AI学習用音声データセット「OTS」に待望の新ラインナップ。機密情報を含むリアルな会話データを先行販売開始
音声認識AIのOTSデータセットを販売するaudioコーパス株式会社(本社:東京都豊島区、代表取締役:森井 直哉)は、1月19日(月)より新たなデータセット『機密情報』をリリースします。

機密情報データセット提供開始のお知らせ
1.機密情報データセットとは
本データセットは、従来の自然な会話データに加え、以下の機密性の高い情報を意図的に組み込んだ構成となっています。
-
フルネーム
-
電話番号
-
住所
人口の多い氏名を上位から収集し、さらに「東京都内の住所」を網羅的に組み合わせたデータセットです。
2.200時間のコールセンター音源を収録
実務レベルのボリュームとなる「合計200時間」のコールセンター対話音源を収録。膨大な音声データにより、機密情報を含む複雑な応対パターンの網羅的な学習を可能にします。
3.アノテーション済みで即利用可能
各機密情報には、すでにアノテーションタグを付与済みのため、
AI モデル開発や検証の際に、追加作業なくすぐにご活用いただけます。
4.自然な会話の流れで機密情報が登場
会話の流れの中で、自然に機密情報が登場するよう設計された対話データとなっており、
実運用に近いシナリオでの学習が可能です。
5.本人確認業務に最適化されたデータ構造
本人確認が求められるコンタクトセンターなどの業務シーンに最適化しており、
実務に即した対話パターンを多数収録しています。
6.権利関係を整理した OTS データとして提供
著作権を含む権利関係を整理した OTS(Off-The-Shelf:既製の)データ として提供するため、
安心して商用利用にお使いいただけます。
7.希少性の高いデータセットを AI 開発に
これまで活用が難しかった、機密性の高い希少なデータセットとなります。
この機会にぜひ、AI 開発・学習用途としてご活用いただければ幸いです。
「audioコーパス データセット」とは
「audioコーパス データセット」は、高品質な音声データと正確なテキストデータをパッケージ化した、AI学習特化型の発話データセットです。
機械学習の要件に基づき、あらかじめアノテーション(タグ付け)やデータ整形を施しているため、導入後すぐに開発プロセスへ組み込むことが可能です。自社でのデータ収集・加工の手間を徹底的に排除し、AIモデルの開発サイクルを大幅に加速させるデータ構造を実現しています。
<音声データ 仕様>
-
多様な対話シーンを網羅 商談、コールセンター(応対)、対談、面談、番組配信など、実ビジネスに即した多種多様なリアル対話を収録。
-
高精度な話者分離(ステレオ収録) マルチマイクを用い、L/Rチャンネルに話者を分けたセパレート収録を採用。話者分離アルゴリズムの学習に最適です。
-
実践的な自然発話(クロストーク対応) 台本のない自然発話による「発言の重なり(クロストーク)」をそのまま収録。実環境に近い高度な学習が可能です。
-
スタジオクオリティの音質 専用スタジオでの収録により、バックグラウンドノイズを排除。クリーンな音声で学習効率を最大化します。
-
コンプライアンスに準拠した権利処理 著作権および個人情報(音声データ)に関する権利関係を完全に整備。商用利用においても安心して導入いただけます。
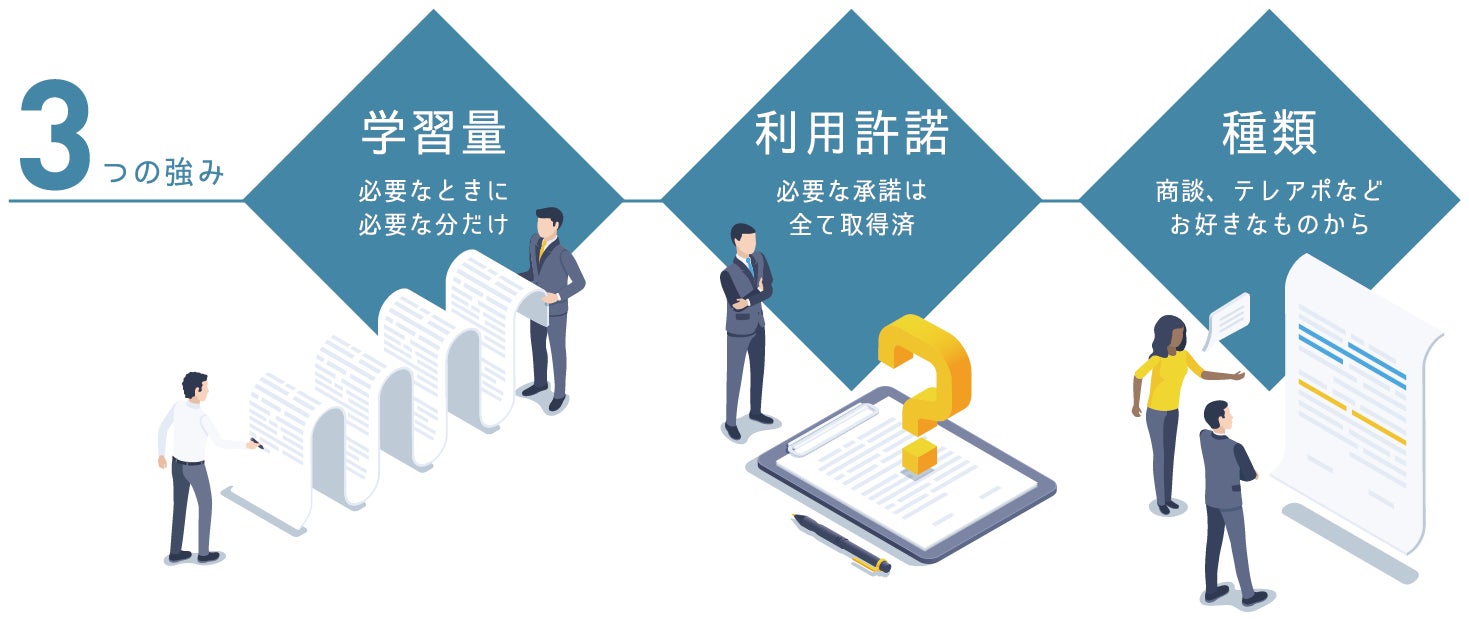
■audioコーパス データセットの3つの強み
<テキストデータ 仕様>
-
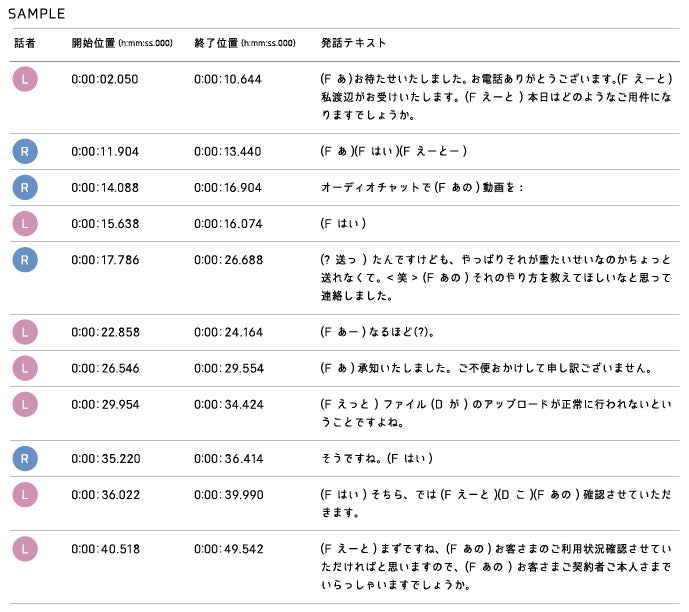
逐語(ちくご)による精密な書き起こし 相槌や「どもり(澱み)」も含め、音声内容を忠実にテキスト化。音声認識エンジンの精度評価にも活用可能です。
-
6種のタグ付与による高度なアノテーション フィラー(えー、あのー等)や言い間違いに対し、6種類の属性タグを付与。特定の音声事象のみを抽出した効率的な学習を支援します。
-
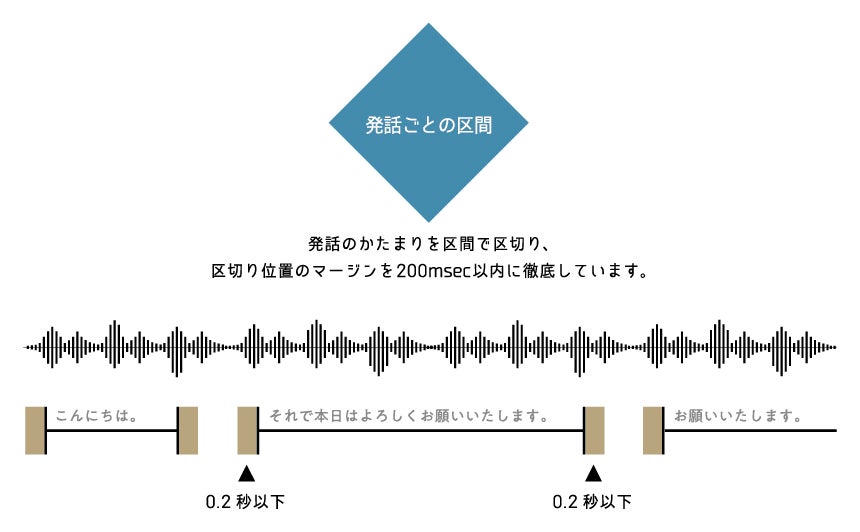
発話セグメント単位のタイムスタンプ 発話単位で区間を区切ってデータ化。特定の区間のみをピンポイントで利用・分析できる柔軟なデータ構造を実現しています。
■「日本語話し言葉コーパス」(CSJ)の仕様に準じたタグ付与

■「記者ハンドブック」に準拠した高品質な日本語表記
日本語のテキストデータ作成においては、表記ゆれ、誤字脱字、聞き間違いの排除など、細部への配慮が不可欠です。 「audioコーパス」では、共同通信社発刊の**「記者ハンドブック」を正書法として採用**。厳格な表記ルールの徹底により、AI学習に最適な、ノイズの少ない高精度なテキストデータを提供いたします。

【リリースの背景】
音声認識AIの開発において、学習用の発話データは極めて重要なリソースですが、現在、市場には商用利用が可能な「権利フリー」のデータセットがほとんど存在しません。
その最大の要因は、人の声が「個人情報」に該当し、厳格な許諾管理が求められる点にあります。そのため、システム開発の現場では、音声データを自前で収録・調達し、膨大な時間をかけて一から書き起こし(アノテーション)作業を行わなければならないのが実情です。
さらに、高精度な学習には「表記ゆれ」の精緻な補正や品質管理が不可欠であり、データの整備には多大なコストと工数が蓄積されています。
こうした開発現場の課題を解決するため、audioコーパス株式会社は「発話データの製作所」として市場ニーズを徹底調査し、即戦力となるデータセットを構築いたしました。今回リリースするデータセットは、機密情報を含む自然発話の網羅性に優れ、AIモデルの精度向上に直結する汎用性の高い構成となっています。
【こんな方におすすめ】
音声認識AIの精度向上を目指す開発担当者 実務レベルの学習用データを必要とし、特にアノテーション済みの高品質な音源を探している方
新領域や特定シーンへの対応を迫られている企業 導入先の業務変化に伴い、コールセンターや本人確認といった特定の対話カテゴリのデータを緊急で確保したい方
権利関係がクリアな音声資産を求めるマネージャー 商用利用における著作権や個人情報保護のコンプライアンスを重視し、安全なOTSデータを導入したい方
言語解析・自然発話の研究に従事する専門家 「表記のゆらぎ」や「フィラー(えー、あのー)」など、生の対話に含まれる言語的特徴を詳細に分析・研究されている方
自前でのデータ収集・アノテーション工数を削減したい方 収録や書き起こしにかかるコストを大幅に抑え、モデル開発のスピードを加速させたい方
【購入の流れと今後の展望】
各データセットは、実際のデータ品質を確認いただけるサンプルデータを無償で提供しております。ご興味をお持ちの方は、弊社ウェブサイトの「お問い合わせ」フォームよりお気軽にお申し付けください。
audioコーパス株式会社は、本データセットの提供を通じて音声認識AIのさらなる利便性向上に寄与し、高度な音声活用社会の実現に取り組んでまいります。
企業概要
audioコーパス株式会社
代表者:森井直哉
所在地:東京都豊島区東池袋5-49-5 小野ビル5F
事業内容:アノテーションデータ製作ならびOTSデータセット販売、請負作成、作成支援
企業Webサイト:https://www.otocorpus.com/
■取材のお申し込み
本リリースに関する取材のお申し込み、また製品・サービスに関するお問い合わせは下記までご連絡ください。
お問い合わせフォーム : こちらからお問い合わせください
Email:contact@otocorpus.com
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像