新たなNVIDIA Pascal GPUがディープラーニングの推論を加速
Tesla P4とP40アクセラレーター、45倍速いAIを実現 TensorRTとDeepStreamソフトウェアが動画推論のAIを促進

音声起動アシスタントやスパムメール・フィルター、さらに映画や製品をお勧めするレコメンデーション・エンジンなど、現在のAIサービスはますます複雑になっており、1年前のニューラル・ネットワークと比べ最大で10倍の演算を必要としています。現在のCPUベースのテクノロジは、最新のAIサービスに必要なリアルタイムでの反応を提供できず、貧弱なユーザー・エクスペリエンスにつながっています。
Tesla P4とP40は、ユーザーやデバイスからのクエリに反応して、トレーニングされたディープ・ニューラル・ネットワークを使って音声や画像、テキストを認識する「推論」を行うよう特別に設計されています。Pascalアーキテクチャをベースに、これらのGPUは8ビット(INT8)演算をベースとした特殊な推論命令を備え、CPUより45倍(1)、発表されてから1年も経っていないGPUソリューションより4倍(2)速い反応が可能となります。
Tesla P4は、データセンターにとって最高のエネルギー効率を実現します。スモール・フォーム・ファクタや、50ワットという低消費電力でどんなサーバーにもフィットし、実稼働ワークロードでの推論におけるエネルギー効率をCPUと比べ40倍向上させることができます(3)。動画を推論するワークロードの場合、Tesla P4を1個搭載した1台のサーバーは、13個のCPUを搭載したサーバーと同等のパフォーマンスを発揮し(4)、サーバーや電力などにかかる総所有コストを8倍以上削減できます。
Tesla P40は、ディープラーニングのワークロードに最高のスループットを実現します。INT8命令で1秒あたり47テラ・オペレーション(TOPS)の推論パフォーマンスを誇り、Tesla P40アクセラレーターを8個搭載したサーバーは、140個以上のCPUを搭載したサーバーと同等のパフォーマンスを発揮します(5)。CPUサーバー1台が約5,000ドルの場合、サーバー取得費用が65万ドル以上削減できることになります。
NVIDIAのアクセラレーテッド・コンピューティング担当のゼネラル・マネジャーであるイアン・バック(Ian Buck)は、次のように述べています。「Tesla P100そして今回加わったTesla P4とP40で、NVIDIAはデータセンター向けで唯一のエンドツーエンドとなるディープラーニング・プラットフォームを提供することになり、AIの計り知れないパワーが幅広い業界で活用できるようになります。トレーニングに必要な時間は数日から数時間に短縮され、洞察は瞬時に引き出されます。そして、AIを活用したサービスを利用している消費者にリアルタイムで反応することが可能になります。」
より迅速な推論のソフトウェア・ツール
Tesla P4およびP40を補完するのは、AIの推論を加速させるための2つの革新的なソフトウェア、NVIDIA TensorRTとNVIDIA DeepStream SDKです。
TensorRTは、最も複雑なネットワークで即時の反応を提供する製品の展開に向けてディープラーニング・モデルを最適化するために作られたライブラリです。トレーニングされたニューラル・ネット(32ビットまたは16ビットのオペレーションで定義)を使い精度を下げたINT8オペレーションに最適化することで、ディープラーニングのアプリケーションのスループットおよび効率を最大化します。
リアルタイムでビデオ・ストリームを処理する場合、デュアルCPUなら7つのストリームのところを、NVIDIA DeepStream SDKはPascalサーバーのパワーを活用して、最大93のHDビデオ・ストリームを同時にデコード・分析します(6)。これは、自動運転車両、対話型ロボット、広告のフィルタや表示などのアプリケーション向けにビデオ・コンテンツを大きな規模で理解するという、AIにおける最大の課題の1つに対処しています。ディープラーニングをビデオ・アプリケーションに統合することで、企業はこれまで不可能だったスマートで革新的なビデオ・サービスを提供できるようになります。
顧客にとっての大きな躍進
NVIDIAの顧客各社は、最高のコンピューティング・パフォーマンスを要する、これまでよりさらに革新的なAIサービスを提供しています。
Baidu(百度)のシニア・リサーチャーであるグレッグ・ディアモス(Greg Diamos)氏は、次のように述べています。「お客様一人ひとりにシンプルかつ反応性に優れたユーザ・エクスペリエンスを提供することは、当社にとって非常に大切です。当社のDeep Speech 2システムのようにAIを活用したサービスを提供するため、当社はNVIDIA GPUを実稼働で展開しましたが、GPU使用のおかげで、アクセラレーターーを搭載していないサーバーではできなかったであろうレベルでの反応性を実現できています。INT8機能を備えたPascalでさらに大きな前進が可能となるので、ユーザの皆様によりよい体験を提供することを楽しみにしています。」
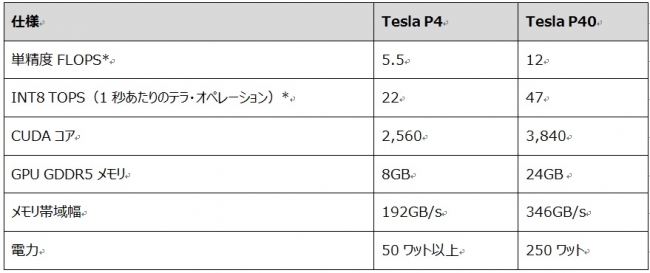
仕様
Tesla P4およびP40 GPUの仕様は以下のとおりです。
提供時期
NVIDIA Tesla P4は11月、Tesla P40は10月に提供開始となる予定で、ODM、OEM、チャネル・パートナーにより提供される認定サーバーに搭載されます。
サポート・リソース
· ディープラーニング・トレーニングと推論の違いとは
· Tesla P4データシート(pdf 126KB)
· Tesla P4データシート(pdf 138KB)
· TensorRT製品ページ
· DeepStream SDK製品ページ
· NVIDIAデータセンターソリューション
· ディープラーニング概要
NVIDIAの最新情報を入手:
NVIDIA公式ブログをご購読ください。Facebook、Google+、Twitter、LinkedIn、Instagramのフォローもお待ちしています。YouTubeではビデオが、Flickrでは画像がお楽しみいただけます。
(1) VGG-19ニューラル・ネットワーク、バッチサイズ=4を使用してレイテンシーを比較。CPU: Xeon E5-2690v4、Intel MKL 2017を使用。GPU: Tesla P40、TensorRTインターナル・バージョンを使用。https://github.com/intel/caffe/tree/master/models/mkl2017_vgg_19でIntelにより最適化されたVGG-19。
(2) Caffe GoogLeNetニューラル・ネットワーク、バッチサイズ=128を使用してimg/secを比較。8x P40のGPUサーバーと8x M40のGPUサーバーを比較。いずれもTensorRTインターナル・バージョンを使用。
(3) Caffe AlexNetニューラル・ネットワーク、バッチサイズ=128を使用しimg/sec/wattを比較。CPU: E5-2690v4でIntel MKL 2017を使用。https://github.com/intel/caffeでIntelにより最適化されたCaffeとAlexNetを使用。GPU: GPU電力をTesla P4で測定。
(4) Intelにより最適化されたGoogLeNet、デュアル・ソケットCPUサーバー、Intel MKL 2017使用のXeon E5-2650v4を使用。DeepStream SDK使用の1x Tesla P4搭載GPUサーバー。ビデオ・ストリーミングは720p @ 30FPS。
(5) GoogLeNetニューラル・ネットワーク、
バッチサイズ=128を使用してimg/secを比較。デュアル・ソケットCPUサーバー、Intel MKL 2017使用のXeon E5-2690v4、358 images/sec。TensorRTインターナル・バージョン使用の8x Tesla P40搭載GPUサーバー、52K images/sec、スループットはCPUサーバーの145倍。
(6) https://github.com/intel/caffe/tree/master/models/mkl2017_googlenet_v2でIntelにより最適化されたGoogLeNetに基づき、デュアル・ソケットE5-2650 v4 CPUサーバー、Intel MKL 2017を使用した、Intelにより最適化されたCaffe。720p @ 30FPSでコード変換を実行。GPU: デュアル・ソケットE5-2650 v4 CPUサーバーでシングルTesla P4を使用。
NVIDIAについて
1993年以来、NVIDIA(NASDAQ: NVDA)は、ビジュアル・コンピューティングという芸術的な科学の世界をリードしてきました。ゲーミング、自動車、データセンターおよびプロフェショナル・ビジュアリゼーションの分野で特化したプラットフォームを提供し続けています。NVIDIAの製品は仮想現実、人工知能、自律走行車の開発においても最新の技術を提供しています。詳しい情報は、http://nvidianews.nvidia.com/をご覧ください。
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザーログイン既に登録済みの方はこちら
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像
