Qlean Dataset、「日本語・1話者・台本朗読音声コーパスとトランスクリプト」を提供開始
〜GENIAC採択企業のVisual Bank、音声・言語AI開発向けの日本語音声データでASR/LLM開発を支援〜

Visual Bank株式会社(東京都港区、代表取締役CEO 永井真之)は、傘下の株式会社アマナイメージズを通じて展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」において、ASR(自動音声認識)、NLP(自然言語処理)、LLM(大規模言語モデル)などの音声・言語系AI開発に向けた「日本語・1話者・台本朗読音声コーパスとトランスクリプト」の提供を開始しました。
本データセットは、Qlean Datasetが展開する機械学習用データセットラインナップ『AIデータレシピ』に新たに加わるもので、日本語の台本を日本人男性話者が朗読した音声と、その発話内容を忠実に書き起こしたトランスクリプトを収録しています。発話内容は事前に用意された台本に基づいて構成されており、文構造や語彙の対応関係が明確な日本語音声・テキストデータとして整理されています。
収録は一話者による朗読形式で行われており、自然発話に見られる言い直しや話題の逸脱を抑えた構成となっています。そのため、音声とテキストの対応付けが必要となる音声認識モデルの学習や評価、音声入力を前提とした言語処理パイプラインの検証など、基礎的な音声言語処理タスクを想定した利用に適したデータ構成となっています。
Qlean Datasetでは、研究用途から商用利用を前提としたAI開発までを見据え、権利処理や利用条件を整理したデータ提供を行っています。本データセットもその一環として、日本語音声と言語情報の対応関係を扱うAI開発・検証環境の整備を目的に提供されます。
今回提供を開始する「日本語・1話者・台本朗読音声コーパスとトランスクリプト」の概要

|
データ種別 |
音声、テキスト |
|---|---|
|
被写体属性 |
日本人、男性 |
|
データ形式 |
音声データ:mp3 テキストデータ:txt,json,csv |
|
音声レート |
44.1kHz / 48kHz |
|
サンプル詳細 |
「日本語・1話者・台本朗読音声コーパスとトランスクリプト」のユースケースイメージ
【研究用途】
-
日本語ASRモデルの基礎評価
日本語音声認識における音声とテキストの対応関係を明確に扱うため、単一話者・台本朗読音声を用いてASRモデルの認識精度や誤り傾向を検証する用途に利用できます。
【産業用途】
-
音声入力を含むLLM・音声言語処理パイプラインの検証
音声入力をテキストに変換する前段処理や、音声認識結果を言語モデルに接続する処理フローの検証において、日本語音声と正確なトランスクリプトが対になったデータとして利用できます。
【その他実需要】
-
音声言語処理システムの学習・評価用データ
音声認識や音声テキスト変換の仕組みを学ぶ教育用途や、既存モデルの動作確認・比較検証を行うための評価用データとして利用できます。
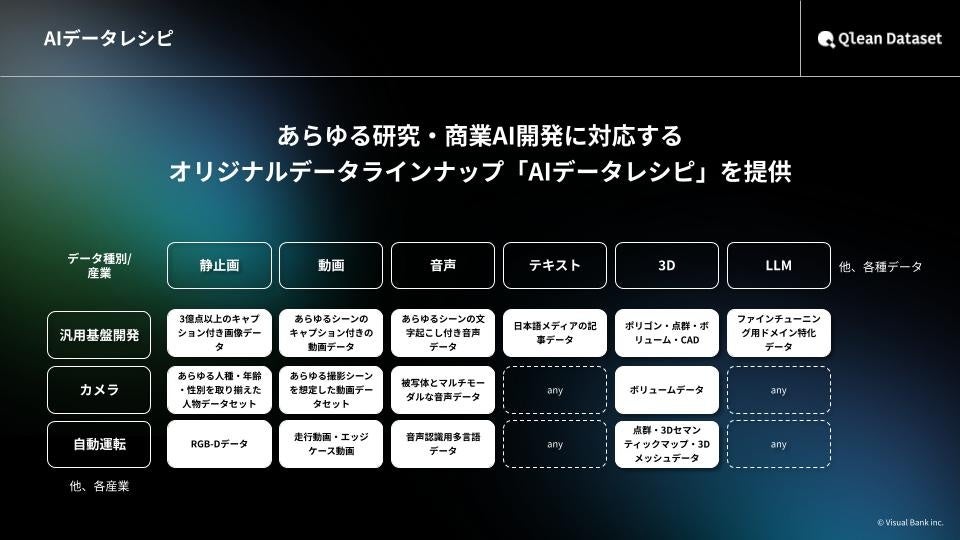
『Qlean Dataset(キュリンデータセット)』について
『Qlean Dataset』は、Visual Bank傘下の株式会社アマナイメージズが提供する商用利用可能なAI学習用データソリューションです。
画像・動画・音声・3D・テキストなど、多様な形式のデータに対応し、研究・商用いずれの用途でも安全に利用できる環境を整備しています。
また、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社をはじめとするデータパートナーとの協業を通じ、業界特化・最新トレンドに即したデータラインナップ『AIデータレシピ』を継続的に拡充しています。
Qlean Datasetは、AI開発現場におけるデータ収集・整備の負荷を軽減し、権利クリアで法的リスクのないAI開発環境の構築を支援します。
▶ Qlean Datasetサイト:https://qleandataset.visual-bank.co.jp/
▶ AIデータレシピ:https://qleandataset.visual-bank.co.jp/lineup
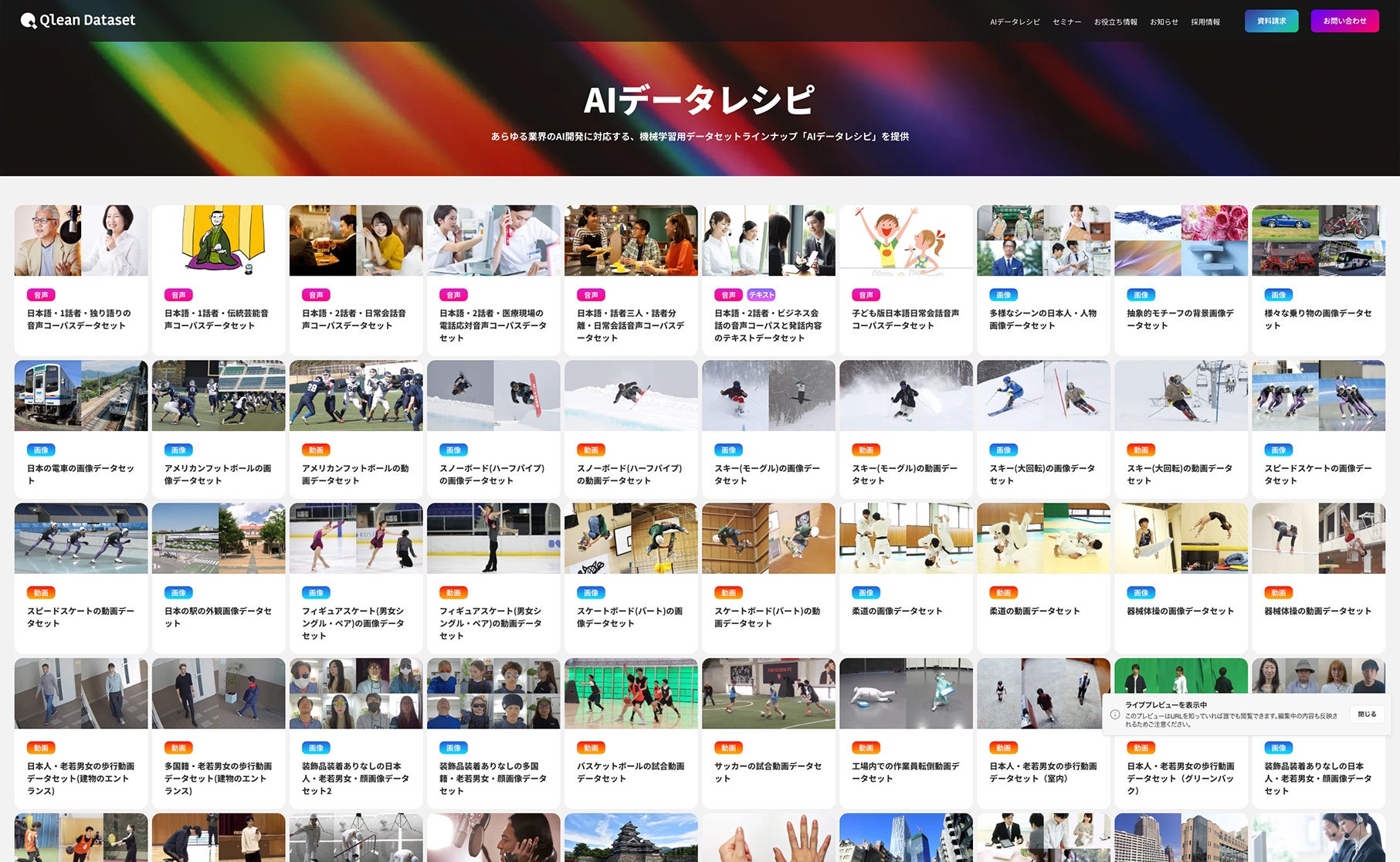


『Qlean Dataset』の提供するデータセット『AIデータレシピ』の特徴
-
すべての被写体から同意取得
-
既存データは最短1日で納品可能
-
カスタム撮影・収録・収集による独自データ構築にも対応
Visual Bank株式会社
AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業として、「あらゆるデータの可能性を解き放つ」をミッションに掲げ事業活動を展開。漫画家の「もっと描きたい!」をサポートするAI補助ツールを提供する『THE PEN』の他、AI学習用データセット開発サービス『Qlean Dataset(キュリンデータセット)』を提供する株式会社アマナイメージズを100%子会社に持つ。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択され、社会実装に向けた取り組みを加速させています。
代表取締役CEO:永井 真之
所在地:〒107-0062 東京都港区南青山7-1-7 C-Cube南青山ビル6F
Visual Bank企業URL:https://visual-bank.co.jp/
アマナイメージズ企業URL:https://amanaimages.com/about/
【Translation】

Qlean Dataset Launches a Japanese Single-Speaker Scripted Read Speech Dataset with Transcripts
Clean Audio–Text Alignment for Japanese ASR Training and Evaluation
Visual Bank Inc. (Minato-ku, Tokyo; CEO: Saneyuki Nagai), through its subsidiary amanaimages Inc., has launched a new dataset as part of its AI training data solution, Qlean Dataset: the Japanese Single-Speaker Scripted Read Speech Corpus with Transcripts. The dataset is intended for the development and evaluation of speech- and language-based AI systems, including Automatic Speech Recognition (ASR), Natural Language Processing (NLP), and Large Language Models (LLMs).
The dataset is included in Qlean Dataset’s machine learning dataset lineup, AI Data Recipe. It features Japanese audio recordings in which a native Japanese male speaker reads prepared scripts aloud, with each recording paired with accurate transcripts that faithfully represent the spoken content. The use of scripted speech ensures clear alignment between audio and text, making the dataset suitable for tasks that require explicit correspondence between spoken language and written text.
All recordings follow a single-speaker, read-aloud format, minimizing disfluencies commonly found in spontaneous speech, such as self-corrections or topic drift. This structure supports foundational speech and language processing tasks, including the training and evaluation of speech recognition models and the validation of speech-to-text–based processing pipelines.
Qlean Dataset provides AI training data for both research and commercial development, with usage conditions and rights clearance clearly defined. This dataset is offered as part of that framework to support AI development and evaluation environments that require reliable alignment between Japanese speech and textual data.
Dataset Overview: Japanese Single-Speaker Scripted Read Speech Corpus with Transcripts
|
Data Type |
Audio, Text |
|---|---|
|
Speaker Attributes |
Japanese, Male |
|
Data Format |
Audio: MP3 Text: txt,json,csv |
|
Sampling Rate |
44.1 kHz / 48 kHz |
|
Sample Details |
Use Case Examples
Research Use Cases
-
Baseline Evaluation of Japanese ASR Models
The dataset can be used to evaluate recognition accuracy and error patterns in Japanese ASR systems, leveraging single-speaker scripted speech where audio–text correspondence is explicitly defined.
Industrial Use Cases
-
Validation of LLM and Speech-Language Processing Pipelines with Voice Input
The paired Japanese speech and accurate transcripts can be used to verify preprocessing stages that convert speech to text, as well as downstream pipelines that connect ASR outputs to language models.
Additional Practical Applications
-
Training and Evaluation Data for Speech and Language Processing Systems
The dataset is suitable for educational purposes, such as learning the fundamentals of speech recognition and speech-to-text conversion, as well as for evaluating and comparing the behavior of existing models.
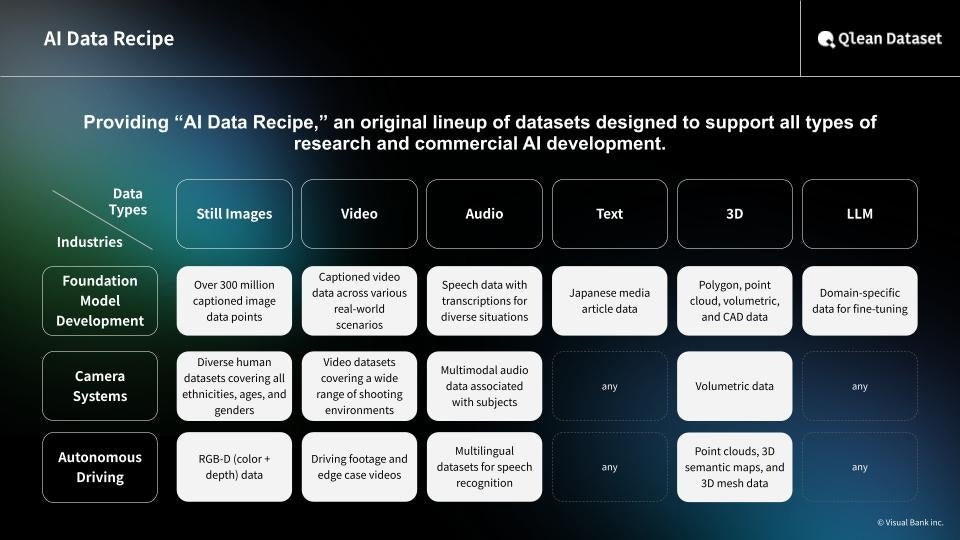
About Qlean Dataset
Qlean Dataset is a commercial-use-ready AI training data solution provided by Amana Images Inc., a subsidiary of Visual Bank Inc.
It supports a wide range of data types, including images, videos, audio, 3D assets, and text, enabling both research and commercial AI development in a legally safe environment.
Through collaborations with data partners such as Chiba Lotte Marines Co., Ltd. and Toyo Keizai Inc., Qlean Dataset continues to expand its specialized, industry-focused lineup known as the “AI Data Recipe.”
By reducing the operational burden of data collection and preparation, Qlean Dataset helps organizations establish AI development environments that are both legally compliant and risk-free.
▶ Qlean Dataset: https://qleandataset.visual-bank.co.jp/en
▶ AI Data Recipe: https://qleandataset.visual-bank.co.jp/en/lineup
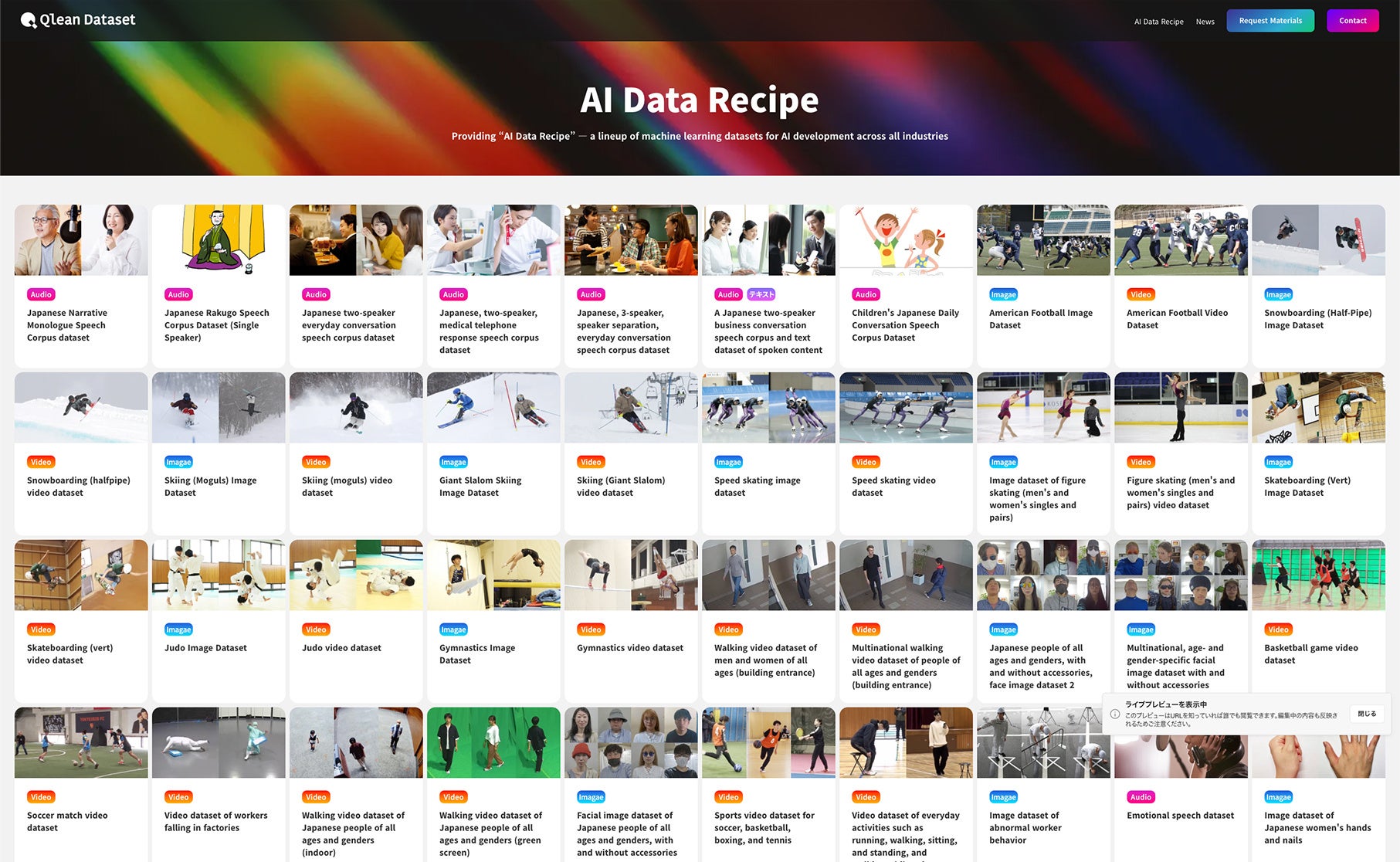


Key Features of Qlean Dataset
-
Existing datasets deliverable within one business day
-
Custom data collection and recording services available
About Visual Bank Inc.
Visual Bank Inc. is a Tokyo-based startup building Next-Generation Data infrastructure to enhance AI development capabilities under the mission “Unlocking Data Accessibility.”
The company operates THE PEN, an AI-assisted creative tool for manga artists and the Qlean Dataset service.
Its subsidiaries include Amana Images Inc., one of Japan’s largest photostock providers; Qlean Dataset, which leads research and development in AI data; and THE PEN Inc., an AI-assisted creative tool for manga artists.
CEO: Saneyuki Nagai
Address: 6F, C-Cube Minami Aoyama Building, 7-1-7 Minami-Aoyama, Minato-ku, Tokyo
Corporate Site: https://visual-bank.co.jp/en
Amana Images: https://qleandataset.visual-bank.co.jp/en/company-overview
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像