国内最大規模の日本語言語処理資源「SudachiDict」および「chiVe」をOpen Data on AWSで公開開始
ー自然言語処理技術で日本語の曖昧さを吸収し、さらに便利でオープンなシステムへー
株式会社ワークスアプリケーションズ(本社:東京都港区、代表取締役最高経営責任者:井上直樹、以下 ワークス)は、この度、2020年10月9日(金)より、ワークス徳島人工知能NLP研究所(以下、同研究所)が開発した国内最大規模の日本語言語処理資源「SudachiDict」および「chiVe」をOpen Data on AWSにて公開を開始したことをお知らせいたします。
以前より本製品を商用利用可能なライセンスにて無償公開していましたが、大規模な言語資源であるためデータサイズが非常に大きく、取り扱いが難しいというご意見をいただいておりました。今回、Open Data on AWS上で公開することで、さらに使いやすく、オープンにご利用いただけるようになります。
公開先URL:https://registry.opendata.aws/sudachi/
SyncThought社、リクルート社など複数企業の製品サービスで「Sudachi Dict」は活用されています
特徴
(1) 1つの語に対する複数の分割情報を付与
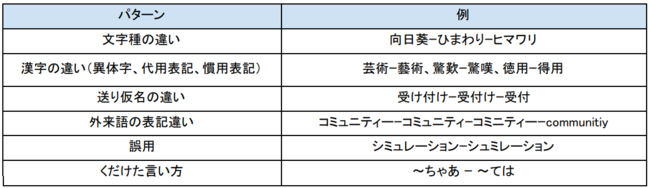
日本語処理に必要な語の区切りは必ずしも一意ではありません。「SudachiDict」ではさまざまな利用シーンにあうよう3種類の区切りを用意しているため、用途に応じて区切り方を選べます。
日本語では同じ語がさまざまな表記で書かれることがあります。これらの表記を正規化することにより同一のものとして統一的に扱うことができます。
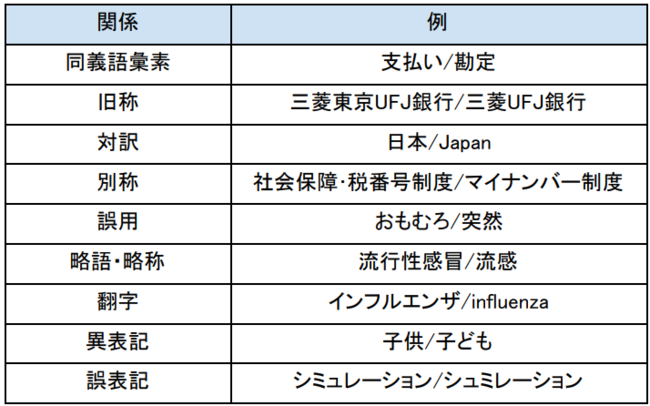
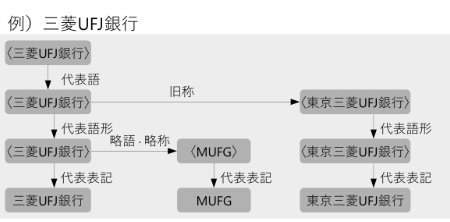
SudachiDictでは収録語に同義語の情報を付与しており、全文検索を始めさまざまな用途に利用できます。
また同義語の関係を精密に記述するために階層化された詳細な同義関係を導入しています。
特徴
(1)国内最大258億語規模のコーパスにて学習を実施
国立国語研究所による超大規模なコーパス「NWJC」を利用して学習しています。これは、ウェブ上の様々な情報源から作成された日本語のテキストデータセットです。分散表現の学習においてはデータ量が重要なファクターとなることが知られています。今回この超大規模コーパスを利用することにより、小・中規模なデータによるリソースに比べて、更に有益なものになることが想定されます。
(2)人名や地名、ブランド名、企業名などの固有表現を大量に追加
「SudachiDict」は290万以上の語彙を含み、その中には多くの新語も存在します。この類をみない高品質で大規模な辞書を利用することで、既存の辞書ではカバーできなかった幅広い固有表現な複合語に対する分散表現を学習できます。
(3)複数分割情報を活用することにより、語の内部構造を考慮した高性能化を実現
「Sudachi※1」と「SudachiPy※2」を利用することで、辞書内に付与されている様々な情報を効率的に利用できます※3。また、全文検索エンジン「Elasticsearch」から利用可能なプラグインも公開しています※4。
「chiVe」と「SudachiPy」は、多言語対応自然言語処理フレームワークである「spaCy※5」、日本語自然言語処理オープンソースライブラリ「GiNZA※6」からも利用可能です。
豊富な語彙を収録する「SudachiDict」および「chiVe」を活用することによりコンピュータによる日本語の処理を向上させ、企業内に眠る様々なデータの解析、活用の実現を促進します。
詳細URL:https://aws.amazon.com/jp/opendata/
なお、Amazon Web Services ブログにおいて、今回Open Data on AWS上で公開する「SudachiDict」および「chiVe」についてご紹介いただいています。
ワークスが開発するERPパッケージソフト「HUE」は企業内に蓄積されるオペレーションログを機械学習のトレーニングデータとして活用しています。
本研究所では「HUE」に蓄積されるオペレーションログをより有効活用し、よりユーザーニーズに即したAI機能を実用化するために自然言語処理を活用した研究開発を進めています。
◆ワークス徳島人工知能NLP研究所では共に働く仲間を募集しています。
詳細URL:https://job.axol.jp/vb/c/worksap/job/detail/cGrkDH85Yx0o-
※1 https://github.com/WorksApplications/Sudachi
※2 https://github.com/WorksApplications/SudachiPy
※3 https://github.com/WorksApplications/Sudachi/blob/develop/README.md
※4 https://github.com/WorksApplications/elasticsearch-sudachi
※5 https://spacy.io/
※6 https://megagonlabs.github.io/ginza/
株式会社ワークスアプリケーションズ サイト https://www.worksap.co.jp/
設立:1996年7月
代表取締役最高経営責任者:井上直樹
事業内容:大手企業向けERPパッケージソフト「HUE」
および「ArielAirOne」の開発・販売・サポート
URL:https://www.worksap.co.jp/
* 会社名は各社の商標又は登録商標です。
* 本リリースに掲載された内容は発表日現在のものであり、予告なく変更または撤回される場合があります。また、本リリースに掲載された予測や将来の見通し等に関する情報は不確実なものであり、実際に生じる結果と異なる場合がありますので、予めご了承ください。
公開先URL:https://registry.opendata.aws/sudachi/
- 「SudachiDict」とは

SyncThought社、リクルート社など複数企業の製品サービスで「Sudachi Dict」は活用されています
特徴
(1) 1つの語に対する複数の分割情報を付与
日本語処理に必要な語の区切りは必ずしも一意ではありません。「SudachiDict」ではさまざまな利用シーンにあうよう3種類の区切りを用意しているため、用途に応じて区切り方を選べます。

日本語では同じ語がさまざまな表記で書かれることがあります。これらの表記を正規化することにより同一のものとして統一的に扱うことができます。
SudachiDictでは収録語に同義語の情報を付与しており、全文検索を始めさまざまな用途に利用できます。
また同義語の関係を精密に記述するために階層化された詳細な同義関係を導入しています。
(4) 継続的な語彙の拡充・整備
言葉は日々変化しています。実用的な日本語処理のためには新語や言葉の新しい使われ方に追随する必要があります。SudachiDictでは継続的に語彙の拡充・整備を続け、常に最新の辞書を提供していきます。
- 「chiVe(チャイブ)」とは
特徴
(1)国内最大258億語規模のコーパスにて学習を実施
国立国語研究所による超大規模なコーパス「NWJC」を利用して学習しています。これは、ウェブ上の様々な情報源から作成された日本語のテキストデータセットです。分散表現の学習においてはデータ量が重要なファクターとなることが知られています。今回この超大規模コーパスを利用することにより、小・中規模なデータによるリソースに比べて、更に有益なものになることが想定されます。
(2)人名や地名、ブランド名、企業名などの固有表現を大量に追加
「SudachiDict」は290万以上の語彙を含み、その中には多くの新語も存在します。この類をみない高品質で大規模な辞書を利用することで、既存の辞書ではカバーできなかった幅広い固有表現な複合語に対する分散表現を学習できます。
(3)複数分割情報を活用することにより、語の内部構造を考慮した高性能化を実現

- 「SudachiDict」および「chiVe」の活用方法
「Sudachi※1」と「SudachiPy※2」を利用することで、辞書内に付与されている様々な情報を効率的に利用できます※3。また、全文検索エンジン「Elasticsearch」から利用可能なプラグインも公開しています※4。
「chiVe」と「SudachiPy」は、多言語対応自然言語処理フレームワークである「spaCy※5」、日本語自然言語処理オープンソースライブラリ「GiNZA※6」からも利用可能です。
豊富な語彙を収録する「SudachiDict」および「chiVe」を活用することによりコンピュータによる日本語の処理を向上させ、企業内に眠る様々なデータの解析、活用の実現を促進します。
- Open Data on AWSとは
詳細URL:https://aws.amazon.com/jp/opendata/
なお、Amazon Web Services ブログにおいて、今回Open Data on AWS上で公開する「SudachiDict」および「chiVe」についてご紹介いただいています。
- ワークス徳島人工知能NLP研究所
ワークスが開発するERPパッケージソフト「HUE」は企業内に蓄積されるオペレーションログを機械学習のトレーニングデータとして活用しています。
本研究所では「HUE」に蓄積されるオペレーションログをより有効活用し、よりユーザーニーズに即したAI機能を実用化するために自然言語処理を活用した研究開発を進めています。
◆ワークス徳島人工知能NLP研究所では共に働く仲間を募集しています。
詳細URL:https://job.axol.jp/vb/c/worksap/job/detail/cGrkDH85Yx0o-
※1 https://github.com/WorksApplications/Sudachi
※2 https://github.com/WorksApplications/SudachiPy
※3 https://github.com/WorksApplications/Sudachi/blob/develop/README.md
※4 https://github.com/WorksApplications/elasticsearch-sudachi
※5 https://spacy.io/
※6 https://megagonlabs.github.io/ginza/
株式会社ワークスアプリケーションズ サイト https://www.worksap.co.jp/

設立:1996年7月
代表取締役最高経営責任者:井上直樹
事業内容:大手企業向けERPパッケージソフト「HUE」
および「ArielAirOne」の開発・販売・サポート
URL:https://www.worksap.co.jp/
* 会社名は各社の商標又は登録商標です。
* 本リリースに掲載された内容は発表日現在のものであり、予告なく変更または撤回される場合があります。また、本リリースに掲載された予測や将来の見通し等に関する情報は不確実なものであり、実際に生じる結果と異なる場合がありますので、予めご了承ください。
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザーログイン既に登録済みの方はこちら
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像