Xの統合で、生成AI開発や機械学習に最適化した高水準のGPUクラウド環境を実現します。
さらに、最も要求の厳しいAI/ML/DL大規模モデルをトレーニングするよう設計されたDell PowerEdge XE9680 (NVIDIA H200 SXM 8基搭載)を採用し、システムの構築を進めています。
GMOインターネットグループは、本サービスを通じて、生成AI分野やハイパフォーマンス・コンピューティング(HPC)分野に取り組む企業や研究機関に対し、インフラのチューニングが不要の高水準な計算環境を提供し、お客様の開発期間の短縮とコスト低減に貢献し、国内AI産業の発展を促進します。
(※3)GMOインターネットグループ、NVIDIA H200 Tensor コア GPU を採用した生成AI向けのGPUクラウドサービスを国内最速提供へ:https://www.gmo.jp/news/article/8933
・提供開始時期: 2024年11月下旬 (予定)
■「GMO GPUクラウド」の特徴
1. 国内最速レベルの提供となる「NVIDIA H200 Tensor コア GPU」搭載
大規模言語モデルの開発・研究者向けにGPUメモリ容量とメモリバス帯域幅を大幅に拡大・最適化したH200 GPU を国内最速提供。H200は、毎秒4.8テラバイト (TB/s) で141ギガバイト(GB) のHBM3eメモリを提供する初のGPUです。これは、H100 GPU の約1.7倍の容量で、メモリ帯域幅は約1.4 倍です。
2. 国内クラウド事業者初となる「NVIDIA Spectrum-X」の採用
AIワークロード専用に設計された世界初のイーサネットファブリックであるSpectrum-X を国内で初めて採用。生成AIネットワークのパフォーマンスを飛躍的に向上させます。
3. DDNの超高速ストレージを採用
NVIDIA製品と互換性のあるDDNの高速ストレージを採用。強力な性能を持つAI開発プラットフォームをワンストップで提供します。
4. NVIDIA AI Enterpriseによる迅速な環境構築・管理
NVIDIA AI Enterpriseは、データサイエンスパイプラインを加速し、プロダクショングレードのコパイロットやその他の生成AIアプリケーションの開発と展開を合理化する、エンドツーエンドのクラウドネイティブなソフトウェアプラットフォームです。
5. 業界標準のジョブスケジューラーSlurmを採用
クラスタシステムのための業界標準であるジョブスケジューラーです。リソースの割り当て・ジョブの制御・モニタリング機能を提供します。
【GMOインターネットグループ株式会社について】
GMOインターネットグループ株式会社は、1995年12月にインターネット事業を創業して以来、“すべての人にインターネット”をコーポレートキャッチに、インターネットの場の提供に経営資源を集中し、インターネットをより豊かに便利にするべく事業を展開してまいりました。
現在では、インターネットインフラ事業、インターネット広告・メディア事業、インターネット金融事業、暗号資産事業を展開しています。ご利用いただいているお客様の数は2024年6月末時点で1,775万顧客、上場企業10社を中心とした全112社、グループパートナー数約7,500名の総合インターネットグループに成長しています。また、「AIで未来を創るナンバー1企業グループへ」を掲げ、グループ全パートナーを挙げて生成AIを活用することで、① 時間とコストの節約、② 既存サービスの質向上、③ AI産業への新サービス提供を進めています。
【サービスに関するお問い合わせ先】
●GMOインターネットグループ株式会社
ドメイン・ホスティング事業本部
E-mail:aicloud@gmo.jp
以上
【GMOインターネットグループ株式会社】 (URL:https://www.gmo.jp/)
会社名 GMOインターネットグループ株式会社 (東証プライム市場 証券コード:9449)
所在地 東京都渋谷区桜丘町26番1号 セルリアンタワー
代表者 代表取締役グループ代表 熊谷 正寿
事業内容 ■インターネットインフラ事業
■インターネット広告・メディア事業
■インターネット金融事業
■暗号資産事業
資本金 50億円
Copyright (C) 2024 GMO Internet Group, Inc. All Rights Reserved.
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像