甘党AI、日本語モノラル音源に最適化した話者分離モデル「Sepamato」を開発
精度は従来の公開モデル比2倍以上。API/オンプレ対応、話者・語彙の最適化で柔軟に導入可能。
甘党AI株式会社(本社:福島県会津若松市、代表取締役:藤松 勇滉、以下「当社」)は、日本語音声に最適化したモノラル音源の話者分離モデル「Sepamato(セパマト)」の開発を完了しました。本モデルは、字幕制作、音声認識システム、データセット構築など、幅広い用途でご活用いただけます。
主な特徴
-
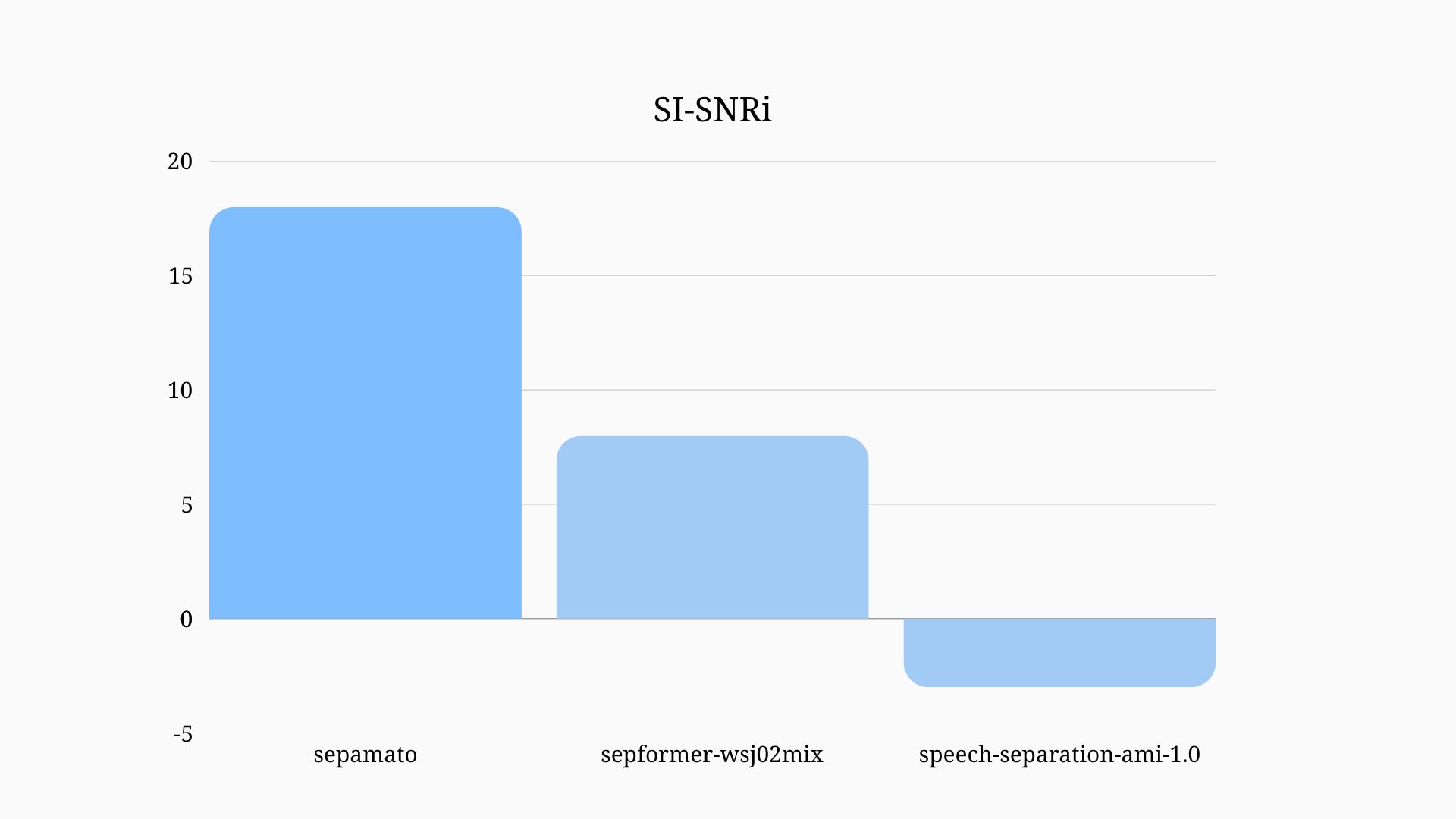
日本語音声データセットで学習し、日本語データセットにおけるSI-SNRi評価で従来の公開モデル比2倍以上の改善を達成
-
APIは当社の会話分析サービス「Rokavox」にて提供予定
-
オンプレミス環境にも対応し、既存システムへ柔軟に組み込み可能
-
特定話者や特定領域の語彙に対する追加学習による最適化が可能
開発の背景
音声認識AIの普及が進む一方、会議・ライブ配信・接客などの実利用現場では、環境ノイズや複数話者の同時発話により、音声認識モデルの本来の認識精度を十分に発揮できないという課題があります。
また、複数話者が含まれる音声データから特定話者の音声のみを抽出できれば、音声対話データセットの作成など、新たな価値の創出が期待されます。
既存の公開話者分離モデルの多くは英語を中心に学習されており、日本語への最適化が不十分でした。
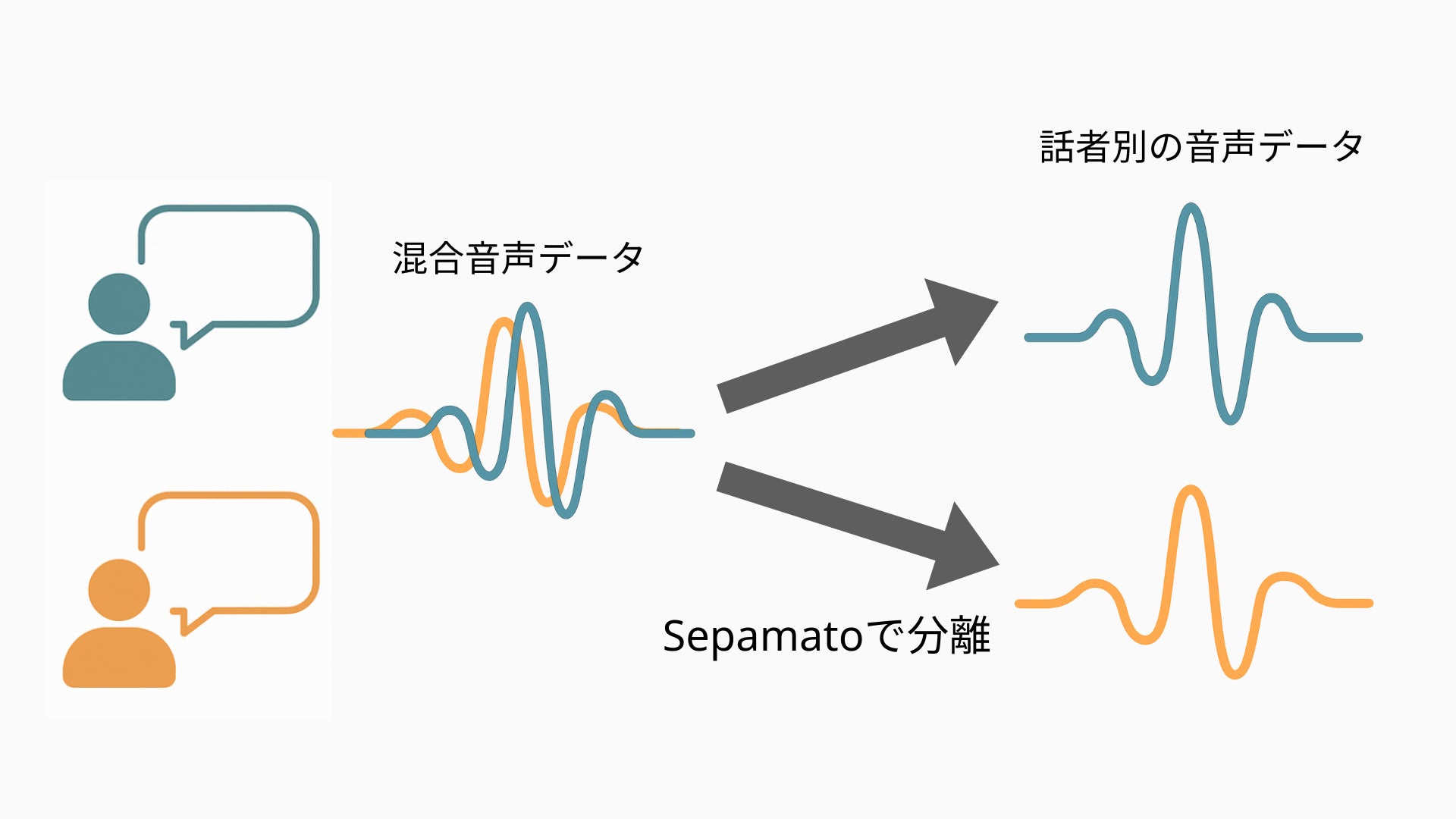
Sepamatoの概要
Sepamatoは、モノラル音源から各話者を高精度に分離する、日本語最適化の話者分離モデルです。日本語音声データセット(JVS)を用いた評価では、SI-SNRiが公開モデル比で2倍以上となりました。特定話者や特定領域の語彙に対する最適化により、さらなる精度向上が可能です。
SI-SNRi(Scale-Invariant Signal-to-Noise Ratio Improvement):音量差に左右されず、混合音から特定音源をどの程度明瞭に分離できたかを示す評価指標
本モデルは、当社の会話分析サービス「Rokavox」で提供予定です。あわせて、本モデルを活用したPoCのご相談も承っております。
主な活用シーン
放送のポストプロダクション
動画制作やポッドキャスト制作において、従来より高い精度で字幕を作成できます。また、話者単位で音声を分離することで、各話者の音声翻訳や多言語吹替の制作を効率化できます。
接客業のサービス向上
従業員の音声を顧客の音声から明確に分離することで、顧客対応をより精緻に評価し、従業員ごとに最適化したフィードバックを提供できます。
音声認識システム等への組み込み
オンプレミス環境にも対応しているため、さまざまなアプリケーションに組み込めます。例えば、議事録アプリや音声関連アプリの前処理として組み込むことで、書き起こし精度のさらなる向上が見込めます。
データセットの作成
音声対話型AIの構築には、膨大な対話データが必要です。音声データのアノテーションや対話音声のデータセット作成にもご活用いただけます。
甘党AI株式会社
甘党AI株式会社は、お客様のニーズに応じたAI技術の研究開発およびAIアプリケーションの開発を行っています。本モデルを用いたPoCのご相談は、以下よりお問い合わせください。

甘党AI株式会社
甘党AI株式会社は、AIを前提に設計・開発された「AIネイティブ」なソフトウェアを世界の日常に送り出すことを使命とする会津大学発のベンチャー企業です。
すべての画像