さらに上手に“忘れる”AIへ ― 学習済みの知識をドメイン単位で忘却可能な世界初の新技術 ~ 不要な誤認を防ぎ、さらに信頼できるAIへ ~
【研究の要旨とポイント】
事前学習済み大規模視覚言語モデル (Vision-Language Model: VLM)に対して、特定のドメインに属するデータだけを認識できないように“忘却”させる『近似ドメインアンラーニング (Approximate Domain Unlearning: ADU)』技術を世界で初めて提案・創出しました。
特徴空間上で異なるドメインを分離する『Domain Disentangling Loss (DDL)』と、画像ごとのドメイン特性を適応的に捉える『Instance-wise Prompt Generator (InstaPG)』を新たに導入し、従来困難だったドメイン単位での選択的忘却を実現しました。
4種類の標準的な画像認識テストデータにおいて、従来手法と比べ平均約1.6倍の性能向上を達成しました。
AIが保持する知識を目的に応じて柔軟に制御できる新たな設計原理を提示し、安全で信頼性の高いAI活用への道を拓きました。
【研究の概要】
東京理科大学 工学部 情報工学科の入江 豪 准教授、川村 輝大 氏(2024年度 学士課程卒業、現 シンガポール国立大学 計算機科学科博士課程学生)、同大学大学院 工学研究科 情報工学専攻の後藤 優太 氏(2024年度 修士課程修了)、産業技術総合研究所 人工知能研究センター コンピュータビジョン研究チームの片岡 裕雄 上級主任研究員、柳 凛太郎 研究員の共同研究グループは、事前学習済み大規模視覚言語モデル (Vision-Language Model: VLM, *1)に対し、特定のドメイン(*2)だけを認識できないように“忘却”させる新たな技術『近似ドメインアンラーニング (Approximate Domain Unlearning: ADU)』を世界で初めて提案・創出しました。これにより、AIがあらゆる画像を一律に認識してしまうことによる誤認や信頼性上のリスクを抑えつつ、利用目的に応じて柔軟に知識を制御できる新たなAIの可能性を示しました。
事前学習済み大規模VLMは、多様なドメインに属する画像を高精度に認識できる強力な汎化能力を持ち、さまざまな用途で優れた性能を発揮しています。しかし、その“万能性”は常に望ましいとは限りません。あらゆるドメインの画像を区別なく認識できてしまうことで、用途によっては誤認識や信頼性上のリスクを生じることがあります。たとえば、交通監視システムや自動運転システムが、街頭ディスプレイや広告などに描かれた「人」や「自動車」のイラストを、実物のそれらと区別なく「人」や「自動車」として認識してしまうと、誤った解析結果を導き出すおそれがあります。
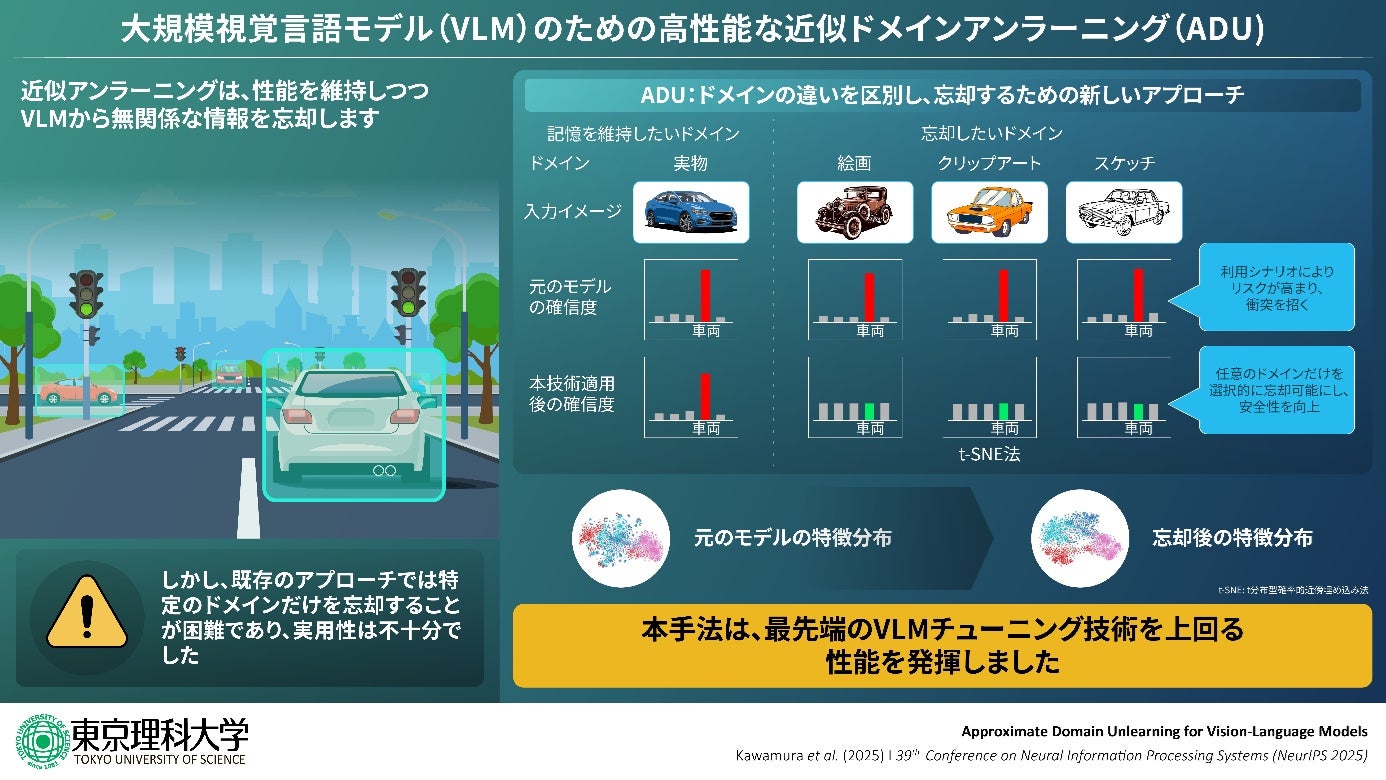
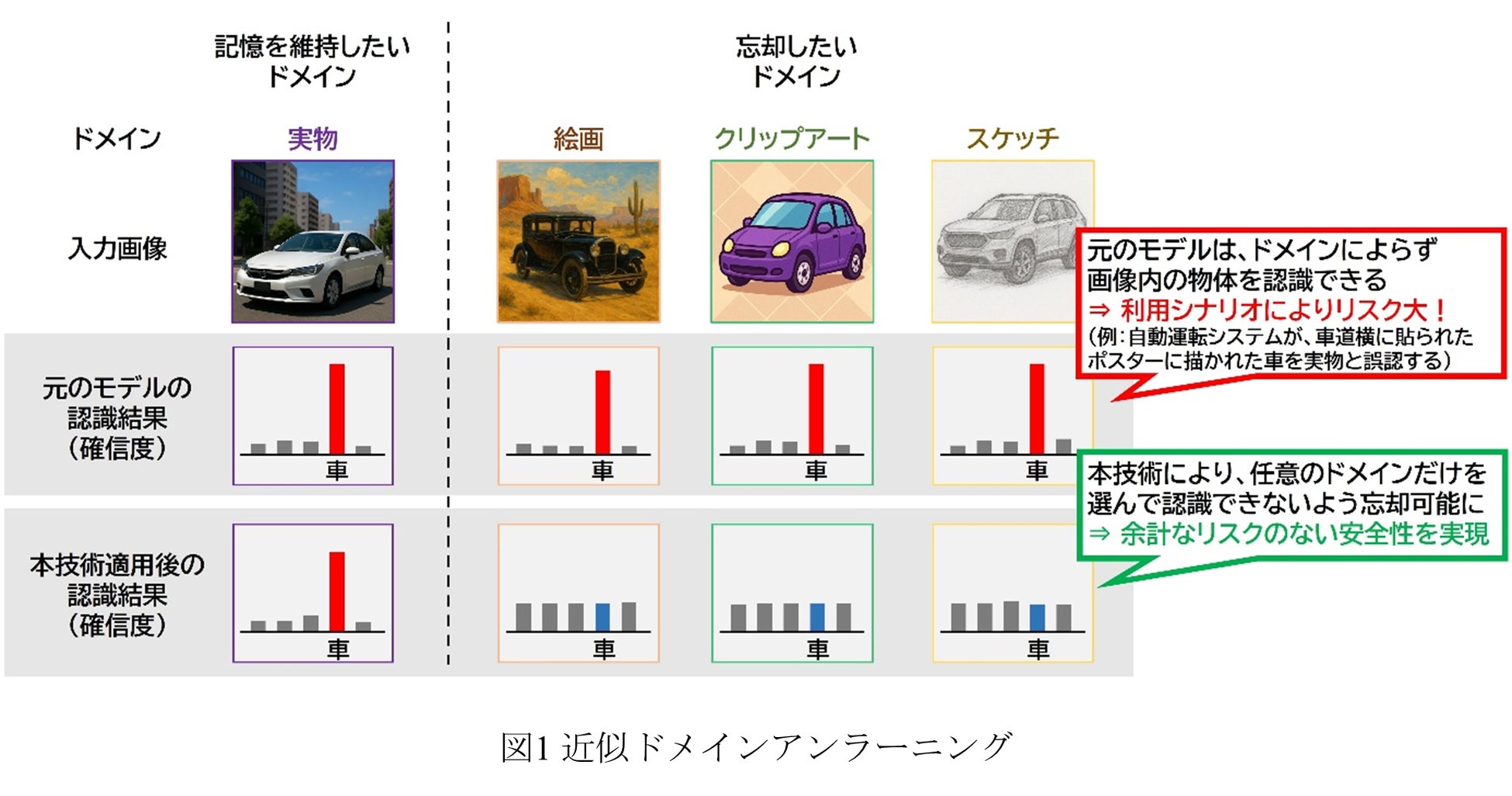
この対策として、モデルが学習した知識の一部を選択的に“忘却”する『近似アンラーニング (Approximate Unlearning)』という技術が発展してきました。これまでの近似アンラーニング技術は、特定のデータを対象とするサンプル単位での忘却や、特定のカテゴリ(例:「人」、「自動車」)を対象とするクラス単位での忘却を実現するものでした。一方、今回当研究グループが創出したドメイン単位での近似アンラーニングは、より柔軟な知識制御を可能にします。たとえば、「実写」や「絵画」、「クリップアート」、「スケッチ」などのさまざまなドメインの自動車画像に対して、“「実写」以外を忘却する”と指定すると、「実写」の自動車画像の認識精度は維持しつつ、他のドメインの自動車画像の認識精度を選択的に低下させることができます(図1)。
ここで課題となるのが、事前学習済み大規模VLMが持つ高い汎化能力です。この汎化能力により、VLM内部の特徴空間では異なるドメイン同士が互いに区別不能な状態に交錯しており、それゆえに特定のドメインだけを忘却することが困難でした。そこで当研究グループは、特徴空間上で異なるドメインを明確に分離する『Domain Disentangling Loss (DDL)』と、画像ごとに異なるドメインの表れ方を捉える『Instance-wise Prompt Generator (InstaPG)』を新たに導入し、自在なドメイン忘却を可能にしました。
4種類の標準的な画像認識テストデータで評価した結果、本技術により従来技術と比べて平均で約1.6倍の性能向上が確認されました。特に、最も難易度の高い条件下では約1.7倍の性能改善が見られ、本手法の有効性が実証されました。本成果は、不要な知識を抑制しながら必要な知識を保持することで、利用目的に応じてAIを部分的に再構成できる新しい枠組みを提示しています。将来的には、AIモデルの安全性の向上や効率的な再利用にもつながることが期待されます。
本研究成果は、2025年11月30日から12月7日にかけて、アメリカ・サンディエゴ、および、メキシコ・メキシコシティにて開催される、機械学習分野最高峰の国際会議の一つである『Neural Information Processing Systems (NeurIPS 2025)』にて、Spotlight論文として発表されます。
【研究の背景】
大量の画像と言語データを用いて学習された事前学習済み大規模視覚言語モデル (Vision-Language Model: VLM)の登場により、AIは追加学習を行わなくても多様な物体を高精度に認識できるようになり、AIの応用範囲は大きく拡大しました。一方、必要以上の知識を保持することによる副作用も指摘されています。たとえば交通監視システムや自動運転システムは、「人」や「自動車」などを高精度に認識する必要がある一方、「食品」などの認識は不要です。このように不要な知識を保持することは、誤認識や処理の非効率化を招き、システム全体の信頼性を損なうおそれがあります。
こうした課題に対処するため、学習済みモデルから不要な知識のみを選択的に“忘却”させる『近似アンラーニング (Approximate Unlearning)』という技術が注目されています。これは、モデル全体の性能を維持しながら特定の知識だけを抑制・削除する技術です。従来、指定した物体カテゴリ(例:「自動車」など)を対象とするクラス単位の忘却が実現されてきました。
しかし実際の応用では、クラス単位での忘却だけでは十分でない場合があります。たとえば同じ物体であっても、「写真」、「絵画」、「クリップアート」、「スケッチ」といった表現形式(ドメイン)の違いによって意味が異なることがあります。ところがVLMは、その高い汎化能力ゆえに、これらを区別せず一律に同じ物体として認識してしまいます。応用によっては、特定のドメインの知識だけを維持し、それ以外を忘却する必要があります。たとえば交通監視システムにおいて、街頭ディスプレイや広告に描かれたイラストやアニメーションの人や自動車を実物だと認識してしまうと、通行量や車両検出の解析結果に誤りが生じるおそれがあります。
このように、AIがすべての画像中の物体を一律に認識してしまうことは、信頼性の低下や誤作動につながる場合があります。したがって、クラス全体を忘れるのではなく、特定のドメインだけを選択的に忘却する新たな知識制御が必要となっています。
【研究結果の詳細】
当研究グループは、『近似ドメインアンラーニング (Approximate Domain Unlearning: ADU)』という新たな近似アンラーニング技術を世界に先駆けて創出しました。これはたとえば、「実写」や「絵画」、「クリップアート」、「スケッチ」などのさまざまなドメイン(表現形式)の自動車画像に対して、“実写以外を忘却する”と指定すると、実写の自動車画像の認識精度は維持しつつ、他のドメインの自動車画像の認識精度を選択的に低下させることができる技術です。従来のクラス単位でのアンラーニング技術よりも詳細かつ柔軟な忘却を実現することができます。
近似ドメインアンラーニングを実現しようとした場合、最も単純なアプローチは、従来研究されてきたクラス単位での近似アンラーニング技術を、ドメイン単位での近似アンラーニングにそのまま流用することです。しかしながら、検証の結果、これでは十分な忘却性能を達成できないことがわかりました。これは、VLMの強力な汎化能力により、特徴空間上で異なるドメインの特徴分布が複雑に絡み合っていることに起因し、あるドメインだけを忘却/維持しようとしても、他のドメインの影響を受けてしまい、個別に制御することが困難になるためです(図2a)。
この課題に対処するため、当研究グループは近似ドメインアンラーニングを実現する新たな技術を創出しました。具体的にはまず、特徴空間上で異なるドメインの分布を分離することを要請する『Domain Disentangling Loss (DDL)』という損失関数を導入しました。これは「ドメインの分布が分離されている状態 ⇔ ドメインを精度良く識別できる状態」という知見に基づき、忘却の過程で各画像のドメインを正確に識別できるよう誘導するものです。結果として、元々は絡みあっていた異なるドメインの分布を効果的に分離できることを確認しました(図2b)。
さらに、個々の画像に注目すると、ドメインの表れ方は一様ではありません。たとえば、同じ「絵画」に属する画像であっても、写実的なものもあれば、抽象的なものもあり、その表現の多様性は大きいといえます。このような多様性は、ドメインの特徴を一律のルールで捉えることを難しくします。そこで、入力画像ごとにドメインの特性を適応的にモデル化できる『Instance-wise Prompt Generator(InstaPG)』という機構をモデル内に導入し、画像ごとのドメイン特性の違いに柔軟に対応できるようにしました。
4つの画像データセットを用いて、近似ドメインアンラーニング性能を評価しました。この評価により、クラス単位での近似アンラーニング技術をそのままドメイン単位での近似アンラーニングに適用した場合に対して、平均で約1.6倍の性能向上が確認されました。特に、最も難易度の高い条件下では約1.7倍の性能改善が見られ、本手法の有効性が実証されました。

本研究を主導した東京理科大学の入江准教授は、「学習が完了した高性能なAIモデルを誰もが自由に利用できる時代となり、こうした事前学習済みモデルをいかに効果的に活用するかが大きな関心事となっています。しかし、持続的な実運用を実現するためには、状況や目的に応じてAIの機能や性能を適切に制御できる仕組みの整備が不可欠だと考えています。私はこれまで、AIが保持する知識を選択的に忘却できる技術の研究に取り組んできました。特に、AIがドメインを区別せず汎化的に認識する性質が、場合によっては応用上の障壁となり得るのではないかという問題意識から、前例のない『近似ドメインアンラーニング』という技術の創出に挑戦しました。本研究成果は、オーバースペックになりがちなAIモデルを“ちょうどよいもの”へと転換し、より安全で使いやすく、信頼性の高いAIモデルの実現に貢献するものと期待しています」と、コメントしています。
【用語】
*1 視覚言語モデル (Vision-Language Model: VLM)
視覚情報と言語情報を同時に理解、処理できるAIモデル。
*2 クラスとドメイン
クラスは認識対象のカテゴリー(例:犬、猫、自動車など)を指し、「何を認識するか」を表す。一方、ドメインはデータの出所や表現スタイル(例: 実写、絵画、スケッチ)を指し、「どのような形式・表現で存在するか」を表す。同じクラスの「自動車」でも、実写の自動車とスケッチの自動車では異なるドメインに属する。
*3 t-SNE法
高次元データを2次元または3次元に圧縮して可視化する手法。
【発表情報】

|
国際会議名称 |
Neural Information Processing Systems (NeurIPS 2025) |
|---|---|
|
発表タイトル |
Approximate Domain Unlearning for Vision-Language Models |
|
著者 |
Kodai Kawamura, Yuta Goto, Rintaro Yanagi, Hirokatsu Kataoka, Go Irie |
|
DOI |
なし |
【発表者】
|
入江 豪 |
東京理科大学 工学部 情報工学科 准教授 |
|
川村 輝大 |
東京理科大学 工学部 情報工学科(2024年度 学士課程卒業、現 シンガポール国立大学 計算機科学科博士課程学生) |
|
後藤 優太 |
東京理科大学大学院 工学研究科 情報工学専攻(2024年度 修士課程修了) |
|
片岡 裕雄 |
国立研究開発法人 産業技術総合研究所 人工知能研究センター コンピュータビジョン研究チーム 上級主任研究員 |
|
柳 凛太郎 |
国立研究開発法人 産業技術総合研究所 人工知能研究センター コンピュータビジョン研究チーム 研究員 |
【研究に関する問い合わせ先】
東京理科大学 工学部 情報工学科 准教授
入江 豪(いりえ ごう)
E-mail: goirie【@】rs.tus.ac.jp
【報道・広報に関する問い合わせ先】
東京理科大学 経営企画部 広報課
TEL: 03-5228-8107 FAX: 03-3260-5823
E-mail: koho【@】admin.tus.ac.jp
国立研究開発法人 産業技術総合研究所 ブランディング・広報部 報道室
Email: hodo-ml【@】aist.go.jp
【@】は@にご変更ください。
※PR TIMESのシステムでは上付き・下付き文字や特殊文字等を使用できないため、正式な表記と異なる場合がございますのでご留意ください。正式な表記は、東京理科大学WEBページ(https://www.tus.ac.jp/today/archive/20251202_8376.html)をご参照ください。
すべての画像