rinna社、日本語GPT-2/BERTの事前学習モデルを開発しオープンソース化
GitHubとHuggingFaceで事前学習モデルとソースコードを公開
rinna株式会社(本社:東京都渋谷区/代表取締役:ジャン“クリフ”チェン、以下rinna社)は、このたび、製品開発のための実験過程で、日本語に特化したGPT-2とBERTの事前学習モデルを開発しました。日本語の自然言語処理(NLP)の研究・開発コミュニティに貢献するために、開発した事前学習モデルとその学習を再現するためのソースコードを、GitHubおよびNLPモデルライブラリHuggingFaceにMITライセンスのオープンソースとして公開します。
■背景
rinna社は、2021年4月に日本語に特化した中規模サイズのGPT-2(GPT2-medium)を公開し、反響を呼びました。そしてこのたび、モデルサイズが異なる2つのGPT-2(GPT2-small, GPT2-xsmall)を公開する運びとなりました。モデルサイズの違いはパフォーマンスとコストのトレードオフであり、研究者や開発者が最善のモデル選択をすることが可能となります。また、GPT2-mediumも、学習データと学習時間を増やし、より高性能なモデルへとアップデートされています。
さらに、GPT-2に加え、BERTを改良したモデルであるRoBERTaも公開しました。 GPT-2とBERTの公開により利用者は目的に合わせたモデル選択や、追加学習により多様なタスクへの応用が可能となります。
■日本語GPT-2の機能
言語モデルは、会話や文章の「人間が使う言葉」を確率としてモデル化したものです。優れた言語モデルとは、確率を正確に推定できるものを指します。例えば、 “確率(吾輩は猫である)>確率(吾輩が猫である)” と推定できるのが、言語モデルの能力です。
GPT-2は、単語の確率の組み合わせから文の確率を計算する言語モデルです。例えば、 “確率(吾輩は猫である)=確率(吾輩)×確率(は|吾輩)×確率(猫|吾輩,は)×確率(で|吾輩,は,猫)×確率(ある|吾輩,は,猫,で)” のような方法で推定を行います。この性質を用いて、GPT-2は「吾輩は」という単語を入力したとき、次にくる単語として確率が高い「猫」を予測することができます。
今回、rinna社が公開した日本語GPT-2は、一般的な日本語テキストの特徴を有した高度な日本語文章を自動生成できます。例えば「本日はご参加ありがとうございました。誰も到達していない人工知能の高みへ、ともに」という講演後のメールを想定した文章をGPT-2に入力として続きの文章を自動生成すると、図1のように入力文章の文脈を考慮した文章が生成されます。
■日本語BERTの機能
GPT-2は、予測したい単語より前の単語を考慮して次の単語を予測する言語モデルです。これに対してBERTは、予測したい単語の前の単語だけでなく後の単語も考慮して予測を行います。GPT-2では「吾輩」「は」を考慮して「猫」を予測しますが、BERTでは前の単語「吾輩」「は」と後ろの単語「で」「ある」を考慮して「猫」を予測します(図2)。
■rinna社の日本語事前学習モデルの特徴
rinna社の日本語事前学習モデルは、以下の特徴があります。
rinna社は、2021年4月に日本語に特化した中規模サイズのGPT-2(GPT2-medium)を公開し、反響を呼びました。そしてこのたび、モデルサイズが異なる2つのGPT-2(GPT2-small, GPT2-xsmall)を公開する運びとなりました。モデルサイズの違いはパフォーマンスとコストのトレードオフであり、研究者や開発者が最善のモデル選択をすることが可能となります。また、GPT2-mediumも、学習データと学習時間を増やし、より高性能なモデルへとアップデートされています。
さらに、GPT-2に加え、BERTを改良したモデルであるRoBERTaも公開しました。 GPT-2とBERTの公開により利用者は目的に合わせたモデル選択や、追加学習により多様なタスクへの応用が可能となります。
- HuggingFace:https://huggingface.co/rinna
- GitHub:https://github.com/rinnakk/japanese-pretrained-models
■日本語GPT-2の機能
言語モデルは、会話や文章の「人間が使う言葉」を確率としてモデル化したものです。優れた言語モデルとは、確率を正確に推定できるものを指します。例えば、 “確率(吾輩は猫である)>確率(吾輩が猫である)” と推定できるのが、言語モデルの能力です。
GPT-2は、単語の確率の組み合わせから文の確率を計算する言語モデルです。例えば、 “確率(吾輩は猫である)=確率(吾輩)×確率(は|吾輩)×確率(猫|吾輩,は)×確率(で|吾輩,は,猫)×確率(ある|吾輩,は,猫,で)” のような方法で推定を行います。この性質を用いて、GPT-2は「吾輩は」という単語を入力したとき、次にくる単語として確率が高い「猫」を予測することができます。
今回、rinna社が公開した日本語GPT-2は、一般的な日本語テキストの特徴を有した高度な日本語文章を自動生成できます。例えば「本日はご参加ありがとうございました。誰も到達していない人工知能の高みへ、ともに」という講演後のメールを想定した文章をGPT-2に入力として続きの文章を自動生成すると、図1のように入力文章の文脈を考慮した文章が生成されます。
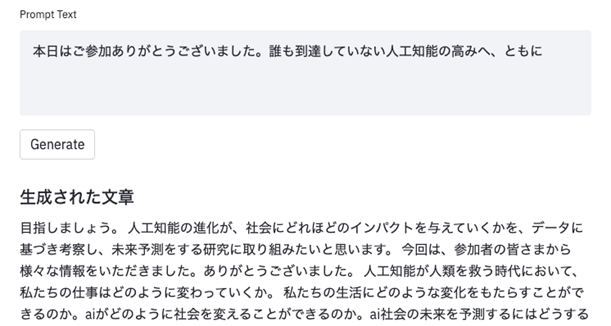 図1:講演後のメールの文脈で文章を自動生成(上記のデモでは生成する文章の文字数上限を設定しており、実際に生成される全文ではありません。)
図1:講演後のメールの文脈で文章を自動生成(上記のデモでは生成する文章の文字数上限を設定しており、実際に生成される全文ではありません。)
■日本語BERTの機能
GPT-2は、予測したい単語より前の単語を考慮して次の単語を予測する言語モデルです。これに対してBERTは、予測したい単語の前の単語だけでなく後の単語も考慮して予測を行います。GPT-2では「吾輩」「は」を考慮して「猫」を予測しますが、BERTでは前の単語「吾輩」「は」と後ろの単語「で」「ある」を考慮して「猫」を予測します(図2)。
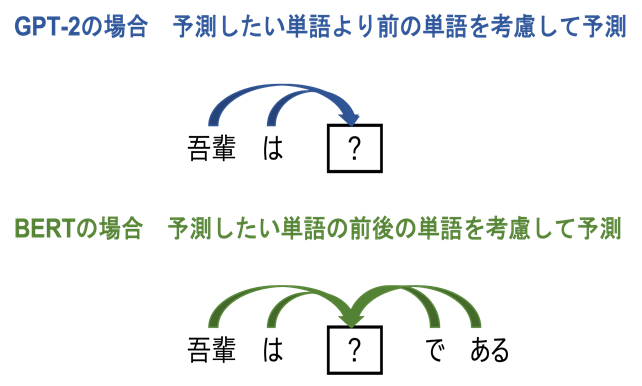 図2:GPT-2とBERTによる単語予測
図2:GPT-2とBERTによる単語予測
![図3:「4年に1度、[MASK]は開催される。」の[MASK]部分を予測した結果](/i/70041/17/resize/d70041-17-f668177e6d72ead5b5af-2.png) 図3:「4年に1度、[MASK]は開催される。」の[MASK]部分を予測した結果
図3:「4年に1度、[MASK]は開催される。」の[MASK]部分を予測した結果
■rinna社の日本語事前学習モデルの特徴
rinna社の日本語事前学習モデルは、以下の特徴があります。
- 学習データとして、日本語CC-100(http://data.statmt.org/cc-100/)と日本語Wikipediaの計75ギガバイトのオープンソースデータを使用しています。
- 8つのNVIDIA Tesla V100 GPUを用いて、75ギガバイトの日本語テキストを、最大45日間かけ学習しました。その結果、すべてのモデルにおいて、十分に学習された汎用性があるモデルとなっています。学習された事前学習モデルはHuggingFaceにMITライセンスで公開されています。
- 事前学習モデルの学習に用いたソースコードはGitHubにMITライセンスで公開されています。利用者は、日本語CC-100とWikipediaのオープンソースデータを用いることで、自分のマシンで当社の結果を再現できます。
- GPT-2ではモデルサイズが異なるGPT2-medium(3.36億パラメータ)、GPT2-small (1.10億パラメータ)、GPT2-xsmall (0.37億パラメータ)の3つのモデルを公開しています。さらに、BERTを改良したRoBERTa (1.10億パラメータ)も公開しています。利用者は目的に合わせたモデルを選択することができます。
- 利用者の目的に沿った多様なタスク(ドメインに特化した文章生成、文章分類、質問応答など)を、当社が公開した事前学習モデルを用いた追加学習により実現できます。
■今後の展開
rinna社の研究チームが開発する大規模な事前学習モデルは、すでに当社の製品に広く利用されています。当社は今後も、AIに関する研究を続け、高性能な製品を開発していきます。また、研究・開発コミュニティに貢献するために、研究成果を公開していく予定です。さらに、他社との協業も進めることで、AIの社会実装の拡大を目指します。
【会社概要】
社名:rinna株式会社
所在地:東京都渋谷区渋谷2-24-12 渋谷スクランブルスクウェア39F WeWork
設立年月日:2020年6月17日
代表取締役:ジャン“クリフ”チェン
Webサイト:https://corp.rinna.co.jp/
業務内容:AIサービスの研究・企画・開発・運営・販売
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザーログイン既に登録済みの方はこちら
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像