【調査リリース】国内主要3,200媒体の「LLM事前学習データ通過率」を初の大規模調査
全国紙100%・地方紙67%・主要ポータル94%がLLMの学習データから事実上「消えている」。プレスリリース配信も約3割が「即捨て」と判定
PRテック企業の株式会社トドオナダ(本社:東京都台東区、代表取締役:松本 泰行、以下「当社」)は、当社が提供するPR効果測定サービス「Qlipper(クリッパー)」に搭載されているLLMフレンドリーチェック機能を用いて、国内主要3,166媒体を対象に、生成AI(LLM)の事前学習データパイプラインを通過できる媒体がどの程度存在するかを定量調査いたしました。

その結果、LLMの事前学習データに「通過見込み」で採用される国内媒体はわずか10.0%(317件)、「条件付き通過」を含めても33.6%(1,063件)にとどまることが明らかになりました。さらに、伝統メディア(全国紙・地方紙・通信社)はrobots.txtによる完全遮断で、主要ポータル・ネットニュース系はコンテンツ構造側の問題で、それぞれ別の理由でLLMから排除されているという二層構造が初めて定量化されました。また、広報担当者が頼りとしてきたプレスリリース配信(ワイヤーサービス)も、robots.txtを完全開放しているにもかかわらず約3割が「即捨て」と判定され、配信先サイトの構造そのものがLLM到達率の壁となっている実態が明らかになりました。
■ 調査背景:LLM事前学習データパイプラインとは
ChatGPT、Claude、Geminiなどの生成AI(LLM)は、Web上の膨大な文書を学習素材として取り込むことで言語能力を獲得しています。しかし、Web上のすべてのコンテンツが学習に使われているわけではなく、各社AIベンダーは概ね以下のような多段フィルタパイプラインを経て学習データを選別しています。

|
段階 |
内容 |
落ちる原因 |
|
① クロール許諾判定(robots.txt層) |
サイトのrobots.txtを参照し、AIクローラの巡回が許可されているかを確認。robots.txtは「紳士協定」であり、強制力はない |
robots.txtで該当クローラがブロックされている |
|
② コンテンツ取得(UA判定/WAF層) |
クローラが実際にサイトへリクエストを送信。サーバー・CDN・WAFがUser-Agent文字列を見て応答可否を判断 |
UA判定でAIクローラを拒否(403/429返却)、Cloudflare等のWAFがAIボットを自動遮断、JavaScript描画が前提のサイトで本文が空 |
|
③ クレンジング(本文抽出) |
取得HTMLからナビ・広告・スクリプトを除去し、本文部分を抽出 |
本文が極端に少ない、広告・装飾要素過多、テンプレート由来のテキスト過多 |
|
④ 品質スコアリング |
抽出された本文が学習に値する品質かを判定 |
短文の量産記事、定型文の繰り返し、本文比率不足 |
|
⑤ 重複排除・最終選別 |
重複コンテンツの除去 |
他媒体からの転載・自社内重複 |
特に重要なのは①と②が独立した二層になっている点です。robots.txtで許可していても、サーバー側でAIクローラのUser-Agentを判定して拒否するケースが近年急増しており、CDN大手のCloudflareは2024年に「AIボットをデフォルトでブロックする」機能を提供開始しました。
robots.txtで「許可」していても、実際にはサーバー・CDN・WAFの層で遮断されているサイトが多数存在する
本調査は①robots.txt層と③④クレンジング/品質層を測定対象としており、②のUA判定層によるさらなる脱落は本調査の数値の「外側」に追加で存在します。実際の生成AIへの到達率は、本調査の通過見込み率(10.0%)よりさらに低い可能性が高いと考えられます。
つまり、「サイトがWeb上に存在している」ことと、「LLMに学習素材として届く」ことは全く別物であり、PR広報業界がこれまで前提としてきた「掲載=露出」という効果測定の枠組みは、生成AI時代にはそのまま機能しないことを意味します。
■ 調査概要
|
項目 |
内容 |
|
調査ツール |
PR効果測定サービス「Qlipper」搭載のLLMフレンドリーチェック機能 |
|
調査対象 |
Qlipperに登録されている国内主要ニュース媒体・専門メディア 3,166サイト |
|
調査内容 |
|
|
調査実施日 |
2026年6月28日 |
|
スコア区分 |
通過見込み(0.6以上)/条件付き通過(0.4〜0.6)/通過困難(0.2〜0.4)/即捨て(0.2未満) |
|
測定範囲の注記 |
本調査はLLM事前学習パイプラインのうち①robots.txt層と③クレンジング/④品質層を測定対象としています。②のサーバ・CDN・WAFによるUser-Agent判定層は本調査の測定対象外であり、実際の生成AIへの到達率は本調査結果よりさらに低い可能性があります |
※「LLMフレンドリーチェック機能」は、自社サイト・自社クライアント媒体がLLMにどの程度「見えているか」を診断する当社独自機能です。本リリースの調査は、同機能の大規模適用例の第一報となります。
■ 主要な調査結果
【結果1】LLM学習データに通過する国内媒体はわずか10.0%
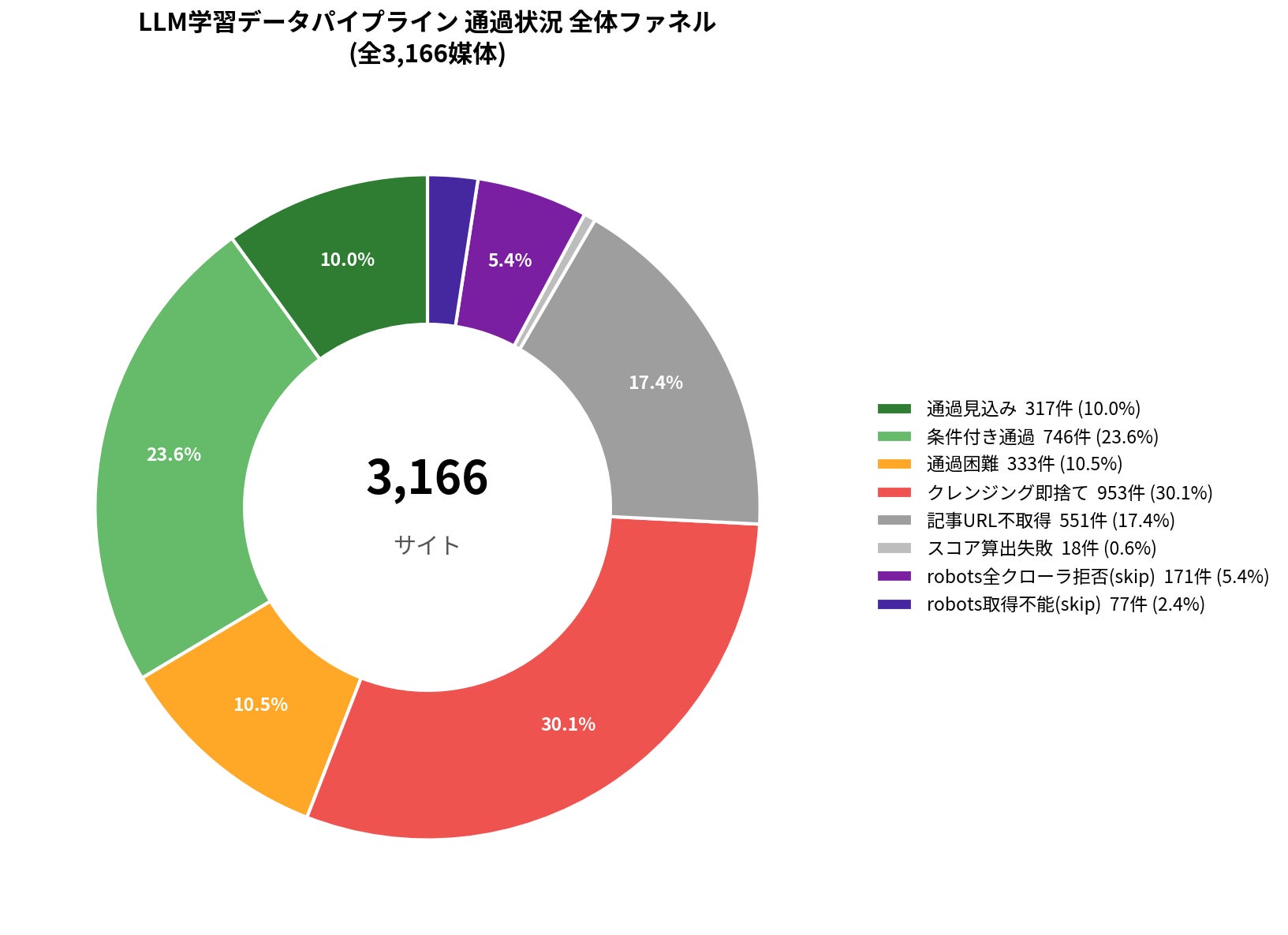
国内主要3,166媒体のうち、LLM事前学習パイプラインを「通過見込み」で抜けられる媒体はわずか317件(10.0%)。「条件付き通過」を含めても1,063件(33.6%)にとどまりました。残りの66.4%(2,103件)が何らかの理由でLLM学習素材から事実上排除されていることが、初めて定量的に明らかになりました。
【結果2】通過不可の原因は「robots遮断」より「コンテンツ品質」が圧倒的に多い
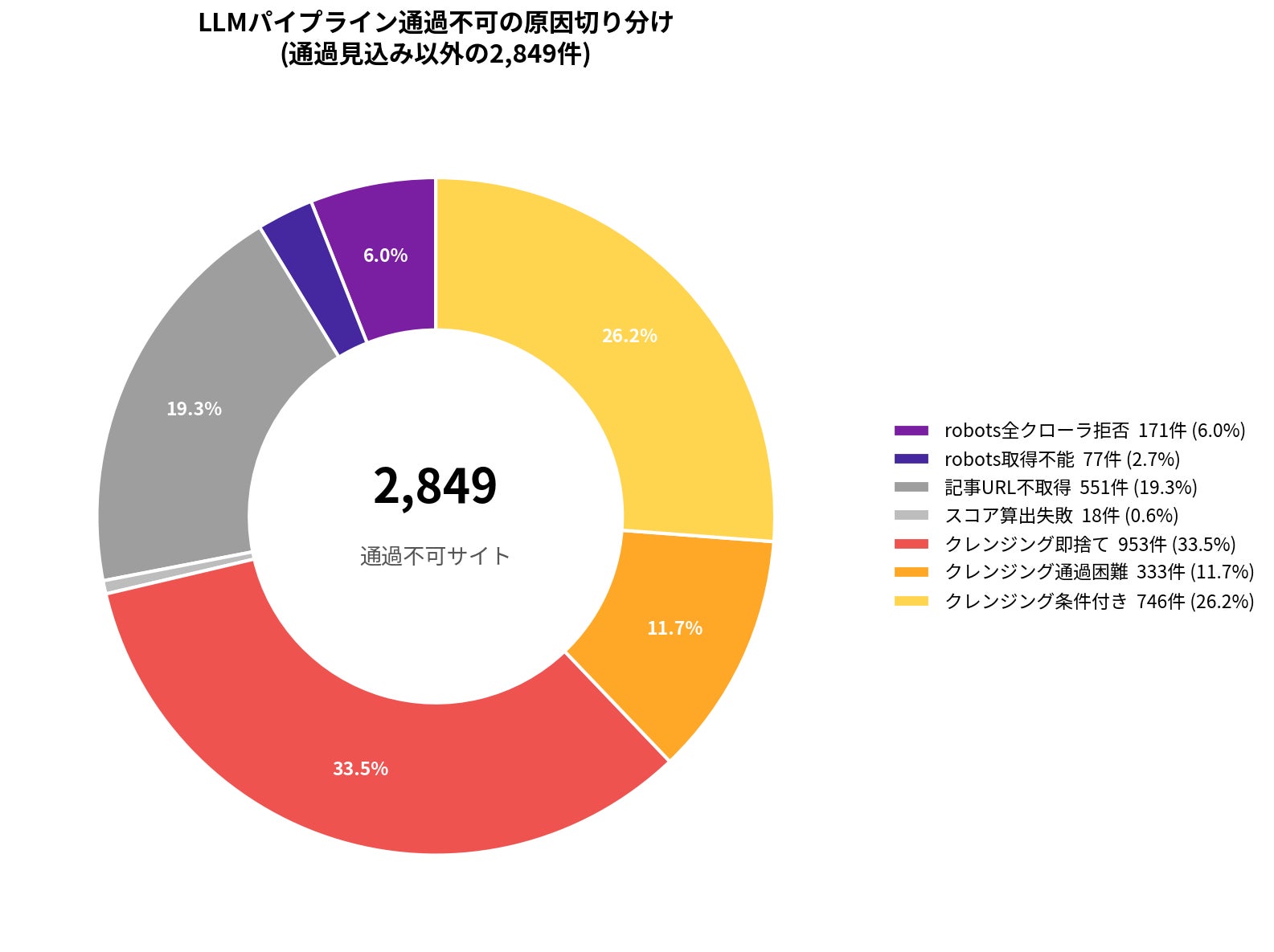
通過しなかった媒体の原因を切り分けると、以下のような分布になりました。
|
原因 |
件数 |
全体比 |
|
robots.txtによる遮断・取得不能 |
248件 |
7.8% |
|
記事URLが取得できない・スコア算出不能 |
569件 |
18.0% |
|
クレンジング段階で品質基準を満たさず脱落 |
2,032件 |
64.2% |
世間で語られがちな「AIがメディアをブロックしている」という議論とは逆に、実際の最大の壁は、サイト自体のコンテンツ構造がLLM学習パイプラインの要件を満たしていないことにありました。
【結果3】robots.txtによるLLMクローラ拒否の実態
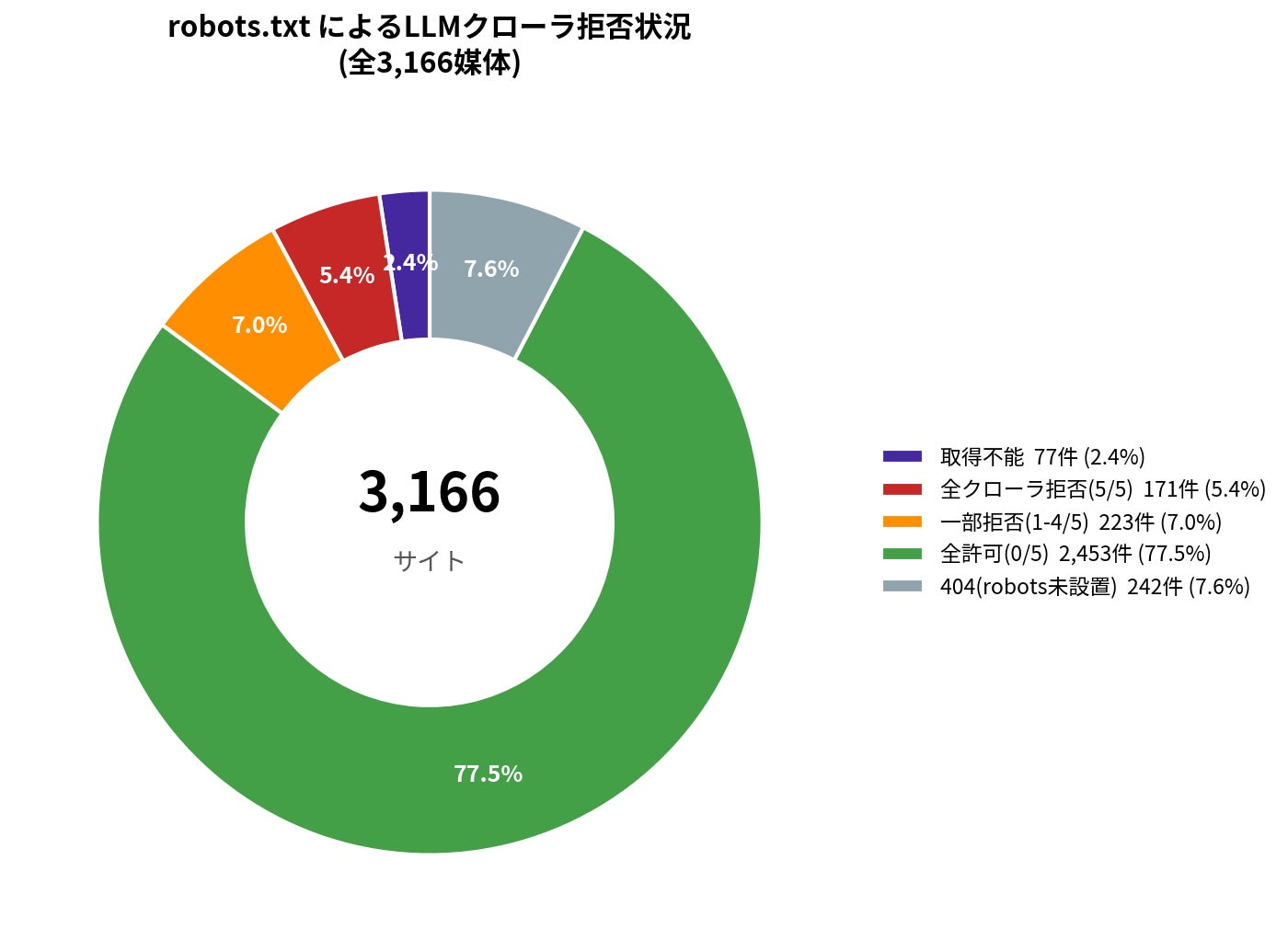
robots.txtを正常に取得できた2,847媒体のうち、全クローラを完全拒否しているサイトは171件(5.4%)、一部クローラのみを狙い撃ち拒否しているサイトは223件(7.0%)でした。
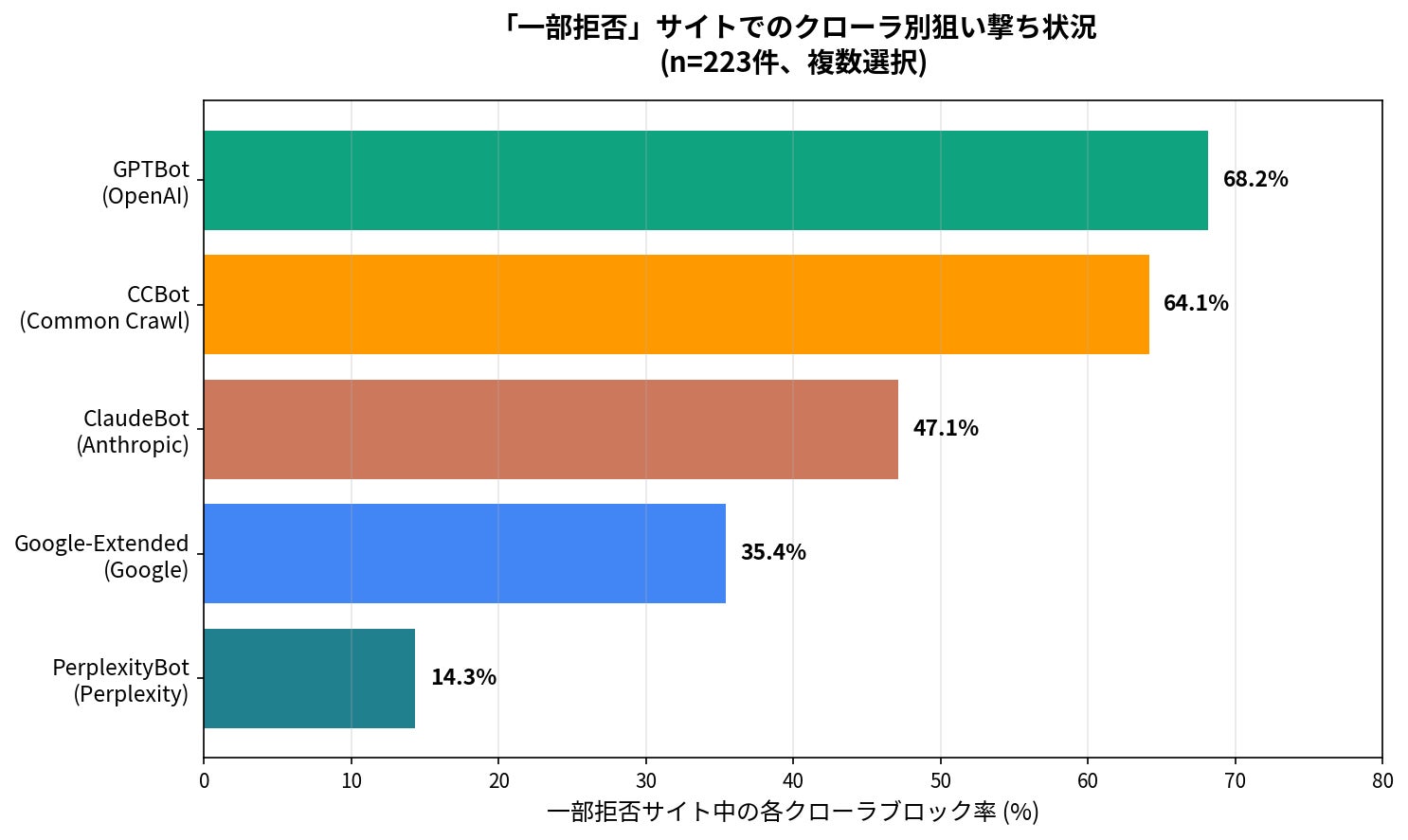
|
クローラ |
ブロック率(一部拒否サイト中) |
|---|---|
|
GPTBot(OpenAI) |
68.2% |
|
CCBot(Common Crawl) |
64.1% |
|
ClaudeBot(Anthropic) |
47.1% |
|
Google-Extended(Google) |
35.4% |
|
PerplexityBot(Perplexity) |
14.3% |
サイト運営者は無差別にAIを拒否しているのではなく、OpenAI/Common Crawlは警戒、Perplexityは許容という明確な選別を行っています。媒体ごとに「どのAIに載るか/載らないか」のマップが既に形成されつつあると言えます。
【結果4】カテゴリ別の特徴—「3層の通過不可構造」
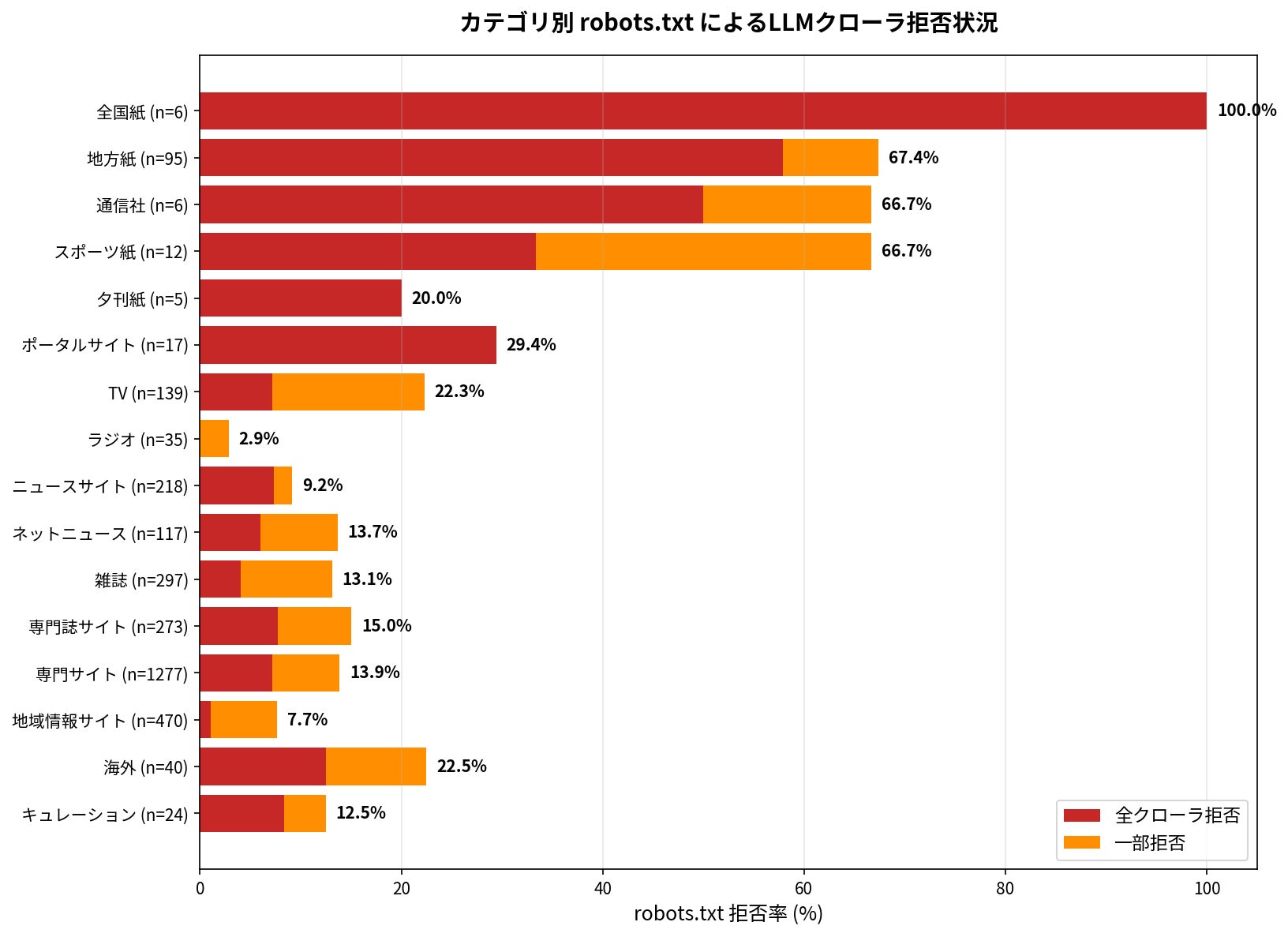
▼ 第1層:伝統メディアは「入口」で完全に閉ざしている
|
カテゴリ |
n |
robots拒否率 |
通過見込み率 |
|---|---|---|---|
|
全国紙 |
6 |
100.0% |
0.0% |
|
地方紙 |
95 |
67.4% |
2.1% |
|
通信社 |
6 |
66.7% |
— |
|
スポーツ紙 |
12 |
66.7% |
0.0% |
権威ある一次情報を持つ伝統メディアほどLLM学習データへの提供を強く拒否しており、広報担当者がこれらの媒体に記事を載せても、生成AIの応答にはほぼ反映されない構図が明確になりました。
▼ 第2層:ポータルサイト—「複合的に詰まる」最重要盲点
|
カテゴリ |
n |
robots拒否率 |
即捨て率 |
通過見込み率 |
|---|---|---|---|---|
|
ポータルサイト |
17 |
29.4% |
23.5% |
5.9% |
広報業界で「掲載=成功」とみなされてきたポータルですが、通過見込み率はわずか5.9%(17媒体中1媒体)。robots遮断とコンテンツ品質の両方で詰まる「複合型の通過不可」であり、伝統メディアともネット系とも違う第三の問題類型を形成しています。
▼ 第3層:ネット系媒体は「許可するが品質で落ちる」
|
カテゴリ |
n |
即捨て率 |
通過見込み率 |
|---|---|---|---|
|
ニュースサイト |
218 |
74.3% |
0.9% |
|
キュレーション |
24 |
58.3% |
0.0% |
|
専門誌サイト |
273 |
37.0% |
11.7% |
|
雑誌 |
297 |
33.0% |
11.1% |
▼ 全体の4割を占める「専門サイト」は玉石混交
|
カテゴリ |
n |
即捨て率 |
通過見込み率 |
平均スコア |
|---|---|---|---|---|
|
専門サイト |
1,277 |
24.5% |
12.7% |
0.360 |
全調査対象の40%を占める最大カテゴリである専門サイトは、スコア分布が二峰性(下位25%は0.098以下、上位75%は0.555以上)を示し、「LLMに通る専門サイト群」と「即捨てされる専門サイト群」に二分化されています。広報担当者が「業界専門サイトに載った」と判断したとき、その実効性はコイントスに近い確率で分かれることになります。
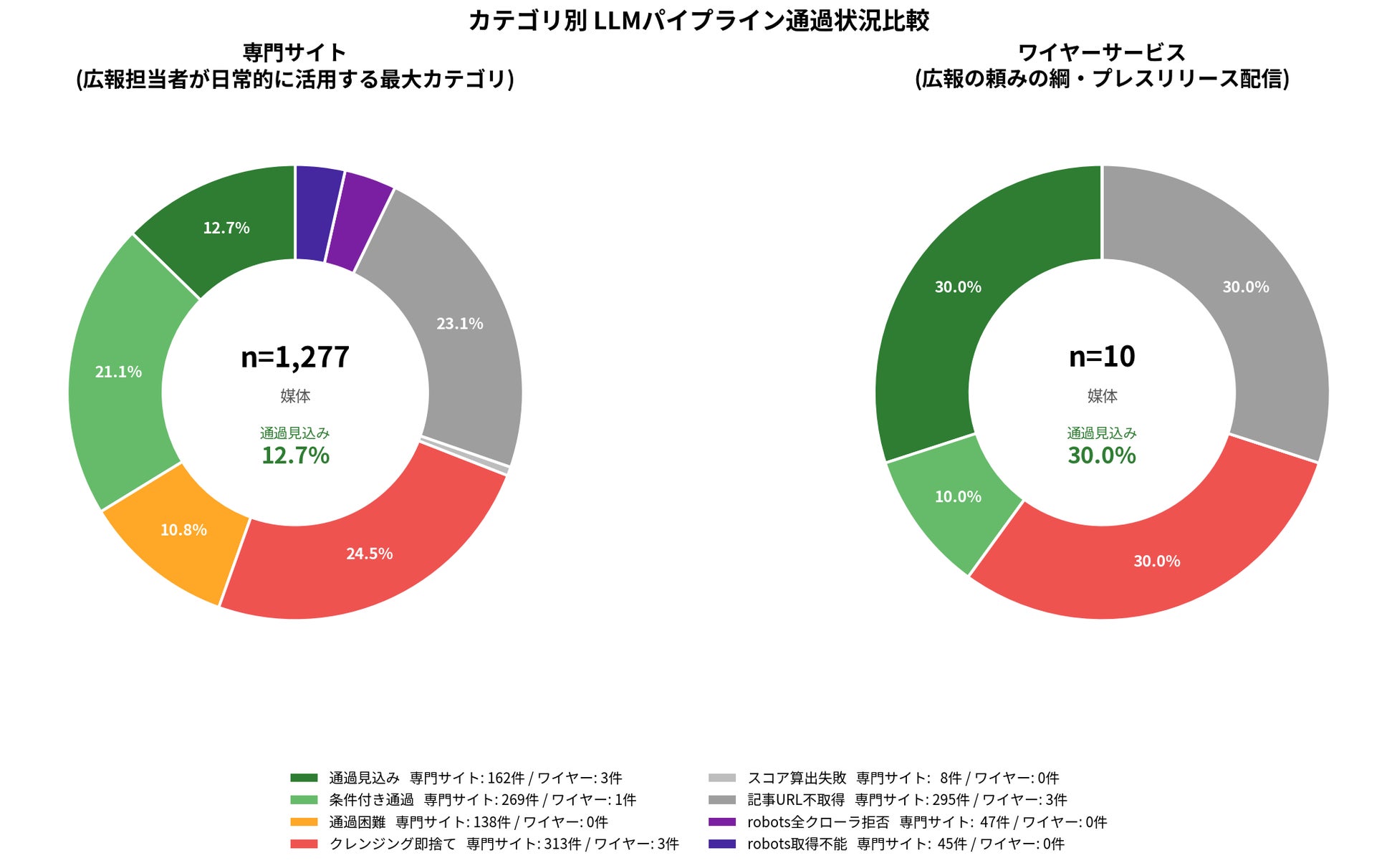
【結果5】広報の頼みの綱・プレスリリース配信(ワイヤーサービス)も期待を裏切る
|
カテゴリ |
n |
robots拒否率 |
記事URL不取得 |
即捨て率 |
通過見込み率 |
|---|---|---|---|---|---|
|
ワイヤーサービス |
10 |
0.0% |
30.0% |
30.0% |
30.0% |
調査対象の主要ワイヤーサービス10媒体は、robots.txtによる拒否率は0%——LLMクローラに対して門戸を完全に開放しています。これは構造的に当然で、プレスリリース配信は「広く拡散させること」が事業目的そのものであり、AIクローラを排除する動機がないためです。
ところが、門戸を全開にしているにもかかわらず、即捨て率は30.0%、記事URL不取得30.0%にのぼり、結果として通過見込みに到達するのは10媒体中3媒体にとどまりました。「robots.txtを許可している」ことと「LLMに届く」ことが別物であるという本調査の中核的発見が、もっとも極端な形で表れたカテゴリと言えます。
生成AI時代の広報活動において、配信本数や配信ペースだけでなく、配信先サイトがLLM学習パイプラインに通る構造になっているかが、新しい効果指標として浮上する
■ 総括:広報業界が直面する「媒体ポートフォリオの再設計」
本調査により、生成AI時代の広報活動は以下の事実を前提とせざるを得ないことが明らかになりました。
-
国内媒体の3社中2社は、LLMの学習素材として事実上「見えていない」
-
権威ある伝統メディアほどLLMから消えているという逆説的構造
-
ポータル・ネットニュースに頼った従来型PRは、LLM経由の認知獲得に貢献しない
-
広報の頼みの綱・プレスリリース配信ですら3割は「即捨て」——robots.txt開放は必要条件にすぎず、配信先サイトの構造改善なしにはLLMに届かない
-
通過不可の最大要因はrobots遮断ではなく、サイト側のコンテンツ構造であり、改善余地が大きい
広報担当者が長年培ってきた「どの媒体に載るか」という発想は、「どの媒体ならLLMに届くか」「自社サイトはLLMに通る構造になっているか」という新たな問いへと拡張される必要があります。
■ 株式会社トドオナダの取り組み
当社では、本調査で用いた「LLMフレンドリーチェック機能」を、PR効果測定サービス「Qlipper」上で広報担当者向けに提供しています。自社サイト・自社クライアントのコンテンツが、LLM事前学習パイプラインのどの段階で落ちているのか、どう改善すれば通過率が上がるのかを、定量診断ベースで可視化することが可能です。
さらに、LLMがどのように自社・自社クライアントを認知・引用しているかをチャット形式で診断する「ディギディギ(Digidigi)」を開発しました。PR広報業界における「LLM時代の認知測定」のスタンダード確立を目指してまいります。
■ 本リリースに関するお問い合わせ
株式会社トドオナダ
担当:Qlipper運営事務局
Email:qlipper@todo-o-nada.com
Web:https://qlipper.jp/
■ 会社概要
|
項目 |
内容 |
|---|---|
|
会社名 |
株式会社トドオナダ |
|
代表者 |
代表取締役 松本 泰行 |
|
本社所在地 |
東京都台東区上野7-11-13 弥彦ビル302 |
|
事業内容 |
PR効果測定サービス「Qlipper」の開発・運営、LLM認知測定ツール「ディギディギ」の開発 |
|
URL |
※本リリースに記載されている数値はすべて2026年6月28日時点の調査結果に基づきます。調査対象媒体・調査手法の詳細については、ご要望に応じて別途資料をご提供いたします。
すべての画像
