Qlean Dataset、「日本語・3話者・話者分離・日常会話音声コーパスデータセット」を提供開始
〜GENIAC採択企業のVisual Bank、自然対話AI・音声認識・生成AI基盤開発を支援〜

Visual Bank株式会社(東京都港区、代表取締役CEO 永井真之、以下「Visual Bank」)は、傘下の株式会社アマナイメージズを通じて展開するAI学習用データソリューション『Qlean Dataset*(キュリンデータセット)』において、『日本語・3話者・話者分離・日常会話音声コーパスデータセット』の提供を開始しました。
本データセットは、日本語話者3名(男性客・女性客・女性店員)によるカフェでの自然な会話を収録した実環境音声データです。発話を話者ごとに分離した4パターンの音声ファイルを収録しており、音声認識(ASR)や話者分離AI、さらには音声入力を含む生成AI基盤(マルチモーダルAI・音声LLMなど)の学習・検証データとして幅広くご利用いただけます。
自然な応答・発話の重なり・環境音を含む構成のため、音声認識や対話生成AIの精度検証、接客AI・教育支援AI・会話型LLMなどの実環境学習にも適しています。
*Qlean Dataset(キュリンデータセット):https://qleandataset.visual-bank.co.jp/
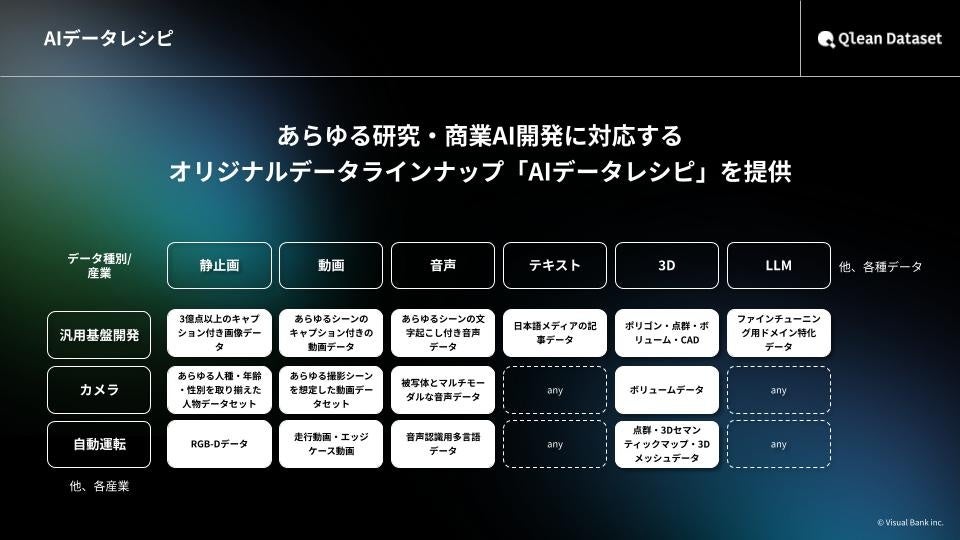
『Qlean Dateset(キュリンデータセット)』の「AIデータレシピ」について
『AIデータレシピ*』は、Qlean Datasetが提供する商用利用可能な機械学習用データセットラインナップです。
用途や目的に応じて、すぐに使えるデータ素材を柔軟に組み合わせられる構成が特長で、個別の要件に合わせた構成変更や拡張にも対応しています。
また、株式会社千葉ロッテマリーンズや株式会社東洋経済新報社をはじめとするデータパートナーとの協業、および国内外のネットワークを通じて、業界特化や最新トレンドに即したデータニーズへの対応を進めています。
Qlean Datasetは、AI開発現場でのデータ収集・整備にかかる負荷を大幅に軽減し、権利クリアで法的リスクのないAI開発環境の実現に貢献します。
*AIデータレシピ:https://qleandataset.visual-bank.co.jp/lineup
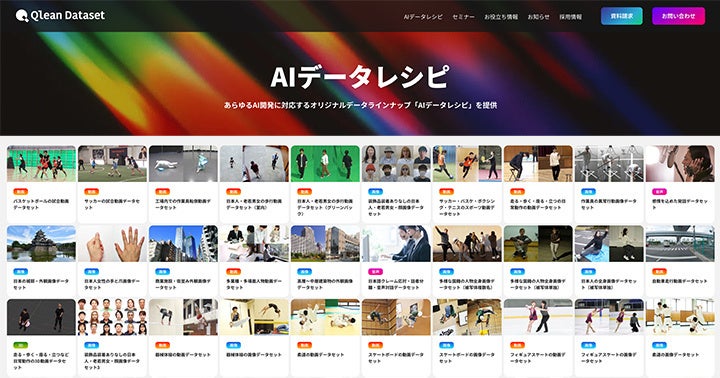


今回提供を開始する「日本語・3話者・話者分離・日常会話音声コーパスデータセット」の概要
-
データ種別:音声
-
被写体属性:日本人、男性客1名、女性客1名、女性店員1名
-
データ形式:音声データ:wav
-
備考
[収録時間] 1音声7分ほど
[対象のシーン] 日常会話やカフェでの注文シーンなどを収録
[話者分離内訳]男性客、女性客、女性店員と全員の会話音声の4パターン
-
サンプル詳細URL:https://qleandataset.visual-bank.co.jp/lineup/pn-032
「日本語・3話者・話者分離・日常会話音声コーパスデータセット」のユースケースイメージ
-
音声認識・話者分離モデルの精度向上
カフェでの3話者による実環境対話を収録し、発話の重なり・ノイズ・イントネーション差を含むデータ構造になっています。話者分離ASRや音源定位、マルチスピーカー音声認識などのモデル検証・最適化に活用できます。
-
日本語対話AIの自然会話トレーニング
依頼・確認・応答といった自然な会話フローを含み、日常的な口調・間合いを学習できるため、カスタマーサポートAIや店舗接客チャットボット、コンシェルジュAIなどの会話生成モデルの訓練に適しています。
-
感情理解・発話特徴量分析AIの開発
店員の丁寧語や顧客の感情変化など、発話トーンや声質の違いを解析できる構成。音声感情認識・パラ言語解析・音響特徴量抽出など、ヒューマンセンタードAI分野での応用が期待されます。
-
日本語教育・コミュニケーショントレーニングAI
自然な日本語会話データとして、外国人向けの日本語教育AIや発音学習アプリ、接客トレーニング教材などにも活用可能。文化的文脈を含む“リアルな会話例”として教育現場からも需要があります。
-
LLM/マルチモーダルAIの音声理解強化
日本語LLMや音声ベースのマルチモーダルモデルにおいて、音声→テキスト変換後の会話構造理解を高めるデータとして利用できます。音声対話LLMのベンチマークデータにも適しています。
『Qlean Dataset』の提供するデータセットの特徴
-
研究開発、商用利用に対応
Qlean Datasetの提供するデータセットは、データ取得およびAI開発への利用に関する同意書を「すべての被写体」から取得しており、各国のプライバシーポリシー等にも対応しているため安心して研究・商用利用いただくことが可能です。
-
「AIデータレシピ」からデータセットを提供するため、スピーディーかつROIを最大化
AIデータレシピというQlean Dataset独自の提供形態を取ることにより、初期投資を抑えたデータ調達を行っていただくことが可能です。
-
「AIデータレシピ」のラインナップにないデータセットは、個別要件に従った作成・構築も可能
独自性の高いデータについても『Qlean Dataset』のケイパビリティを活用し、個別最適化された要件のデータセットをご提供可能です。
Qlean Dataset お問い合わせフォーム:https://qleandataset.visual-bank.co.jp/contact
Qlean Dataset サービスサイトURL:https://qleandataset.visual-bank.co.jp/
Visual Bank株式会社
AI開発力を最大化する次世代型データインフラを構築・提供するスタートアップ企業として、「あらゆるデータの可能性を解き放つ」をミッションに掲げ事業活動を展開。漫画家の「もっと描きたい!」をサポートするAI補助ツールを提供する『THE PEN』の他、AI学習用データセット開発サービス『Qlean Dataset(キュリンデータセット)』を提供する株式会社アマナイメージズを100%子会社に持つ。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択され、社会実装に向けた取り組みを加速させています。
代表取締役CEO:永井 真之
所在地:〒107-0062 東京都港区南青山7-1-7C-Cube南青山ビル6F
Visual Bank企業URL:https://visual-bank.co.jp/
アマナイメージズ企業URL: https://amanaimages.com/about/
【Translation】
Japanese Three-Speaker Speaker-Separated Daily Conversation Corpus Released for Conversational AI
Multi-speaker Japanese audio dataset for ASR, dialogue understanding, and voice-based LLM training

Visual Bank Inc. (Tokyo, Japan; CEO Saneyuki Nagai) has announced the release of the “Japanese Three-Speaker Speaker-Separated Daily Conversation Audio Corpus” through its AI-training-data solution, Qlean Dataset, developed under its subsidiary Amana Images Inc.
This dataset contains real-world Japanese speech recordings of natural conversations among three speakers — a male customer, a female customer, and a female store clerk — in a café setting.
It includes four types of audio files, each featuring speaker-separated tracks as well as a mixed version, making it widely applicable for Automatic Speech Recognition (ASR), speaker separation AI, and multimodal or voice-based generative AI foundations, such as audio-integrated LLMs.
Because the recordings include natural responses, overlapping speech, and ambient sounds, the dataset is ideal for evaluating ASR and dialogue generation accuracy, and for training customer-service AI, educational support AI, and conversational LLMs in realistic environments.
▶ About Qlean Dataset: https://qleandataset.visual-bank.co.jp/en
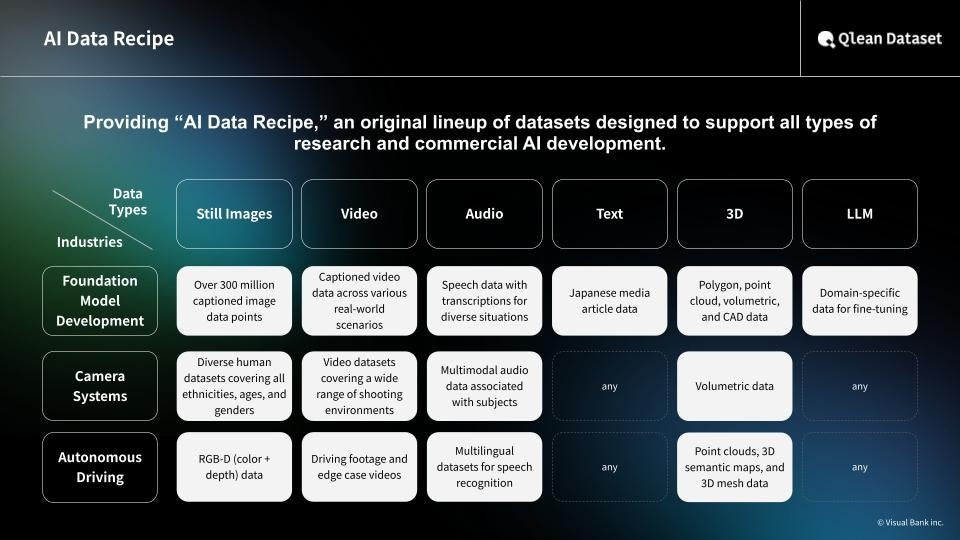
About the “AI Data Recipe” of Qlean Dataset
The "AI Data Recipe" within Qlean Dataset represent its commercially available lineup of original datasets.
They are designed for flexible combination based on usage, accuracy, and delivery requirements, and include both annotated and non-annotated data. Each dataset can be customized or expanded to meet specific needs.
Through partnerships with organizations such as Chiba Lotte Marines and Toyo Keizai Inc., as well as domestic and international networks and new recording projects, Qlean Dataset continues to expand its lineup.
This approach significantly reduces the workload required for data collection and preparation in AI development and accelerates project execution.
▶ AI Data Recipe: https://qleandataset.visual-bank.co.jp/en/lineup


Overview of the Newly Released Dataset
-
Data type: Audio
-
Subjects: Japanese nationals — one male customer, one female customer, one female store clerk
-
Format: WAV audio files
-
Notes:
– Recorded duration: approximately 7 minutes per audio file
– Scene: Everyday conversation and café order scenario
– Speaker-separation breakdown: male customer, female customer, female store clerk, and a full mixed version of all three speaking together -
Audio Rate:48kHz / 16-bit
-
Sample details URL: https://qleandataset.visual-bank.co.jp/en/lineup/pn-032
Use Case Examples of the Dataset
-
Speech recognition and speaker separation model improvement
By recording actual café-scene dialogue with three speakers, including speech overlaps, ambient noise, and intonation differences, the dataset can be effectively applied to verify and optimise models for speaker-separated ASR, source localisation, and multi-speaker speech recognition. -
Natural Japanese conversational AI training
Because it includes natural conversation flows such as requests, confirmations and responses in everyday speech style and timing, the dataset supports training of chat-bots and concierge-AIs in customer-service and retail settings, as well as conversational generation models for Japanese. -
Development of emotion recognition and vocal-feature-analysis AI
The dataset allows analysis of differences in speech tone — for example, the clerk’s polite register or shifts in customer emotion — making it suitable for speech-emotion recognition, paralinguistic analysis, and acoustic-feature extraction research in human-centred AI domains. -
Japanese language education and communication-training AI
As a collection of natural Japanese conversational data, the corpus is also valuable for Japanese-language learning AI for non-native speakers, pronunciation-practice applications, and customer-service training materials — recognised as real-world conversation examples with cultural context. -
Strengthening audio understanding in LLMs / multimodal AI
In Japanese LLMs and voice-based multimodal models, the dataset supports improved conversation-structure understanding after audio-to-text conversion, and can serve as benchmark data for voice-dialogue LLMs.
Features of Qlean Dataset
All datasets are rights-cleared and commercially usable, collected with full participant consent and international privacy compliance.
Delivered via flexible “Data Recipe” for rapid deployment and customizable dataset creation.
Contact form: https://qleandataset.visual-bank.co.jp/en/contact
Service site: https://qleandataset.visual-bank.co.jp/en
About Visual Bank Inc.
Visual Bank Inc. is a next-generation data infrastructure company committed to “unleashing the potential of all data.”
The company operates THE PEN, an AI-powered assistance tool for manga artists, and wholly owns Amana Images Inc., which provides the AI training data service Qlean Dataset.
Visual Bank has been recognized in national R&D programs and continues to advance initiatives toward real-world AI implementation.
CEO: Saneyuki Nagai
Address: C-Cube Minami Aoyama Bldg. 6F, 7-1-7 Minami Aoyama, Minato-ku, Tokyo 107-0062
Corporate website: https://visual-bank.co.jp/en/
Amana Images overview: https://qleandataset.visual-bank.co.jp/en/company-overview
このプレスリリースには、メディア関係者向けの情報があります
メディアユーザー登録を行うと、企業担当者の連絡先や、イベント・記者会見の情報など様々な特記情報を閲覧できます。※内容はプレスリリースにより異なります。
すべての画像