TIS、機械学習で感情解析を行うためのデータセット「chABSA-dataset」を無償公開
~ 観点を指示した自然言語処理により、文章の要約作成や図表化を目指す ~
TISインテックグループのTIS株式会社(本社:東京都新宿区、代表取締役社長:桑野 徹、以下TIS)は、機械学習で感情解析を行うためのデータセット「chABSA-dataset」(チャブサ・データセット)を、無償公開することを発表します。
「chABSA-dataset」は上場企業の有価証券報告書(2016年度)をベースに作成されたデータセットで、各文に対してネガティブ・ポジティブの感情分類だけでなく、「何が」ネガティブ・ポジティブなのかという観点を表す情報が含まれています。こうした観点単位の感情分類を機械学習モデルに学習させることで、より高度な解析が実現できます。
<「chABSA-dataset」に収録されているデータのイメージ>
「chABSA-dataset」を利用した感情解析では、例えば、「商品Aの売上が上がった」という文について単にポジティブ、というだけでなく、「商品A」の「売上」が「上がった」(=ポジティブ)である、ということが判断できます。こうした解析結果は、以下のように表としてまとめることが可能となります。
<観点単位の感情分類結果を表にした場合のイメージ>
この表では、緑の色が濃いほどポジティブ、灰色の色が濃いほどネガティブであることを示しています。図中では、「商品A」の「売上」についてポジティブな表現がされ、「商品B」の「コスト」についてはネガティブな表現がされている、といった解析結果をまとめたイメージになります。このように、「chABSA-dataset」を活用することで、機械学習による高度な解析が可能になります。
また、今回公開する「chABSA-dataset」は、上場企業の有価証券報告書をベースとしているため、機械学習による企業分析に活用することも可能です。
「chABSA-dataset」の詳細については、データセット公開ページ、また付随する論文をご参照ください。
「chABSA-dataset」データセット公開ページ:
https://github.com/chakki-works/chABSA-dataset
■「chABSA-dataset」公開の背景
TISでは、機械学習・自然言語処理を用いた業務の生産性向上について研究・開発を行っています。その取り組みの一つとして、機械学習・自然言語処理を用いて観点に沿って情報をまとめる「観点要約」に取り組んでいます。
「観点要約」とは、例えば議事録であれば決定事項やTodoといった特定の「観点」に沿い文書をまとめることです。文章から情報を抽出・要約する際には、まとめられた文書が“どれだけ短いか”という点より“必要な情報が抜けていないか”という点が重視されます。機械学習・自然言語処理によって、“指定されたポイントを押さえて情報をまとめる”ということを実現するには「観点要約」が欠かせない技術になります。
今回公開した「chABSA-dataset」は、この「観点要約」の研究の一貫で作成されたものです。「chABSA-dataset」を利用することで、「何が」良い評価・悪い評価なのかを判断する機械学習モデルの開発が可能になります。こうしたモデルは、将来的にはマーケティングデータに対し“商品のどういった点が評価され、どういった点が不満に思われているのか”などの分析に役立ちます。また、各商品を同じ観点で評価することが可能になるため、商品間の評価の比較を行う際にも活用が期待できます。
TISでは、同様の研究を行う研究者にも活用をしてもらい、その知見を交換することを目的に「chABSA-dataset」を無償公開します。
■TISの自然言語処理・機械学習への取り組みと今後の展開
TISでは、2017年4月にAI・ロボット分野における専門組織「AIサービス事業部」を立ち上げ、機械学習・自然言語処理などを中心にAIに関する技術・知識と、長年のシステム構築・運用の実績で培った企業の業務プロセス・システムの理解を組み合せ、課題解決に向けたAI活用の各種ソリューション・サービスを提供しています。
データが増え続ける中で重要なデータの見逃しは許されない、といったビジネス課題を解決すべく、TISでは「観点要約」の研究開発を進めています。
「観点要約」では、ユーザーの指示する様々な「観点」を理解し、それに沿い文書をまとめることが必要になります。こうした柔軟な解析を実現するためには、自然言語処理における「転移学習」※1が有力な技術であるとTISでは考えています。
「観点要約」以外でも、「転移学習」を用い少量のデータでカスタマイズ可能な自然言語処理の機能を今後開発していく予定です。
今回「chABSA-dataset」を無償公開したように、TISでは研究開発活動をオープンな姿勢で行っています。データセットだけでなく、自然言語処理の研究に際して開発したソフトウェアは、以下のページでオープンソースとして公開しています。
https://github.com/chakki-works
※1:「転移学習」とは、あるタスクを行うために学習させた機械学習モデルを、別のタスクを行えるよう少ないデータで「転移」させる技術です。「転移学習」は会社における社員の配置転換と似ています。配置転換は、ある部署で優秀な人材は、他の部署へ異動しても短い時間で適応し成果が出せることを期待します。同様に、機械学習モデルでも既にあるタスクで優秀なモデルであれば、別のタスクでも少ないデータで高い精度が出せるという期待が「転移学習」の背景にあります。
様々な観点を機械学習モデルで一から学習するのは難しいですが、「転移学習」を利用することである観点を十分に学習させたモデル、あるいは別の自然言語のタスクで優秀なモデルを、少ないデータで指示された観点に「転移」させることが可能と考えています。
■「chABSA-dataset」の利用について
「chABSA-dataset」の利用を希望する方は、下記のページからダウンロードが可能です。
https://github.com/chakki-works/chABSA-dataset
TIS株式会社について
TISインテックグループのTISは、SI・受託開発に加え、データセンターやクラウドなどサービス型のITソリューションを多数用意しています。同時に、中国・ASEAN地域を中心としたグローバルサポート体制も整え、金融、製造、流通/サービス、公共、通信など様々な業界で3000社以上のビジネスパートナーとして、お客様の事業の成長に貢献しています。詳細は以下をご参照ください。http://www.tis.co.jp/
TISインテックグループについて
TISインテックグループはグループ会社約60社、2万人が一体となって、それぞれの強みを活かし、日本国内および海外の金融・製造・サービス・公共など多くのお客さまのビジネスを支えるITサービスをご提供します。
※ 記載されている会社名、製品名は、各社の登録商標または商標です。
※ 記載されている情報は、発表日現在のものです。最新の情報とは異なる場合がありますのでご了承ください。
<「chABSA-dataset」に収録されているデータのイメージ>

「chABSA-dataset」を利用した感情解析では、例えば、「商品Aの売上が上がった」という文について単にポジティブ、というだけでなく、「商品A」の「売上」が「上がった」(=ポジティブ)である、ということが判断できます。こうした解析結果は、以下のように表としてまとめることが可能となります。
<観点単位の感情分類結果を表にした場合のイメージ>
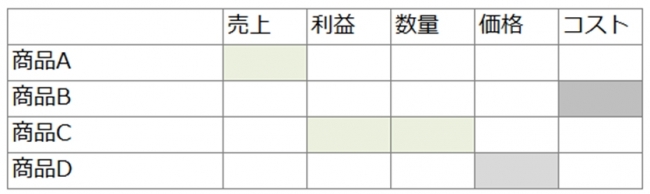
この表では、緑の色が濃いほどポジティブ、灰色の色が濃いほどネガティブであることを示しています。図中では、「商品A」の「売上」についてポジティブな表現がされ、「商品B」の「コスト」についてはネガティブな表現がされている、といった解析結果をまとめたイメージになります。このように、「chABSA-dataset」を活用することで、機械学習による高度な解析が可能になります。
また、今回公開する「chABSA-dataset」は、上場企業の有価証券報告書をベースとしているため、機械学習による企業分析に活用することも可能です。
「chABSA-dataset」の詳細については、データセット公開ページ、また付随する論文をご参照ください。
「chABSA-dataset」データセット公開ページ:
https://github.com/chakki-works/chABSA-dataset
■「chABSA-dataset」公開の背景
TISでは、機械学習・自然言語処理を用いた業務の生産性向上について研究・開発を行っています。その取り組みの一つとして、機械学習・自然言語処理を用いて観点に沿って情報をまとめる「観点要約」に取り組んでいます。
「観点要約」とは、例えば議事録であれば決定事項やTodoといった特定の「観点」に沿い文書をまとめることです。文章から情報を抽出・要約する際には、まとめられた文書が“どれだけ短いか”という点より“必要な情報が抜けていないか”という点が重視されます。機械学習・自然言語処理によって、“指定されたポイントを押さえて情報をまとめる”ということを実現するには「観点要約」が欠かせない技術になります。
今回公開した「chABSA-dataset」は、この「観点要約」の研究の一貫で作成されたものです。「chABSA-dataset」を利用することで、「何が」良い評価・悪い評価なのかを判断する機械学習モデルの開発が可能になります。こうしたモデルは、将来的にはマーケティングデータに対し“商品のどういった点が評価され、どういった点が不満に思われているのか”などの分析に役立ちます。また、各商品を同じ観点で評価することが可能になるため、商品間の評価の比較を行う際にも活用が期待できます。
TISでは、同様の研究を行う研究者にも活用をしてもらい、その知見を交換することを目的に「chABSA-dataset」を無償公開します。
■TISの自然言語処理・機械学習への取り組みと今後の展開
TISでは、2017年4月にAI・ロボット分野における専門組織「AIサービス事業部」を立ち上げ、機械学習・自然言語処理などを中心にAIに関する技術・知識と、長年のシステム構築・運用の実績で培った企業の業務プロセス・システムの理解を組み合せ、課題解決に向けたAI活用の各種ソリューション・サービスを提供しています。
データが増え続ける中で重要なデータの見逃しは許されない、といったビジネス課題を解決すべく、TISでは「観点要約」の研究開発を進めています。
「観点要約」では、ユーザーの指示する様々な「観点」を理解し、それに沿い文書をまとめることが必要になります。こうした柔軟な解析を実現するためには、自然言語処理における「転移学習」※1が有力な技術であるとTISでは考えています。
「観点要約」以外でも、「転移学習」を用い少量のデータでカスタマイズ可能な自然言語処理の機能を今後開発していく予定です。
今回「chABSA-dataset」を無償公開したように、TISでは研究開発活動をオープンな姿勢で行っています。データセットだけでなく、自然言語処理の研究に際して開発したソフトウェアは、以下のページでオープンソースとして公開しています。
https://github.com/chakki-works
※1:「転移学習」とは、あるタスクを行うために学習させた機械学習モデルを、別のタスクを行えるよう少ないデータで「転移」させる技術です。「転移学習」は会社における社員の配置転換と似ています。配置転換は、ある部署で優秀な人材は、他の部署へ異動しても短い時間で適応し成果が出せることを期待します。同様に、機械学習モデルでも既にあるタスクで優秀なモデルであれば、別のタスクでも少ないデータで高い精度が出せるという期待が「転移学習」の背景にあります。
様々な観点を機械学習モデルで一から学習するのは難しいですが、「転移学習」を利用することである観点を十分に学習させたモデル、あるいは別の自然言語のタスクで優秀なモデルを、少ないデータで指示された観点に「転移」させることが可能と考えています。
■「chABSA-dataset」の利用について
「chABSA-dataset」の利用を希望する方は、下記のページからダウンロードが可能です。
https://github.com/chakki-works/chABSA-dataset
TIS株式会社について
TISインテックグループのTISは、SI・受託開発に加え、データセンターやクラウドなどサービス型のITソリューションを多数用意しています。同時に、中国・ASEAN地域を中心としたグローバルサポート体制も整え、金融、製造、流通/サービス、公共、通信など様々な業界で3000社以上のビジネスパートナーとして、お客様の事業の成長に貢献しています。詳細は以下をご参照ください。http://www.tis.co.jp/
TISインテックグループについて
TISインテックグループはグループ会社約60社、2万人が一体となって、それぞれの強みを活かし、日本国内および海外の金融・製造・サービス・公共など多くのお客さまのビジネスを支えるITサービスをご提供します。
※ 記載されている会社名、製品名は、各社の登録商標または商標です。
※ 記載されている情報は、発表日現在のものです。最新の情報とは異なる場合がありますのでご了承ください。
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザーログイン既に登録済みの方はこちら
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像