【医療DX最前線】カルテ入力・議事録作成が変わる!広島大学 佐伯医師が語る「mocoVoice」導入のリアル
〜小児科医療現場のニーズに応え、AI問診システムのデータ収集効率化と医療DXを推進〜

mocomoco株式会社(本社:東京都港区、代表取締役:田中 康紀)は、音声認識AI「mocoVoice」の医療分野における可能性を追求し、広島大学病院 小児外科講師/臨床准教授である佐伯 勇医師と共同で医療モデルの強化に取り組んでいます。 この度、本取り組みの詳細や、佐伯医師が実際にmocoVoiceを導入・活用されたリアルな声、そして今後の医療現場におけるAI音声認識への期待などをまとめたインタビュー記事を、mocomoco株式会社のウェブサイトにて公開いたしました。
▼インタビュー記事全文はこちらからご覧いただけます!
小児科現場に寄り添う医療音声認識─佐伯医師が導くmocoVoice医療モデル強化の取り組み
<連携の背景と目的>
医療現場では、電子カルテ入力やカンファレンス記録など、音声情報のテキスト化が求められる場面が多数存在します。しかし、専門用語の多さや特有の言い回しなどから、汎用的な音声認識システムでは十分な精度が得られず、手作業による修正に多くの時間を費やしているのが現状です。
佐伯医師は、AI問診システムのトレーニングデータ収集プロジェクトにおいて、「医学用語をほとんど理解してくれず、学習もしてくれないため、何度も同じ部分を直す作業にひたすら時間をとられる状況だった」という課題を抱えていました。
このような背景のもと、医学用語への対応と学習による精度向上に強みを持つ「mocoVoice」の医療モデルにご関心をお寄せいただき、本連携が実現いたしました。
<mocoVoice医療モデルの特徴>
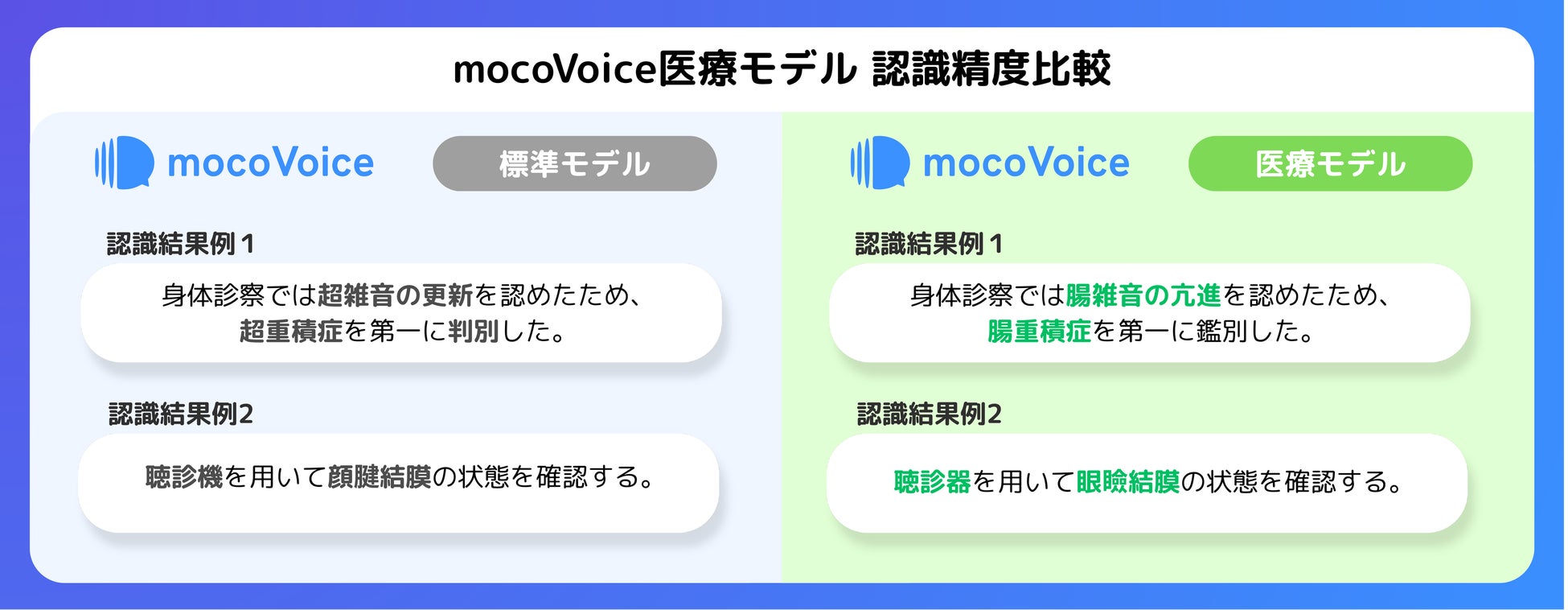
mocoVoiceの医療モデルは、高性能な標準モデルをベースに、医学概念・知識連結データベース「JMED-DICT mini」に収録されている約14万語もの医療専門用語を追加学習しています。この徹底的な専門知識の強化により、標準モデルと比較して医療関連単語の認識において2倍以上の性能向上を実現しました。
さらに、広島大学病院 佐伯医師のような医療現場の最前線で活躍される専門家からの継続的なフィードバックを反映し、日々モデルを改善。これにより、実際の医療現場における複雑な会話や特有の言い回しにも的確に対応し、業界最高水準の高精度な文字起こしを実現します。
主な特徴:
-
圧倒的な医療専門用語認識力:
約14万語の専門用語データベースと現場の声に基づくチューニングにより、難解な医学用語も的確にキャッチ。標準モデルと比較して2倍以上の認識精度を誇ります。
例えば、従来モデルでは「聴診器」が「聴診機」と誤認識されたり、「眼瞼結膜(がんけんけつまく)」が「顔腱結膜」のようにわずかな音の違いで間違ってしまうケースがありましたが、mocoVoice医療モデルではこれらの細かな誤りを大幅に改善し、正確な医療用語として認識します。 -
利用データと専門家の知見で進化を続ける認識エンジン:
実際の利用データや専門家からのフィードバックを定期的に取り込み、認識エンジンをアップデート。利用状況や専門知識を反映することで、システム全体として継続的に認識精度が向上します。
-
劇的な業務効率アップを実現:
高精度な文字起こしにより、手作業による修正時間を大幅に削減。広島大学病院の事例では、文字起こしに関わる作業労力が従来の1/4~1/6にまで軽減されるなど、医療従事者の負担軽減に大きく貢献します。
<広島大学病院 佐伯医師からのコメント>

AI問診のデータ収集では、2時間程度の音声文字起こしに膨大な手間がありました。mocoVoice導入後、mocomoco社との連携とフィードバックでモデルが改善され、修正が必要な言葉が減り作業労力は約1/4に。1時間40分の音声修正も、当初3時間半から2時間未満へと短縮されました。
特に印象的だったのは、過去の症例学習が活き、未知の診察内容でも高精度な文字起こしができた点です。今後はカンファレンス記録、インフォームドコンセント、手術記録など、研究以外への活用も期待しています。
<mocoVoiceについて>
「mocoVoice」は、企業から寄せられた現場の声に応える形で誕生した、オールインワンAI音声認識サービスです。議事録作成も話者分離もこれひとつで対応可能です。
-
高い正確性と処理速度:
大規模言語モデル(LLM)との組み合わせと独自アルゴリズムにより、精度90%以上(※当社調べ)と1時間の音声を最速3分で書き起こす高速処理を両立。
-
文脈を加味した校正機能:
書き起こした文章の誤字脱字を文脈を踏まえて修正し、正確なテキストに仕上げます。
-
用語の辞書登録機能:
医療、法律、金融など業界ごとの専門用語や固有名詞を事前に登録し、正しく書き起こし。読み仮名の登録は不要です。
-
話者分離機能:
最大12人の発話を個別に識別し、「誰が何を話したか」を明確にします。
-
カスタマイズ可能な議事録・要約:
長時間の会話や講義内容を簡潔な要点にまとめます。
-
オンプレミス対応:
セキュリティや機密情報を扱う業界向けに、クラウドを使わず安全にデータを処理できるオンプレミス環境も提供可能です。
(※上記機能の一部は特定のプランやオプションでの提供となる場合があります。)
<今後の展望>
mocomocoは、今回の広島大学病院 佐伯医師との連携を通じて得られた知見を活かし、医療分野における音声認識技術のさらなる精度向上と機能拡充を進めてまいります。引き続き、医療従事者の皆様の業務効率化と医療DXの推進に貢献できるようなサービス開発に努めてまいります。
<サービス利用のお申込み>
mocoVoiceの利用を開始するには、以下の利用申請フォームからお申し込みください。医療モデルのご利用や詳細については、お問い合わせフォームよりご相談ください。
関連ページ
-
mocoVoice 無料トライアル https://cloud.mocomoco.ai/sign-up
-
mocomoco株式会社 HP https://www.mocomoco.ai/
-
mocoVoice医療モデル・記事に関するお問い合わせ https://tayori.com/f/mocomoco-inc/

代表者:代表取締役CEO 田中康紀
本社:〒106-0032 東京都港区六本木7丁目20-19 イナダビル302
広報担当 メール: contact@mocomoco.ai
すべての画像