Livetoon、最高クラス(最高精度・最速)の音声合成モデルを開発
日本語音声合成の新スタンダード ― 感情とリアルタイム性を極める音声AI

AIキャラクターとの対話サービス「kaiwa」を開発する株式会社Livetoon(本社:東京都中央区、代表取締役:木下恭佑)は、AIとの自然な会話を実現するため独自開発を進めている次世代TTS(Text-to-Speech)モデルにおいて、現行最高峰モデルを超える読み上げ精度と処理速度を達成したことをお知らせします
本モデル(以下、Livetoon TTS)は、テキスト解析から音響モデル・ボコーダに至るまで、全工程をフルスクラッチで実装、学習しております。日本語に最適化したアーキテクチャと軽量構造により、業界標準を大きく超える品質と低遅延を実現しています。
■ 120ミリ秒の超低遅延 ― “リアルタイム水準”を実現
推論速度の検証では、NVIDIA T4(VRAM 16GB)環境で、短文(20文字)で120ミリ秒、長文(200文字)でも760ミリ秒の読み上げを記録し、短文においては他社モデルの約2倍を達成しました。
100 ミリ秒台の遅延は「人の会話と区別できない体感速度」とされており、当社エンジンはその壁を突破しました。

■ クオリティ:感情が宿る、人間を超える「声」
Livetoonが目指したのは、単なるテキストの読み上げではありません。言葉に込められた感情、ニュアンス、そして「魂」を吹き込むこと。その結果、私たちは現行の最高峰モデルさえも凌駕する、圧倒的な表現力を獲得しました。
特に日本語特有の繊細なイントネーション(抑揚)の再現性は、他社の追随を許しません。喜びで弾む声、真剣な眼差しが目に浮かぶような口調、そして言葉と言葉の間に生まれる絶妙な「間」。これら全てを完璧にコントロールすることで、聞く人の心を動かす「本物の声」お届けします。
さらに本モデルではわずか15分の音声データがあれば、その人に忠実なクローンボイスを最短1分で生成することが可能です。短時間・高精度な再現性により、個人やIPキャラクターの音声展開を迅速に実現できる点も、大きな技術的優位性となっています。
■ 精度でも国内トップラス:日本語の「壁」を打ち破る圧倒的な正解率
日本語における音声合成の最大の壁、それは「漢字の読み」です。
例えば「生年月日」を「しょうねんがっぴ」と読んでしまったり、大人気作品「鬼滅の刃」のキャラクター名を正しく発音できなかったり──。一般的な辞書に載っていない固有名詞や特殊な読み方は私たちの想像を超える数、存在します。これこそが多くの音声合成エンジンが不自然な読み間違いを起こす最大の原因となってきました。
この“日本語の壁”に対し、Livetoonは真正面から向き合いました。
検証として今回開発されたLivetoon TTSと最新の高性能モデルを対象に、読み上げ成功率の比較検証を実施。(※読み上げ文書については公平のため、ChatGPTの出力を参考に使用しました)
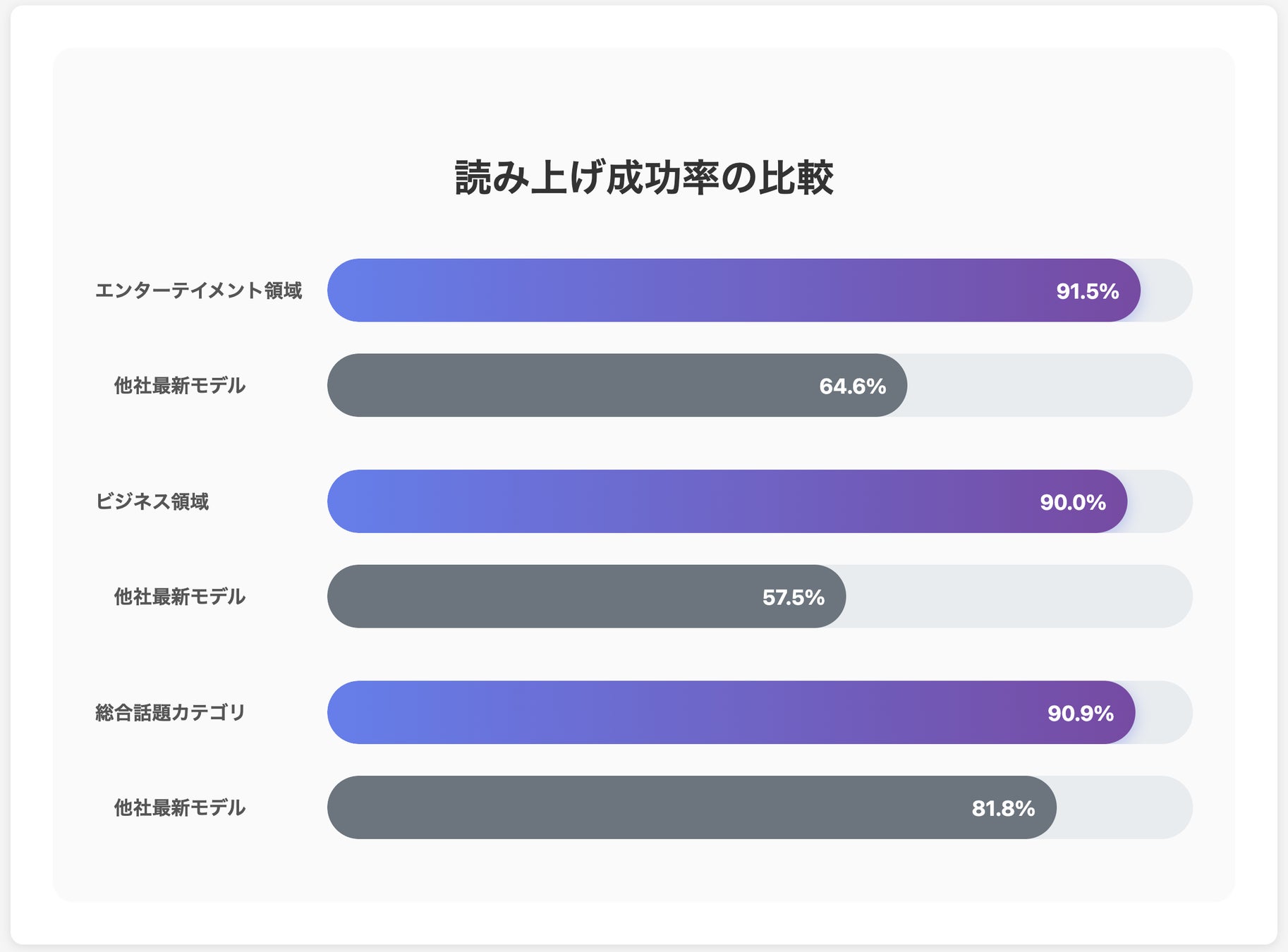
-
エンターテイメント領域: +26.9pt(64.6% vs 91.5%)
-
ビジネス領域: +32.5pt(57.5% vs 90.0%)
-
総合話題カテゴリ: +9.1pt(81.8% vs 90.9%)
Livetoon TTSは全ての領域で他を圧倒。
特に、未知の固有名詞が頻出するエンターテイメント領域やビジネス領域で、他を全く寄せ付けないスコアを叩き出しています。
複雑な人名や地名、ネットで生まれたばかりのスラング、そして創作物ならではの難読漢字まで。どんなテキストが入力されても、常に90%を超える水準で安定して正しい読みを提供します。
※今回の比較検証では行っておりませんが、読み上げ辞書の追加についても対応が可能です。
■ フルスクラッチだからこそ到達できた、圧倒的性能
この「超低遅延」「超高品質」「超高精度」という、本来トレードオフの関係にある3つの要素を最高水準で両立できたのは、既存技術の組み合わせではない、ゼロからのフルスクラッチ開発にこだわったからです。
テキスト解析から音響モデル、ボコーダーに至るまで、全てのコンポーネントを日本語に完全特化させ、それぞれのパーツで最高水準を達成することで今回のモデル完成にこぎつけました。このアプローチこそが、他社には模倣不可能な圧倒的性能の源泉です。
読み上げ音声についてはこちらでご確認いただけます
■ 幅広い用途へ:会話AI・医療・電話応答 ― すべてを支える“日本語音声の新しい標準”
この技術は、Livetoonが提供するAIキャラクターとお話できる「kaiwa」をはじめ、カスタマーサポートの自動応答、医療分野での対話支援、電話受付の自動化など、即時性と正確さが求められるtoB領域での活用をすでに見据えています。
また企業の既存システムやサービスに柔軟に組み込めるAPI提供も視野に入れており、自社サービスとしての完結型から、外部連携まで幅広い活用形態に対応可能です。
「人間と区別がつかない声」での自然な会話体験を必要とするあらゆる現場に、“日本語音声の新しい標準”として、最適な選択肢をお届けしてまいります。
■代表取締役(CEO) 木下 恭佑 のコメント
「言葉は、音になった瞬間に初めて血が通います。今回完成したLivetoon TTSは、3D会話プラットフォーム『kaiwa』を動かす“心臓”そのものです。キャラクターが人と同じテンポで息づき、感情を帯びて返事をする。その当たり前を実装することで、AI は今よりも日常に溶け込む存在となると信じています。私たちが目指すのは、皆が憧れたことのある『人とAIが同じテーブルで笑い合う未来』の実装です。病院で患者様の不安をやわらげる声も、深夜の部屋で孤独に寄り添う対話も、同じTTSが支えます。優れた音声は、『自分とは誰か、他者とは何か』という哲学的な問いへの新しい答えにもなります。kaiwaで生まれる一つひとつの会話が、人間とAIの垣根を溶かし、楽しさと安心が共存する社会を少しずつ広げていく。私たちはそのプロセスこそ最大のエンターテインメントだと信じています。」
■最高技術責任者(CTO) 長嶋 大地 のコメント
「『日本語を最も自然に話すAIを作る』―この無謀とも思える目標に、最高のチームで挑みました。既存技術の改良では決して到達できない領域を目指し、あえて困難なフルスクラッチの道を選びました。テキスト解析の深層からボコーダーの波形ひとつひとつに至るまで、我々の知見と情熱の全てを注ぎ込んでいます。今回の成果は、その執念の結晶です。しかし、これはまだ始まりに過ぎません。私たちは、さらに多様な感情表現、そして個々に寄り添う声の創造に向け、これからも技術の限界に挑戦し続けます。」
■今後の展開
Livetoonでは、本TTSモデルの技術をさらに多くの企業・団体にご活用いただくべく、導入企業様の募集を開始いたします。対話AI、電話応答、医療、教育、エンターテインメントなど、自然な音声が求められるあらゆる分野において、本モデルが新たな価値を創出できると確信しております。
また現在のモデルは中規模データによるトレーニングでこの水準を実現しておりますが、今後10倍以上のデータでの大規模トレーニングを予定しており、さらなる精度・表現力の向上を目指しています。そのために計算資源の拡充と研究開発の加速を進めてまいります。
またTTSモデルをご検討中の企業様には、実際にご体験いただけるデモリンクをご案内しております。APIの一般提供も今後予定しており、自社サービスや既存システムへの柔軟な統合も可能です。
ご興味をお持ちいただいた企業様は、ぜひお気軽にお問い合わせください。
お問い合わせ先:info[at]livetoon.net
■開発メンバー
長嶋 大地 (大分大学医学部卒、現 東大病院循環器内科所属)
大塚 直人 (九州大学医学部卒、現 東大病院循環器内科所属)
DONGKEUN YOO (北海道大学 大学院情報科学院 修士卒)
中村 涼 (青山学院大学経済学部卒)
すべての画像