社内文書に基づいた FAQ システムにおいて ChatGPT の連携を開始
~ カスタマーサポート部門向け ~
当社では、「問い合わせの工数削減」や「カスタマーサポートの回答の質向上」について悩みを持つ企業様に向けて、社内で培った ChatGPT の活用ノウハウに基づいた開発支援を行っています。

1. 自然言語を介することでユーザは知識ベースへ容易にアクセスできます
ChatGPT の普及による AI 共生の内在化に伴い、各方面から大規模言語モデルの活用に期待と懸念の声が寄せられています。特にビジネス方面から期待される活用事例の一つに、社内知識ベースへのアクセス効率化や FAQ の半自動化など RPA の導入が挙げられます。
本システムは、当社に寄せられる案件相談のなかでとりわけ需要の高い検索システムを対象としています。具体的には ChatGPT をはじめとする大規模言語モデルを用いて、表記揺れや曖昧なクエリに堅牢な自然言語を介したインターフェースを持つ検索システムを提供することで、知識ベースへのアクセス効率化を図ります。
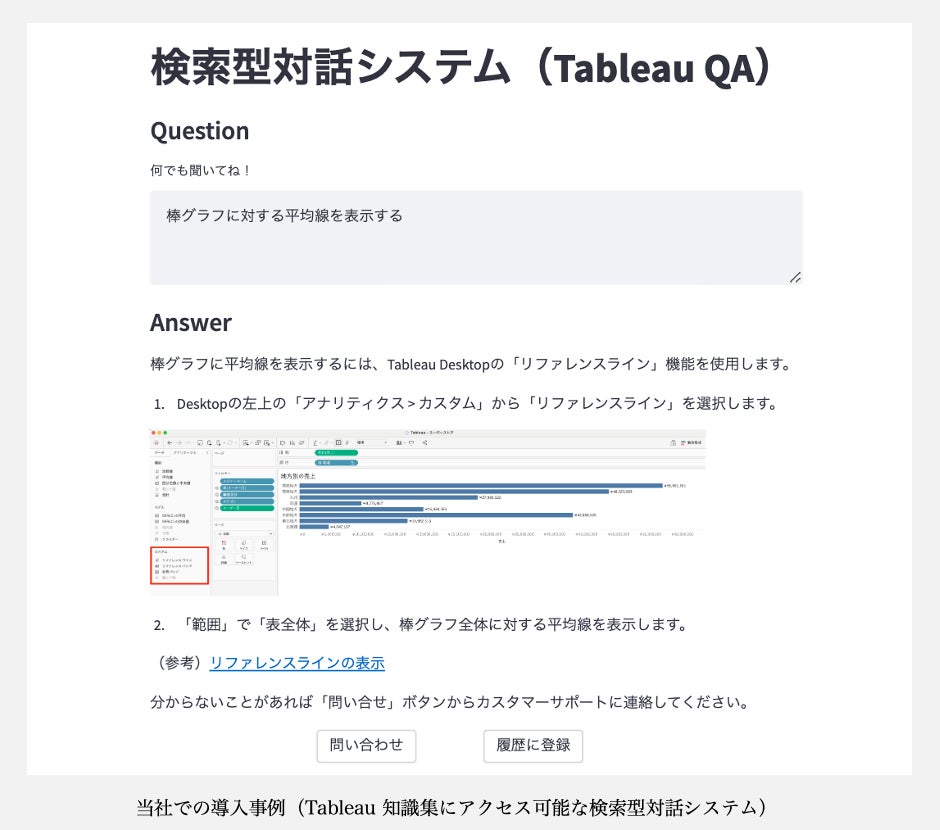
また本システムは機能追加などカスタマイズ可能な設計となります。当社では導入事例の一つとして Tableau に関連する知見集にアクセス可能な対話型検索システムを社内向けに公開しており、以下は実際の応答例です。なお Tableau とは可視化と分析機能を備えた BI ツールであり、当社では Tableau ダッシュボード作成や FAQ 対応を行っております。
【Tableauソリューション】
https://www.keywalker.co.jp/tableau/tableau.html
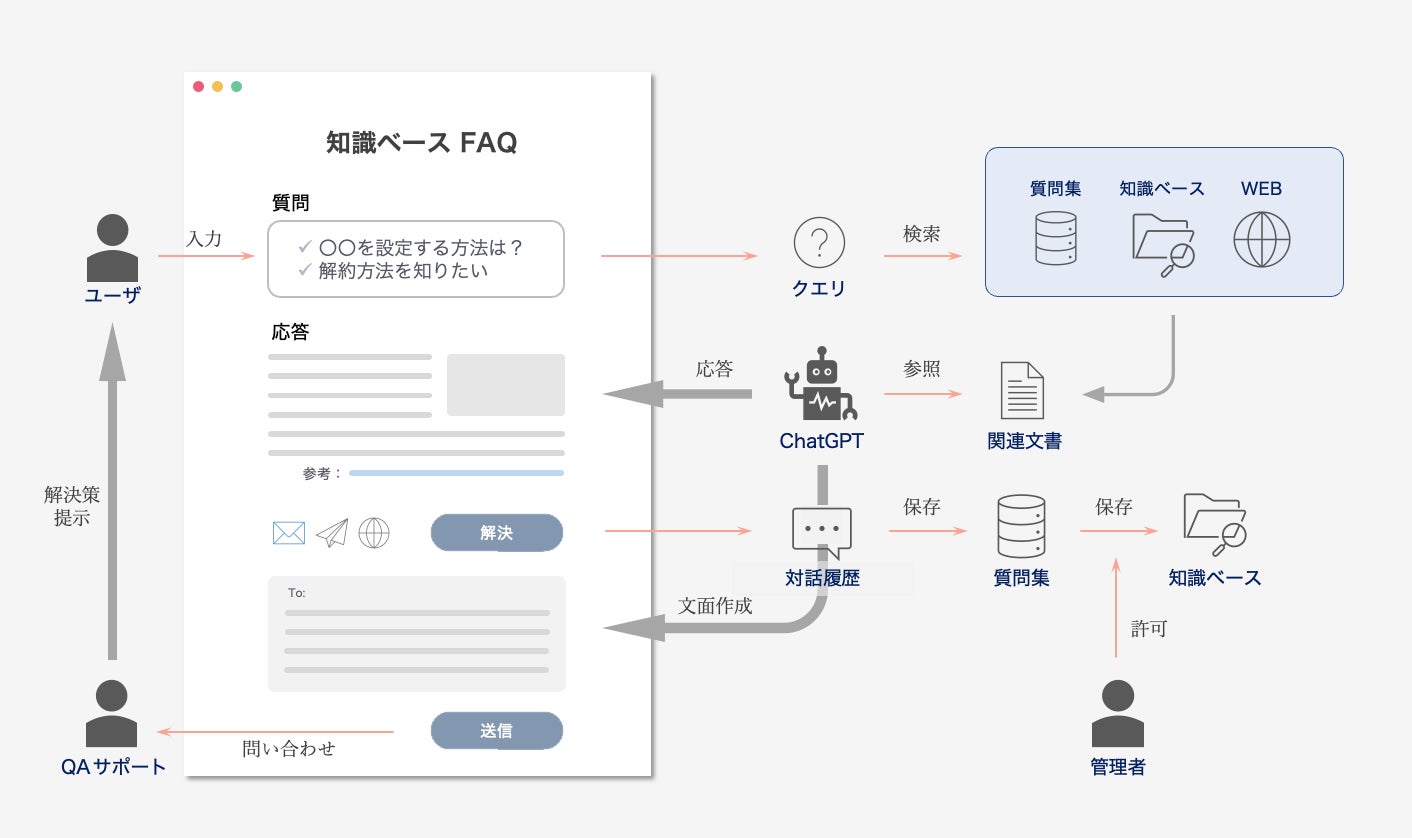
■ 知識ベースを柔軟に選択可能な検索システム
本システムはユーザの質問に回答するために参照する知識資源を3つ定義しています。
社内知識ベース(クローズな外部知識)
読み権限が付与された社内文書を参照します。Google 検索 (オープンな外部知識)
知識ベースでは解決できない質問に対して Web 上の外部知識を参照できます。過去の対話履歴 (言語モデル内部知識)
メモリに登録された対話履歴を参照できます。再現性の担保や生成誤りを軽減します。
質問に正しく回答するために、これらの知識資源から質問に関連する文書を検索します。具体的には ①類似する意味表現の検索 ②専門用語などに堅牢な表層検索、によるハイブリッド検索を行います。また構築済みの検索システム(Elasticsearch など)と連携することも可能です。
■ 正確な応答生成を目指しつつ、生成誤りに備えたユーザ体験の提供
ChatGPT など大規模言語モデルの業務利用において「事実関係に矛盾した応答を生成してしまう」生成誤りが問題視されますが、ヒトと同様、言語モデルもユーザ要求に漏れなく応答することは困難です。
そこで当社は5つの観点から生成誤りに対する工夫に取り組んでいます。
誤りを出力しない
検索システムが取得した関連文書に基づいて応答生成を行います。誤りを検知する
関連文書と応答文を比較して整合性が取れているか判定します。説明性を担保する
参照元のページを出力根拠として提示します。誤り発生時の別の切り口を用意する
ヒトがフィードバックを行うための外部システム連携を整備します。同じ誤りを繰り返さない
対話履歴をメモリに登録することで次回以降参照できるようにします。
2. ユーザは UI から半自動的に知識ベースを更新できます
知識ベースを活用する側面について説明しましたが、知識ベースを風化させずに継続的に運用することも重要な側面の1つです。我々はユーザによる「検索 > 行動 > 共有」のプロセスを円滑に進めることを目的に、ユーザからの共有に基づいて知識ベースを更新します。
具体的には生成された応答に対してユーザが「解決したか」を判断を行い、以下の方法で共有プロセスを実現します。
■ 解決した場合 〜 ユーザ生成コンテンツによる対話履歴の再利用
モデルから適切な応答が生成された場合、クエリと応答のペアは対話履歴としてメモリに保存されます。保存された対話履歴は、次回以降の質問に対してアクセス可能となり、類似した質問が入力された場合に対話履歴に基づいて応答生成ができるようになります。
また、メモリに保存された対話履歴は社内知識ベースに記事として登録することができます。知識ベースに記事を登録したい場合は、UI上で対話履歴を修正し、作成された記事を待ち行列に追加します。待ち行列に追加された記事は、知識ベースへの追加権限が付与された管理者によって監視され、承認された記事のみが知識ベースに登録されます。
■ 解決しない場合 〜 コミュニケーションツールを連携した問い合わせ
生成誤りによってユーザ要求が満たされなかった場合は、メールや slack などのコミュニケーションツールを用いて、第三者(回答者)への問い合わせを行います。この際、回答者が理解しやすいよう曖昧性のない問い合わせの草案を ChatGPT が代筆することで、ユーザの文面作成の手間を軽減します。ユーザは作成された文面に対して、修正・承諾のみで問い合わせを送信することができます。
今後の展開
大規模言語モデルが普及したことで、誰でも簡単に記事を作成できるようになった社会的な側面から見ると、今後は情報の信頼性がますます重要になると考えられます。当社では、社内知識ベースを忠実に反映したより正確な応答生成の実現やレイテンシの向上を目指すと同時に、柔軟な保守の実現を目指します。
当社概要
■ データソリューションについて
当社は、データを必要とする様々な企業・研究機関に対してWeb サイトをはじめとした外部データを収集し、企業内に保有するデータと統合して分析・可視化まで行っております。
収集したデータを可視化することで、生産性やコスト効率の向上、経営判断の迅速化を実現でき、そこからインサイトを導き、より優れたアクションの模索に繋げられます。
データを収集するだけでなく、可視化まで行うワンストップソリューションにより、生産性やコスト効率の向上、経営判断の迅速化を実現するデータドリブンな組織作りを支援しております。
【テキスト分析支援サービス】
自然言語処理の教師データ作成から学習モデル作成、分析実行・可視化まで支援!
https://www.keywalker.co.jp/data-analysis/natural-language-processing.html
【Tableauソリューション】
ビッグデータを美しく分かりやすく可視化・分析!
https://www.keywalker.co.jp/tableau/tableau.html
【レビュー分析ダッシュボード】
自社と他社製品のレビューを収集・分析・可視化!
https://www.keywalker.co.jp/data-analysis/review-analytics-dashboard.html
【ビジネスを加速するWebデータ抽出サービス:ShtockData】
国内シェアNo.1!のWebスクレイピングサービス!
■ 株式会社キーウォーカーについて
名称 :株式会社キーウォーカー
所在地 :東京都港区西新橋1丁目8−1REVZO虎ノ門 4F
代表取締役:沼崎 弘
設立 :2000年11月22日
事業内容 :ビッグデータの収集・整理・分析・可視化ソリューションの提供
自然言語処理エンジンの研究開発
ルーチン業務の自動処理システムの提供
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像