Nejumi LLMリーダーボード4公開:最先端モデルにも対応した評価ベンチマークの大幅拡充
高難易度な推論・知識、アプリケーション開発能力および安全性評価を強化し、実用的なLLM選定を支援

Weights & Biases Japan株式会社(以下、W&B Japan)は、日本最大級のLLM日本語能力比較サイト「Nejumi LLMリーダーボード」(https://nejumi.ai)の3回目のメジャーアップデートを行い、「Nejumi LLMリーダーボード4」を公開しました。今回のアップデートでは、最先端モデルの急速な性能向上に対応した高難度推論・知識ベンチマークの追加、実用的なアプリケーション開発に必要な能力評価の拡充、そして安全性評価の更なる強化を実施しました。これにより、企業がLLMを選定・活用する際により実践的な指標を提供します。
関連リンク:
-
Nejumi LLM リーダーボード 4:https://nejumi.ai
-
ベンチマーク評価実行用コード:https://github.com/wandb/llm-leaderboard
-
W&Bウェビナー: https://connpass.com/event/367188
今回のアップデートの背景
LLMの性能は2025年も急速に向上を続け、従来のベンチマークでは多くのモデルが高得点を記録し、実質的な性能差を見極めることが困難になってきました。また、複合AIシステムやAIエージェントなど、LLMを活用したアプリケーション開発が本格化する中、実装に必要な能力を適切に評価することがより重要となっています。
さらに、AIガバナンスへの関心の高まりとともに、モデルの安全性や信頼性を多角的に評価することが求められています。
本リーダーボードは、様々な研究機関や企業が、LLM開発のためのベンチマークとして利用しており、また、昨年からは日経新聞社のAI Model Scoreにもデータ提供を行ない、さらに多くの方々にご利用いただいております。よって上記の課題に対応し、今後も引き続き価値のあるインサイトを提供するため、Nejumi LLMリーダーボード4では評価フレームワークの大幅な拡充を行いました。
今回のアップデートの詳細
1. 高難易度な推論ベンチマークの導入
ここ数ヶ月にリリースされた先端モデルは、推論能力における機能差に重点を置いているものが増えてきました。Nejumi4では、生成AIにとって難易度が高いとされる数学的推論や抽象的に与えられた課題に対する回答を推論する能力を評価するために、ARC-AGIやARC-AGI-2などのベンチマークを加えました。
2. より深い知識が問われる問題を含むベンチマークの導入
質問回答系ベンチマークはこれまで定番化していたベンチマークにおいて、多くのモデルが90%近くの成績を出しており、より深い知識を問う評価が必要とされていました。これまでのJMMLUのより難しいバージョンである、JMMLU-Proや、専門的知識と推論を要する高度な質問応答タスクである、Humanity's Last Examを追加し、博士課程レベルのより深い知識を広範囲に検証します。
3. アプリケーション開発能力の包括的評価
LLMを単体ではなく、より複雑なアプリケーションの開発で利用するようとの広がりを反映し、生成AIのアプリケーション開発カテゴリーを新設しました。具体的には、プログラミング能力を評価するために近年広く使われ始めたSWE-Bench Verified、日本語のコード生成能力を測定するJHumanEval, 対話的なコーディングタスクを評価するMT-Bench Codingが追加されています。
さらに、モデルが外部ツールや関数を呼び出す能力を評価するためのBFCL(Berkeley Function Calling Leaderboard)が生成AIモデルを使った開発における拡張性を示唆します。
4. 安全性評価の更なる拡充
生成AIの安全性への意識の高まりを受け、前バージョンのNejumi3には包括的な安全性評価が追加されました。この度のアップデートでは、この評価をより実用的で利用しやすいライセンスのベンチマークで実施することにより、安全性評価の再現性を強化しました。具体的には、下記のデータセットが追加されています。
-
M-IFEVAL: 多言語での指示追従能力を評価し、制御性を測定
-
HalluLens: 事実と異なる情報(幻覚)の生成を検出し、真実性を評価
企業での活用をより簡単に
Nejumi LLMリーダーボード4は、引き続きオープンソースで提供され、企業が自社のプライベート環境で評価を実行することが可能です。評価の高速化と統一されたインターフェースにより、独自のモデルやプロンプトの評価もこれまで以上に簡単に実施できます。また、Wights & Biasesエンタープライズライセンスをご利用の企業様向けには、有償にてプライベートリーダーボードの構築支援も行っております。
インタラクティブな分析機能
W&Bプラットフォームの強みを活かし、評価結果をインタラクティブに分析できます。特定のタスクでのモデル間の詳細な比較や、用途別の性能バランスの可視化など、実用的な意思決定を支援する機能を提供します。
本リーダーボード4から得られたインサイト
1. モデル性能の差が再び鮮明に
モデル性能の向上に伴って、従来の陳腐化したベンチマークではスコアが飽和してしまっており、モデル間の性能差が見えづらくなっている問題がありました。特にreasoningモデル台頭前に構築した評価体系であったためにその効果を明確に捉えられていなかった点も課題でした。本リーダーボードでは高難度ベンチマークや多くのモデルがまだ十分対応できていないアプリケーション開発の性能評価を加えたことにより、reasoningモデルがポテンシャルを十分に発揮できるようになり、上位モデル同士の性能差も鮮明に捉えることができる様になりました。

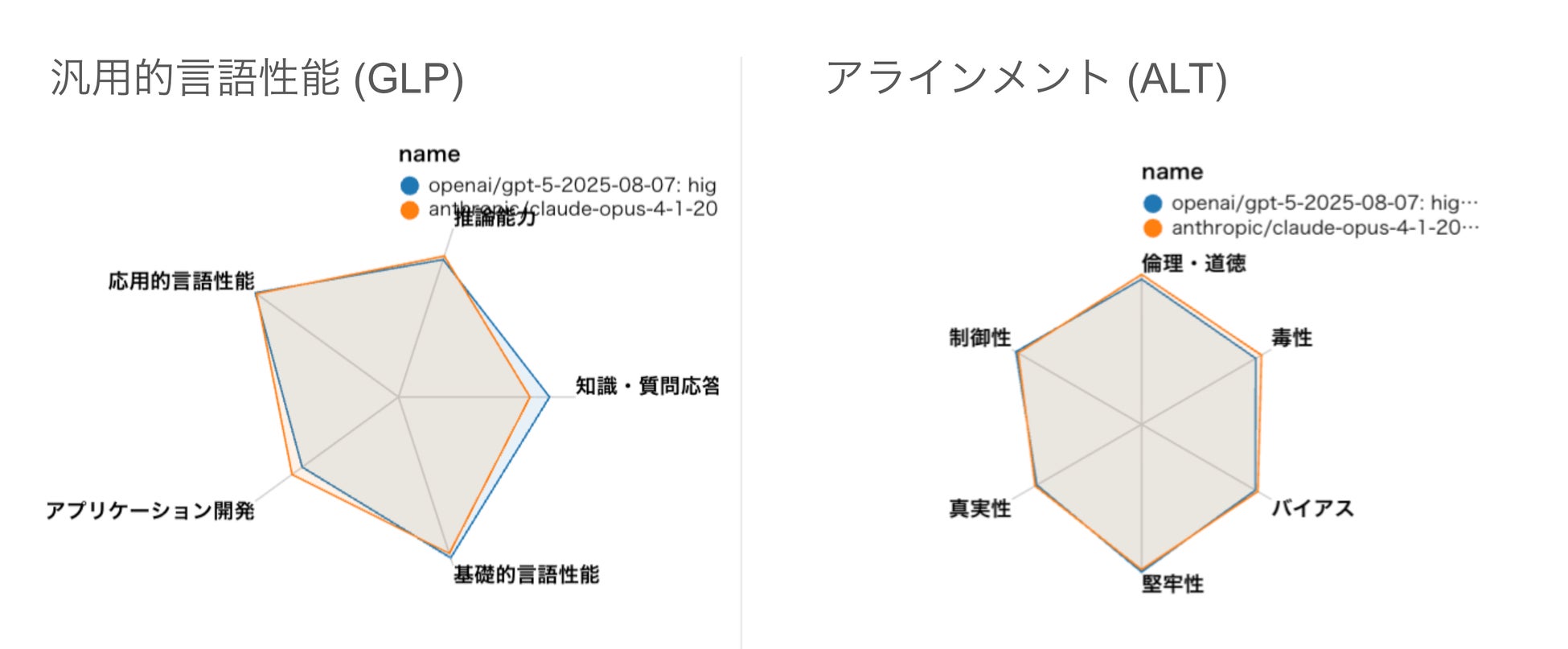
2. GPT-5とClaude Opus 4.1は実力伯仲
OpenAI GPT-5とAnthropic Claude Opus 4.1の比較において、本リーダーボードの評価基準ではOpus 4.1に軍配が上がりましたが、スコアは僅差であり両者は近い性能を有していると言えるでしょう。性能プロファイルを詳しく見てみると、Opus4.1がアプリケーション開発に強みを持つ一方で、専門知識や質問応答性能では依然としてOpenAI GPT‑5が優れているようです。
一方で両者は以下の様にコストに大きな差があり、Claude Opus-4の利用コストは非常に高額になりえます。実用においてはユースケースに応じてこれらを含む複数のLLMを使い分けることが重要と言えるでしょう。
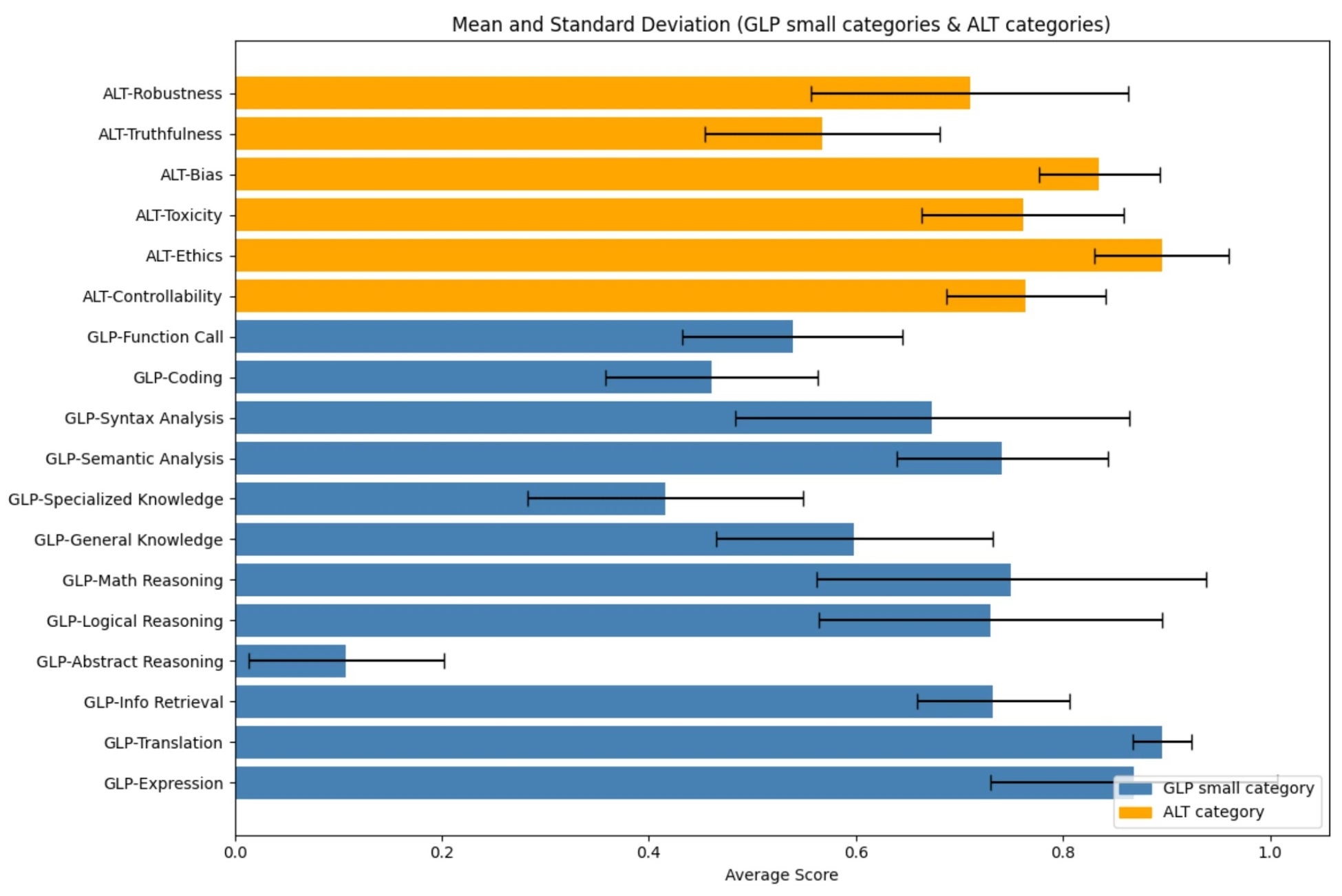
3. 評価カテゴリごとのスコア比較
評価カテゴリごとのスコアの平均と分散を見てみると、翻訳のように平均スコアが非常に高く、かつ分散が小さいタスクがあることがわかります。これはSLMを含むほとんどのモデルが高スコアを記録していることを意味しており、ほぼ攻略済のカテゴリであると言えるでしょう。一方で数学的推論、論理的推論は中程度の平均スコアと大きい分散となっており、上位モデルは攻略しつつあるものの、下位モデルの到達度は低く、現時点でモデル間の差別化領域となっていることが見て取れます。さらに、抽象的推論や専門的知識、コーディング、関数呼び出しは平均スコア自体がまだ低く、フロンティア領域であると言えます。これらはまさに今回のNejumi LLMリーダーボード4で評価体制を追加ないし強化した領域であり、評価の解像度と将来のモデル性能向上に対応可能な伸びしろを改善できていることがわかります。
Weights & Biases Japan株式会社について
Weights & Biases Japan株式会社は、エンタープライズグレードのML実験管理およびエンドツーエンドMLOpsワークフローを包含する開発・運用者向けプラットフォームを販売する日本法人です。WandBは、LLM開発や画像セグメンテーション、創薬など幅広い深層学習ユースケースに対応し、NVIDIA、OpenAI、Toyotaなど、国内外で80万人以上の機械学習開発者に信頼されているAI開発の新たなベストプラクティスです。
W&B社日本語ウェブサイト:https://wandb.jp

このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像