「Nejumi LLM リーダーボード」で評価された大規模言語モデル数が日本最大級に
JGLUEデータを使ったLLM日本語評価を自動化し再現可能なジョブを公開
Nejumiリーダーボードへのアクセス:http://wandb.me/nejumi
LLMモデル日本語評価の重要性
ChatGPTの驚異的な言語・論理能力の高さを受けて、多くの企業や研究機関が独自のLLM開発を開始しました。特にグローバルではEleuther AI社のGPT-NeoXやMeta社のLlamaなど、非常に高性能なモデルやコードがオープンソース化され、高性能であることはもちろん高速化や多言語化など様々な特徴を持ったモデルが次々に公開され、中には商用利用を可能とする物も多く見られます。
大規模言語モデルは与えられた文章に対して、次にくる単語を予測する課題を解かせながら学習させることで、高い汎用性を獲得できることが一番の特徴ですが、モデルが利用される際の具体的な用途(「ダウンストリーム・タスク」と呼ばれる)に対しての性能評価を幅広く行うことは膨大な作業を要します。オープンソースモデルの公開レポジトリとして世界最大規模のHuggingFaceにあるOpen LLM Leadearboardでは、複数選択問題のARCや文章補完問題のHellaSwagなど複数の評価用データセットを使って、様々なモデルに対する性能評価を行ったランキングを公表していますが、いずれの評価も英語でのみ行われています。
W&B Japanでは、自社製品のWandBにおいて、複雑なML開発タスクを自動化する「ローンチ」機能を今年3月に公開しており、また分析結果を集約・共有する「レポート」機能を活用して、日本語でのLLMモデル評価を随時実施・公開してきました。特に技術的発展の観点から重要なモデルや、国内で発表された注目度の高いモデルなどを中心に評価を行い、国内でも最大級のLLM評価リーダーボードに成長しました。
「Nejumiリーダーボード」のモデル評価方法
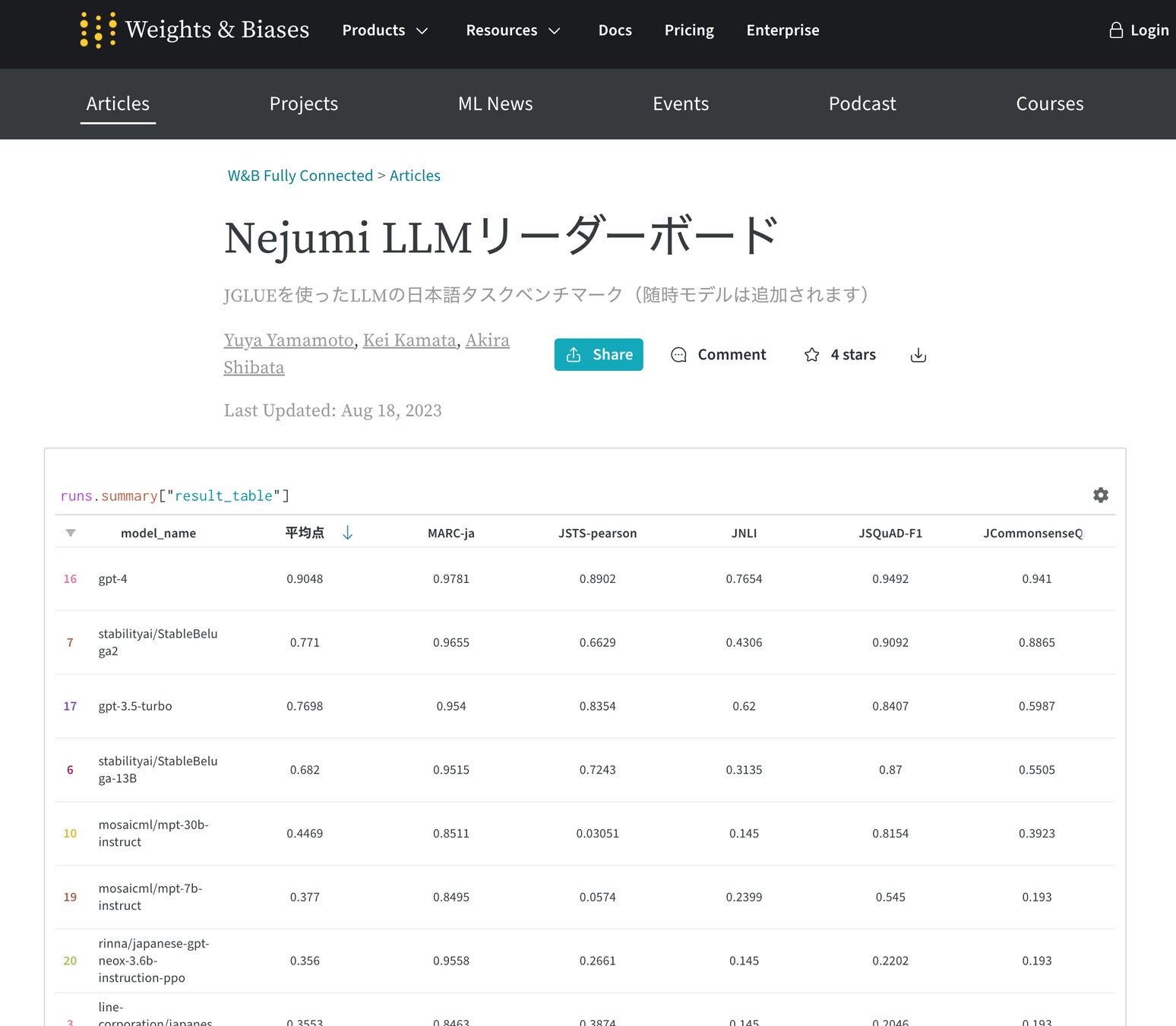
Nejumiリーダーボードでは、JGLUEデータセットを使ったモデル評価を行っています。JGLUEとは、早稲田大学とYahoo! JAPAN研究所が構築・公開した日本語言語理解ベンチマークで、GLUEデータセットの日本語版と言えます。JGLUEには様々な種類のタスクが含まれますが、Nejumiリーダーボードでは、特にLLMの能力を測るのに重要と思われる5つのタスクを使っています。この中には、文章をポジティブ・ネガティブに分類するMARC-jaや、常識推論能力を評価するための5択の選択式問題であるJCommonsenseQAなどが含まれます。
同様のランキングとしてはEleuther AIのlm-evaluation-harnessとJGLUEデータセットを使い、Stability AI Japan社が公開しているJP Language Model Evaluation Harnessがありますが、比較すると同じモデルのスコアはL Nejumiリーダーボードの方が低く出る傾向にあります。本リーダーボードでは、モデルに対してほとんど手助けをせずに、JGLUEに対するプロンプトへの応答をできる限りそのまま評価することを重視しているためで、例えば、正解のトークン数を事前に与えたり、選択肢ごとに尤度を計算したりということは行っていません。また、プロンプトにいくつかの例題を与えることで回答の精度を向上する「数ショット学習」などの手法も、結果がプロンプトの内容に大きく影響を受けてしまうため使用していません。
Nejumiリーダーボードで使っている評価方法は、対象となるモデルは対話型のプロンプトに対して適切な応答を返すことを前提としているため、インストラクションチューニングによって、いわゆるチャット能力を獲得していないモデルに対して実施するのは不適切と言えますので、注意が必要です。例えばNejumiリーダーボードでは、サイバーエージェント社のOpenCalmモデルを評価していますが、このモデルはインストラクションチューニングされていないため、Nejumiリーダーボードではその本領を発揮できていないでしょう。
現時点での結果の考察と今後の展望
様々なモデルの評価結果を検証すると、まずOpenAI社のChatGPTを構成するGPT-4およびGPT-3.5の高スコアは際立っています。特にGPT-4は全てのタスクで他のモデルを凌駕し、平均点でも90点を超え、二位のモデルに対して10点以上の得点差をつけています。
オープンソースのモデルに関しては、状況がどんどん変化しています。数週間前までは、最も精度の高いモデルでも50点に達せず、日本語に重点をおいて開発・公開された日本企業のLLMモデルも総じて低い得点でした。特に複数選択問題なのに、選択肢以外の答えをしたり、抜き出し問題なのに文中にない答えを出力したりなどの回答形式不備のケースも多く見られていました。(企業が公開しているモデルは、必ずしもその企業が開発している中で最も良いモデルではない場合もありますので、企業の評価と結びつけることはできません。)
ところが7月半ばにMeta社がLlama 2モデルを公開すると状況は大きく変わりました。700億パラメーターという非常に巨大なモデルで、前述のHuggingFaceリーダーボードでも非常に高いスコアを出しています。さらにこのモデルを追加データで学習したモデルが次々に現れています。Nejumiリーダーボードでは、Stability AI社がLlama 2モデルをファインチューニングしたモデル、StableBeluga2が初めてGPT-3.5を超える結果を出しました。現時点ではまだGPT-4を超えるモデルは出現していませんが、オープンソースモデルの性能は著しく向上してきており、今回の私たちの検証により、英語だけではなく日本語でもその高い精度が確認されています。
これからもLLMの開発には更なる発展が見られるでしょうが、その方向性が多様化していることにも注目が必要です。上述の高性能モデルは概してそのサイズが大きく、駆動するためには多数のGPUを用意する必要があります。よって、より少ないパラメーター数のモデルでも性能を上げるための研究にも注目が集まっています。また、より幅広いダウンストリームタスクでのLLM活用が進むことに合わせて、現状JGLUEデータセットを中心に行われている性能評価もより今後はより多様化していくことが求められます。W&B Japanは、国立情報学研究所(NII)の主宰するLLM-jpコラボレーションへの参画メンバーとして、今後の日本のLLM開発に貢献していくために、この課題を発展的に解決する開発に取り組んでいます。
LLM開発を支援するするW&B Japanの活動
WandBは本年4月にLLM開発支援に特化したPrompts機能をリリースするとともに、LangChainやLlamaIndexなどの主要なLLMアプリケーション開発フレームワークとのインテグレーションを発表し、この新たなパラダイムにおける開発プロセスを可視化・管理・検証するためのプラットフォームを提供しています。また、日本においては、5月にホワイトペーパー「LLMをゼロからトレーニングするためのベストプラクティス」を公開(http://wandb.me/llm-jpdl)し、LLM開発の最新ノウハウを集約・発信するとともに、6月には本リリースで紹介したNejumiリーダーボードを立ち上げ、英語でしか評価されないことの多いLLMモデルの日本語性能のリーダーボードを公開しています。
W&B Japanでは今後も、日本でのAI開発に関わるすべての実務者の皆様に最も進んだ機械学習開発・MLOpsツールをお届けするとともに、弊社グローバルチームと連携して世界最先端のAI開発におけるベストプラクティスをご共有することを通じて、日本での生成AI開発を加速させていきます。
Weights & Biases Japan株式会社について
Weights & Biases Japan株式会社は、エンタープライズグレードのML実験管理およびエンドツーエンドMLOpsワークフローを包含する開発・運用者向けプラットフォームを販売する日本法人です。WandBは、LLM開発や画像セグメンテーション、創薬など幅広い深層学習ユースケースに対応し、NVIDIA、OpenAI、Toyotaなど、国内外で50万人以上の機械学習開発者に信頼されているAI開発の新たなベストプラクティスです。
Weighs & Biases Japan株式会社は、2023年4月に日本ディープラーニング協会に正会員として入会しました。
W&B社日本語ウェブサイト:https://wandb.jp

このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像
- 種類
- 商品サービス
- ビジネスカテゴリ
- ネットサービスパソコンソフトウェア
- ダウンロード