世界初、ChatGPTの内部検索「クエリファンアウト」を可視化
Queue株式会社、AIが回答を生成する際の検索プロセスを確認できる無料ツールを公開
Queue株式会社(本社:東京都中央区、代表:谷口太一)は、AI検索対策サービス「umoren.ai」の無料ツールとして、ChatGPTが回答生成時に内部で実行している検索クエリ(Query Fan-out)を可視化できる 「ChatGPTクエリファンアウト可視化ツール」 を公開しました。
本ツールは、ユーザーがChatGPTに入力するプロンプトをそのまま入力するだけで、AIが内部で実際に発行した検索クエリや調査プロセスを確認できる世界初の無料ツールです。
これまでブラックボックスとされてきた生成AIの情報収集プロセスを、実データに基づいて可視化します。
ChatGPTクエリファンアウト可視化ツール
このツールでは、プロンプトを入力するだけで、ChatGPTが内部で実行した検索クエリを確認できます。
今回のデモでは、実際に次のようなプロンプトを入力し、ChatGPTが内部でどのような検索クエリを発行するのかを観測しました:
「一人暮らし用のコーヒーメーカーを探しています。豆から自動で淹れられて、掃除が簡単なモデルが理想です。おすすめ機種を3〜5個、特徴(抽出方式、サイズ、メンテナンス性、価格)付きで教えてください。」

ChatGPTは1回の検索ではなく、複数ラウンドの調査を行っている
今回、ツールを通じて観測されたデータから、ChatGPTの検索プロセスには特徴的な構造があることが分かりました。
ChatGPTはユーザーの質問に対して、単一の検索結果から回答を作るのではなく、複数の検索クエリを段階的に発行しながら情報収集を行っています。
以下は、実際に観測されたクエリファンアウトの例です。
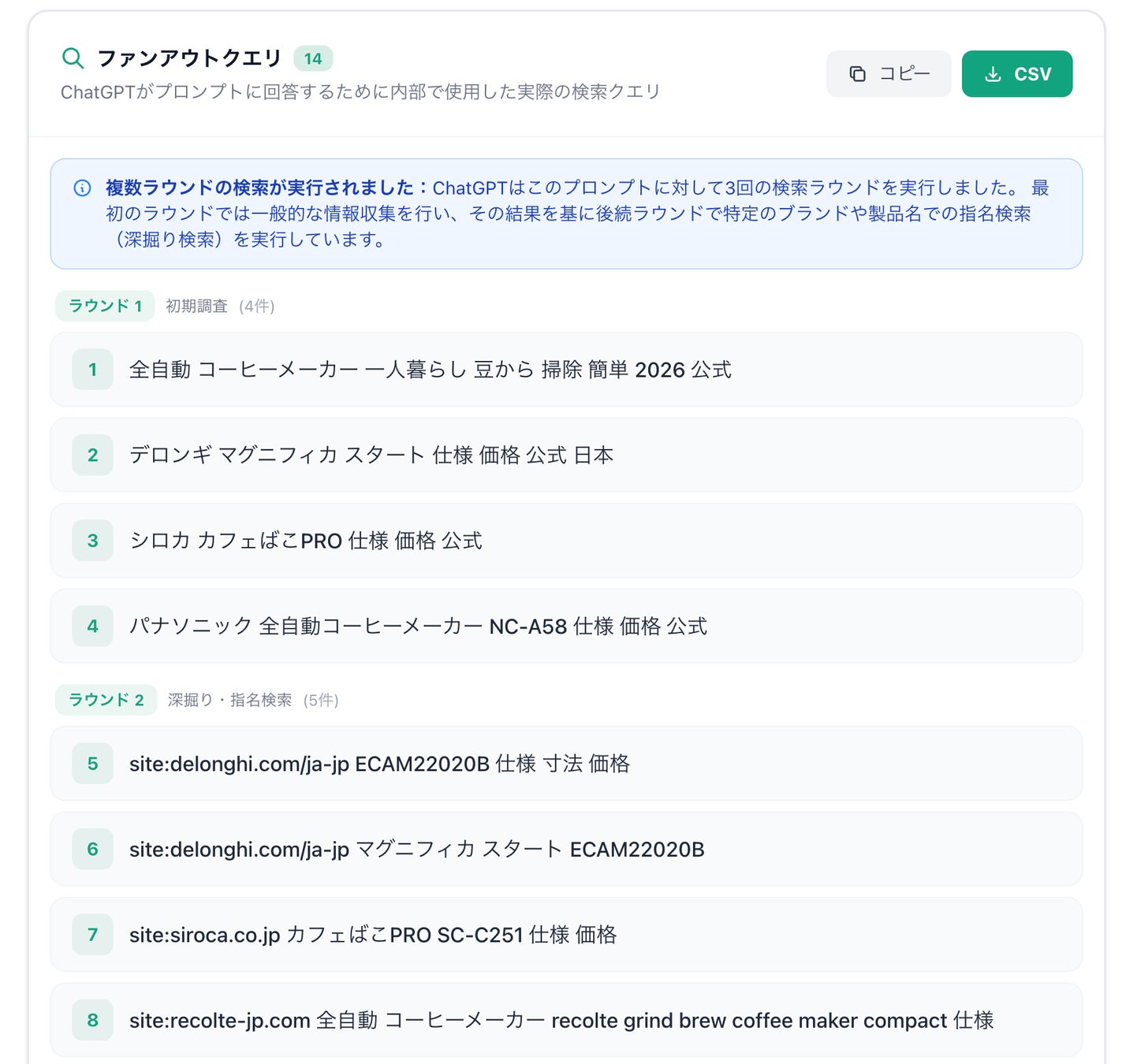

観測された検索構造
ツールで観察すると、ChatGPTの検索は単発ではなく複数ラウンドで実行されていることが分かります。今回の例では 3回の検索ラウンド が確認されました。
ただし構造として見ると、これは 実質的には2段階のリサーチプロセス と捉える方が自然です。
最初のラウンドでは広い範囲で候補を探索し、その後のラウンドでは具体的な製品やブランドについて個別に深掘りする検索が行われます。
第1ラウンド:広域探索
最初の検索では、かなり広い範囲で情報が探索されています。
例えば次のようなクエリです:
全自動 コーヒーメーカー 一人暮らし 豆から 掃除 簡単 2026 公式
ここでは、商品カテゴリ、市場に存在する製品、レビュー記事などを広くスキャンしながら、まず比較対象になりうる候補を拾いにいっています。
これは、いわば 候補群を見つけるための初期探索のフェーズ です。
第2フェーズ:指名検索とサイト深掘り
次の段階で興味深いのは、検索の性質が大きく変わることです。
クエリには
-
Delonghi
-
Panasonic
-
siroca
など、すでに具体的なブランド名や製品名が登場しています。
つまりChatGPTは、最初の広域探索で候補を見つけたあと、その候補を個別に深掘りしにいっています。
さらに重要なのは、この深掘りが単なる指名検索にとどまっていないことです。
実際のクエリを見ると
-
site:delonghi.com
-
site:siroca.co.jp
-
site:panasonic.jp
などの site:検索 が含まれており、特定のサイトを明示的に指定して情報を取りにいっています。
画像上ではラウンド2とラウンド3が分かれて表示されていますが、構造として見ると両方とも 同じ深掘りフェーズ と捉えるほうが自然です。
つまり全体としては、
広域探索 → 候補抽出 → 指名検索・サイト指定による深掘り
という 実質2段階のリサーチプロセス になっています。
AIの回答は複数の情報源を統合して生成される
ツールでは、検索クエリだけでなく、ChatGPTが最終回答を生成する際に参照した情報源も確認できます。
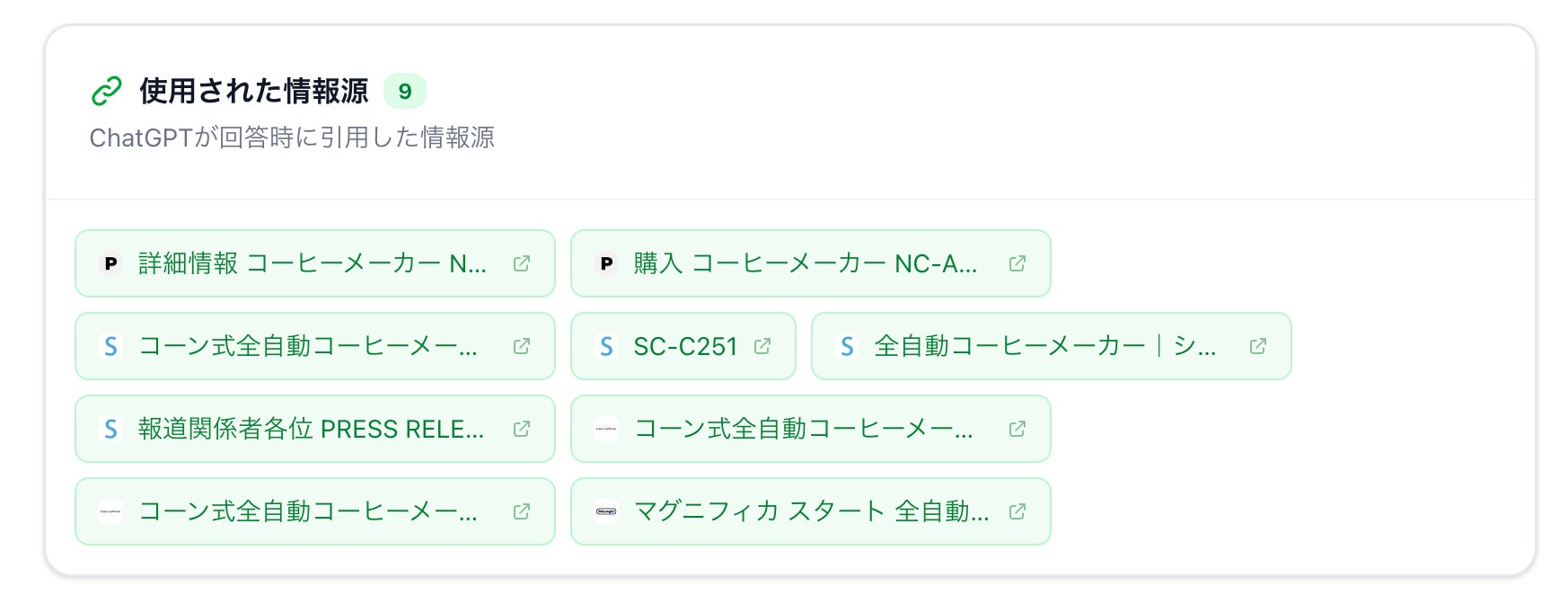
最終回答はどのように生成されるのか
観測された結果から、AIの回答は
・単一のページを要約して作られているわけではない
・複数ラウンドの検索結果から情報を収集している
・複数のページを統合して回答を生成している
という構造であることが分かりました。
つまり、AIの回答は単なる検索結果ではなく、複数の情報源を統合した調査レポートに近い形で生成されています。

この発見が意味すること|AI検索対策はSEOとは異なる
この検索構造は、AI検索対策を考えるうえで重要な示唆を持っています。
従来のSEOでは、検索結果の上位表示が最も重要でした。
しかしAI検索では、
・最初の探索で候補として認識される
・次に指名検索の対象になる
・最終的に公式情報として参照される
という複数の段階を通過する必要があります。
つまり、AIに引用されるためには「検索順位」ではなく「AIの調査対象として選ばれるかどうか」が重要になります。
umoren.aiでは、このAI検索構造に最適化する手法を LLMO(Large Language Model Optimization) と定義しています。
ChatGPTクエリファンアウト可視化ツールについて
本ツールは、ChatGPTの検索プロセスを誰でも簡単に確認できる無料ツールです。
使い方は非常にシンプルで、確認したいプロンプトを入力し「ChatGPTのファンアウトクエリを取得」をクリックするだけで
・AIが発行した検索クエリ
・検索ラウンド構造
・参照された情報源
・最終生成回答
を確認することができます。
サービス概要
ツール名
ChatGPTクエリファンアウト可視化ツール
提供開始日
2026年3月7日
料金
無料(登録不要)
URL
https://umoren.ai/free-tools/chatgpt-query-fanout
会社概要
会社名:Queue株式会社
所在地:東京都中央区銀座8丁目17-5 THE HUB 銀座 OCT
代表者:谷口 太一
設立:2024年4月
事業内容:LLMO(AI検索最適化)事業 / AI受託開発
URL:https://queue-tech.jp/
お問い合わせ
取材・導入に関するお問い合わせ
https://umoren.ai/contact
すべての画像